 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of Reinforcement Learning in Quantitative Finance
Aug 20, 2024



Reinforcement Learning (RL) has experienced significant advancement over the past decade, prompting a growing interest in applications within finance. This survey critically evaluates 167 publications, exploring diverse RL applications and frameworks in finance. Financial markets, marked by their complexity, multi-agent nature, information asymmetry, and inherent randomness, serve as an intriguing test-bed for RL. Traditional finance offers certain solutions, and RL advances these with a more dynamic approach, incorporating machine learning methods, including transfer learning, meta-learning, and multi-agent solutions. This survey dissects key RL components through the lens of Quantitative Finance. We uncover emerging themes, propose areas for future research, and critique the strengths and weaknesses of existing methods.
From Stem to Stern: Contestability Along AI Value Chains
Aug 02, 2024
This workshop will grow and consolidate a community of interdisciplinary CSCW researchers focusing on the topic of contestable AI. As an outcome of the workshop, we will synthesize the most pressing opportunities and challenges for contestability along AI value chains in the form of a research roadmap. This roadmap will help shape and inspire imminent work in this field. Considering the length and depth of AI value chains, it will especially spur discussions around the contestability of AI systems along various sites of such chains. The workshop will serve as a platform for dialogue and demonstrations of concrete, successful, and unsuccessful examples of AI systems that (could or should) have been contested, to identify requirements, obstacles, and opportunities for designing and deploying contestable AI in various contexts. This will be held primarily as an in-person workshop, with some hybrid accommodation. The day will consist of individual presentations and group activities to stimulate ideation and inspire broad reflections on the field of contestable AI. Our aim is to facilitate interdisciplinary dialogue by bringing together researchers, practitioners, and stakeholders to foster the design and deployment of contestable AI.
Revisiting the Modifiable Areal Unit Problem in Deep Traffic Prediction with Visual Analytics
Sep 07, 2020
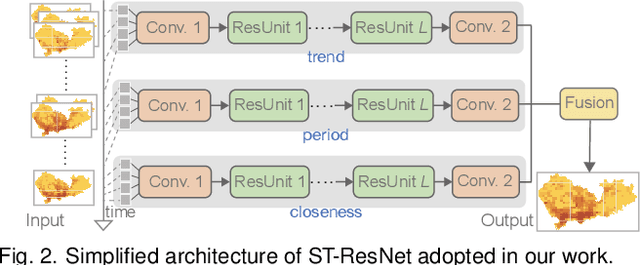
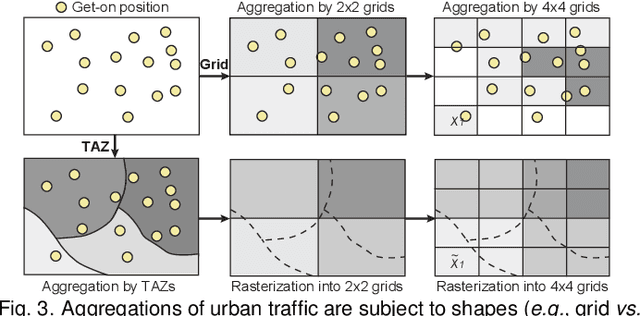
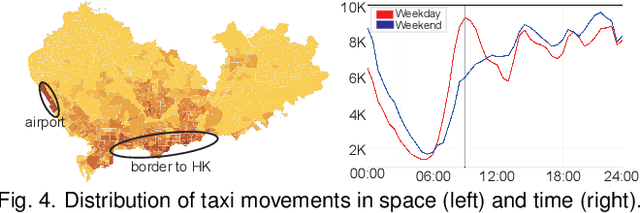
Deep learning methods are being increasingly used for urban traffic prediction where spatiotemporal traffic data is aggregated into sequentially organized matrices that are then fed into convolution-based residual neural networks. However, the widely known modifiable areal unit problem within such aggregation processes can lead to perturbations in the network inputs. This issue can significantly destabilize the feature embeddings and the predictions, rendering deep networks much less useful for the experts. This paper approaches this challenge by leveraging unit visualization techniques that enable the investigation of many-to-many relationships between dynamically varied multi-scalar aggregations of urban traffic data and neural network predictions. Through regular exchanges with a domain expert, we design and develop a visual analytics solution that integrates 1) a Bivariate Map equipped with an advanced bivariate colormap to simultaneously depict input traffic and prediction errors across space, 2) a Morans I Scatterplot that provides local indicators of spatial association analysis, and 3) a Multi-scale Attribution View that arranges non-linear dot plots in a tree layout to promote model analysis and comparison across scales. We evaluate our approach through a series of case studies involving a real-world dataset of Shenzhen taxi trips, and through interviews with domain experts. We observe that geographical scale variations have important impact on prediction performances, and interactive visual exploration of dynamically varying inputs and outputs benefit experts in the development of deep traffic prediction models.
Progressive Data Science: Potential and Challenges
Dec 19, 2018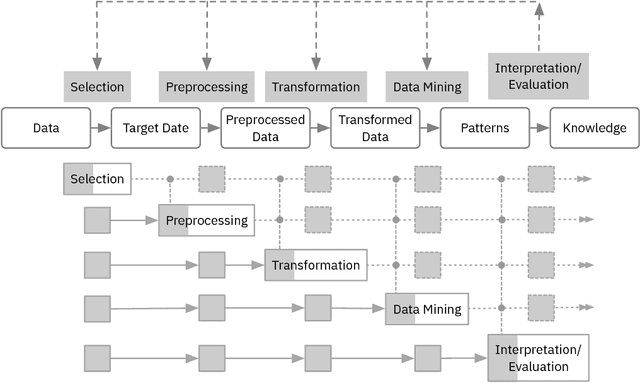
Data science requires time-consuming iterative manual activities. In particular, activities such as data selection, preprocessing, transformation, and mining, highly depend on iterative trial-and-error processes that could be sped up significantly by providing quick feedback on the impact of changes. The idea of progressive data science is to compute the results of changes in a progressive manner, returning a first approximation of results quickly and allow iterative refinements until converging to a final result. Enabling the user to interact with the intermediate results allows an early detection of erroneous or suboptimal choices, the guided definition of modifications to the pipeline and their quick assessment. In this paper, we discuss the progressiveness challenges arising in different steps of the data science pipeline. We describe how changes in each step of the pipeline impact the subsequent steps and outline why progressive data science will help to make the process more effective. Computing progressive approximations of outcomes resulting from changes creates numerous research challenges, especially if the changes are made in the early steps of the pipeline. We discuss these challenges and outline first steps towards progressiveness, which, we argue, will ultimately help to significantly speed-up the overall data science process.