 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Anomaly-guided Ego-graph Diffusion Model for Inductive Graph Anomaly Detection
Feb 05, 2026Graph anomaly detection (GAD) is crucial in applications like fraud detection and cybersecurity. Despite recent advancements using graph neural networks (GNNs), two major challenges persist. At the model level, most methods adopt a transductive learning paradigm, which assumes static graph structures, making them unsuitable for dynamic, evolving networks. At the data level, the extreme class imbalance, where anomalous nodes are rare, leads to biased models that fail to generalize to unseen anomalies. These challenges are interdependent: static transductive frameworks limit effective data augmentation, while imbalance exacerbates model distortion in inductive learning settings. To address these challenges, we propose a novel data-centric framework that integrates dynamic graph modeling with balanced anomaly synthesis. Our framework features: (1) a discrete ego-graph diffusion model, which captures the local topology of anomalies to generate ego-graphs aligned with anomalous structural distribution, and (2) a curriculum anomaly augmentation mechanism, which dynamically adjusts synthetic data generation during training, focusing on underrepresented anomaly patterns to improve detection and generalization. Experiments on five datasets demonstrate that the effectiveness of our framework.
T-Retriever: Tree-based Hierarchical Retrieval Augmented Generation for Textual Graphs
Jan 08, 2026Retrieval-Augmented Generation (RAG) has significantly enhanced Large Language Models' ability to access external knowledge, yet current graph-based RAG approaches face two critical limitations in managing hierarchical information: they impose rigid layer-specific compression quotas that damage local graph structures, and they prioritize topological structure while neglecting semantic content. We introduce T-Retriever, a novel framework that reformulates attributed graph retrieval as tree-based retrieval using a semantic and structure-guided encoding tree. Our approach features two key innovations: (1) Adaptive Compression Encoding, which replaces artificial compression quotas with a global optimization strategy that preserves the graph's natural hierarchical organization, and (2) Semantic-Structural Entropy ($S^2$-Entropy), which jointly optimizes for both structural cohesion and semantic consistency when creating hierarchical partitions. Experiments across diverse graph reasoning benchmarks demonstrate that T-Retriever significantly outperforms state-of-the-art RAG methods, providing more coherent and contextually relevant responses to complex queries.
Self-Supervised Continuous Colormap Recovery from a 2D Scalar Field Visualization without a Legend
Jul 28, 2025Recovering a continuous colormap from a single 2D scalar field visualization can be quite challenging, especially in the absence of a corresponding color legend. In this paper, we propose a novel colormap recovery approach that extracts the colormap from a color-encoded 2D scalar field visualization by simultaneously predicting the colormap and underlying data using a decoupling-and-reconstruction strategy. Our approach first separates the input visualization into colormap and data using a decoupling module, then reconstructs the visualization with a differentiable color-mapping module. To guide this process, we design a reconstruction loss between the input and reconstructed visualizations, which serves both as a constraint to ensure strong correlation between colormap and data during training, and as a self-supervised optimizer for fine-tuning the predicted colormap of unseen visualizations during inferencing. To ensure smoothness and correct color ordering in the extracted colormap, we introduce a compact colormap representation using cubic B-spline curves and an associated color order loss. We evaluate our method quantitatively and qualitatively on a synthetic dataset and a collection of real-world visualizations from the VIS30K dataset. Additionally, we demonstrate its utility in two prototype applications -- colormap adjustment and colormap transfer -- and explore its generalization to visualizations with color legends and ones encoded using discrete color palettes.
SPAC-Net: Rethinking Point Cloud Completion with Structural Prior
Nov 22, 2024Point cloud completion aims to infer a complete shape from its partial observation. Many approaches utilize a pure encoderdecoder paradigm in which complete shape can be directly predicted by shape priors learned from partial scans, however, these methods suffer from the loss of details inevitably due to the feature abstraction issues. In this paper, we propose a novel framework,termed SPAC-Net, that aims to rethink the completion task under the guidance of a new structural prior, we call it interface. Specifically, our method first investigates Marginal Detector (MAD) module to localize the interface, defined as the intersection between the known observation and the missing parts. Based on the interface, our method predicts the coarse shape by learning the displacement from the points in interface move to their corresponding position in missing parts. Furthermore, we devise an additional Structure Supplement(SSP) module before the upsampling stage to enhance the structural details of the coarse shape, enabling the upsampling module to focus more on the upsampling task. Extensive experiments have been conducted on several challenging benchmarks, and the results demonstrate that our method outperforms existing state-of-the-art approaches.
Evaluating Task-based Effectiveness of MLLMs on Charts
May 11, 2024In this paper, we explore a forward-thinking question: Is GPT-4V effective at low-level data analysis tasks on charts? To this end, we first curate a large-scale dataset, named ChartInsights, consisting of 89,388 quartets (chart, task, question, answer) and covering 10 widely-used low-level data analysis tasks on 7 chart types. Firstly, we conduct systematic evaluations to understand the capabilities and limitations of 18 advanced MLLMs, which include 12 open-source models and 6 closed-source models. Starting with a standard textual prompt approach, the average accuracy rate across the 18 MLLMs is 36.17%. Among all the models, GPT-4V achieves the highest accuracy, reaching 56.13%. To understand the limitations of multimodal large models in low-level data analysis tasks, we have designed various experiments to conduct an in-depth test of capabilities of GPT-4V. We further investigate how visual modifications to charts, such as altering visual elements (e.g. changing color schemes) and introducing perturbations (e.g. adding image noise), affect performance of GPT-4V. Secondly, we present 12 experimental findings. These findings suggest potential of GPT-4V to revolutionize interaction with charts and uncover the gap between human analytic needs and capabilities of GPT-4V. Thirdly, we propose a novel textual prompt strategy, named Chain-of-Charts, tailored for low-level analysis tasks, which boosts model performance by 24.36%, resulting in an accuracy of 80.49%. Furthermore, by incorporating a visual prompt strategy that directs attention of GPT-4V to question-relevant visual elements, we further improve accuracy to 83.83%. Our study not only sheds light on the capabilities and limitations of GPT-4V in low-level data analysis tasks but also offers valuable insights for future research.
Mystique: Deconstructing SVG Charts for Layout Reuse
Aug 09, 2023



To facilitate the reuse of existing charts, previous research has examined how to obtain a semantic understanding of a chart by deconstructing its visual representation into reusable components, such as encodings. However, existing deconstruction approaches primarily focus on chart styles, handling only basic layouts. In this paper, we investigate how to deconstruct chart layouts, focusing on rectangle-based ones, as they cover not only 17 chart types but also advanced layouts (e.g., small multiples, nested layouts). We develop an interactive tool, called Mystique, adopting a mixed-initiative approach to extract the axes and legend, and deconstruct a chart's layout into four semantic components: mark groups, spatial relationships, data encodings, and graphical constraints. Mystique employs a wizard interface that guides chart authors through a series of steps to specify how the deconstructed components map to their own data. On 150 rectangle-based SVG charts, Mystique achieves above 85% accuracy for axis and legend extraction and 96% accuracy for layout deconstruction. In a chart reproduction study, participants could easily reuse existing charts on new datasets. We discuss the current limitations of Mystique and future research directions.
An Intelligent Model for Solving Manpower Scheduling Problems
May 07, 2021


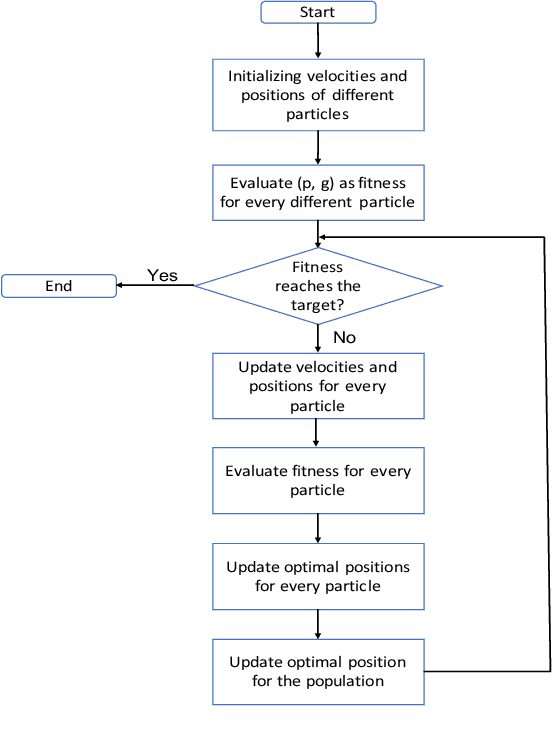
The manpower scheduling problem is a critical research field in the resource management area. Based on the existing studies on scheduling problem solutions, this paper transforms the manpower scheduling problem into a combinational optimization problem under multi-constraint conditions from a new perspective. It also uses logical paradigms to build a mathematical model for problem solution and an improved multi-dimensional evolution algorithm for solving the model. Moreover, the constraints discussed in this paper basically cover all the requirements of human resource coordination in modern society and are supported by our experiment results. In the discussion part, we compare our model with other heuristic algorithms or linear programming methods and prove that the model proposed in this paper makes a 25.7% increase in efficiency and a 17% increase in accuracy at most. In addition, to the numerical solution of the manpower scheduling problem, this paper also studies the algorithm for scheduling task list generation and the method of displaying scheduling results. As a result, we not only provide various modifications for the basic algorithm to solve different condition problems but also propose a new algorithm that increases at least 28.91% in time efficiency by comparing with different baseline models.
* none
Scribble-Supervised Semantic Segmentation by Uncertainty Reduction on Neural Representation and Self-Supervision on Neural Eigenspace
Feb 19, 2021

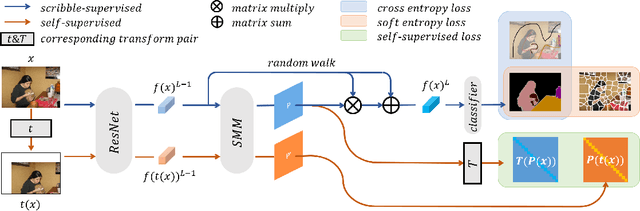
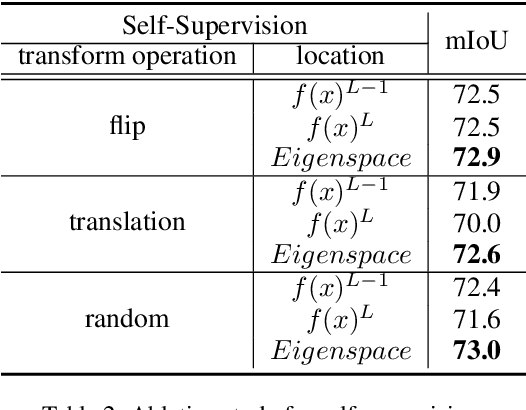
Scribble-supervised semantic segmentation has gained much attention recently for its promising performance without high-quality annotations. Due to the lack of supervision, confident and consistent predictions are usually hard to obtain. Typically, people handle these problems to either adopt an auxiliary task with the well-labeled dataset or incorporate the graphical model with additional requirements on scribble annotations. Instead, this work aims to achieve semantic segmentation by scribble annotations directly without extra information and other limitations. Specifically, we propose holistic operations, including minimizing entropy and a network embedded random walk on neural representation to reduce uncertainty. Given the probabilistic transition matrix of a random walk, we further train the network with self-supervision on its neural eigenspace to impose consistency on predictions between related images. Comprehensive experiments and ablation studies verify the proposed approach, which demonstrates superiority over others; it is even comparable to some full-label supervised ones and works well when scribbles are randomly shrunk or dropped.
Implicit Multidimensional Projection of Local Subspaces
Sep 07, 2020
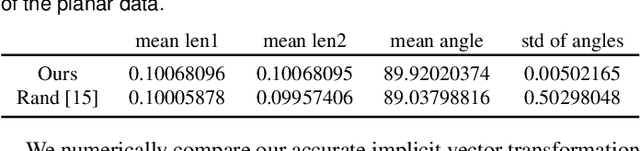

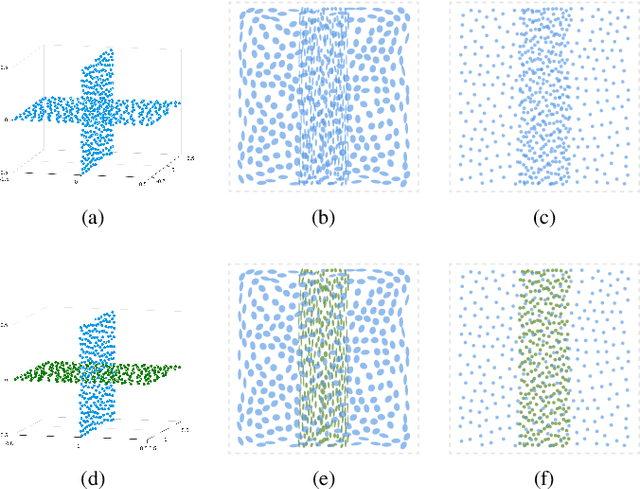
We propose a visualization method to understand the effect of multidimensional projection on local subspaces, using implicit function differentiation. Here, we understand the local subspace as the multidimensional local neighborhood of data points. Existing methods focus on the projection of multidimensional data points, and the neighborhood information is ignored. Our method is able to analyze the shape and directional information of the local subspace to gain more insights into the global structure of the data through the perception of local structures. Local subspaces are fitted by multidimensional ellipses that are spanned by basis vectors. An accurate and efficient vector transformation method is proposed based on analytical differentiation of multidimensional projections formulated as implicit functions. The results are visualized as glyphs and analyzed using a full set of specifically-designed interactions supported in our efficient web-based visualization tool. The usefulness of our method is demonstrated using various multi- and high-dimensional benchmark datasets. Our implicit differentiation vector transformation is evaluated through numerical comparisons; the overall method is evaluated through exploration examples and use cases.
Deep learning Inversion of Seismic Data
Jan 23, 2019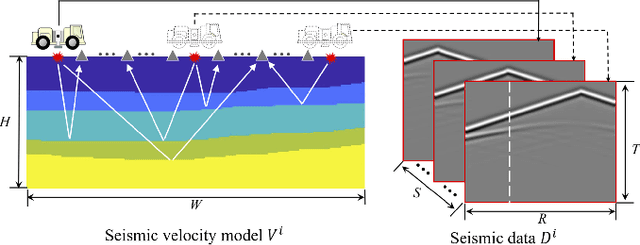
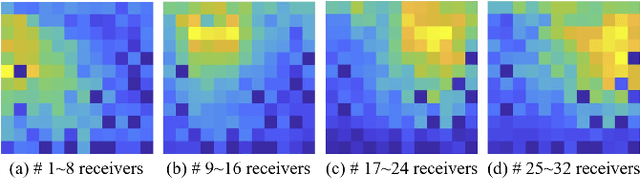
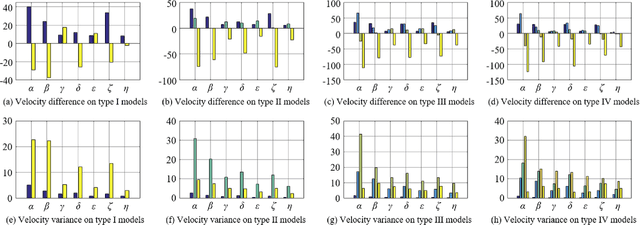

In this paper, we propose a new method to tackle the mapping challenge from time-series data to spatial image in the field of seismic exploration, i.e., reconstructing the velocity model directly from seismic data by deep neural networks (DNNs). The conventional way to address this ill-posed seismic inversion problem is through iterative algorithms, which suffer from poor nonlinear mapping and strong non-uniqueness. Other attempts may either import human intervention errors or underuse seismic data. The challenge for DNNs mainly lies in the weak spatial correspondence, the uncertain reflection-reception relationship between seismic data and velocity model as well as the time-varying property of seismic data. To approach these challenges, we propose an end-to-end Seismic Inversion Networks (SeisInvNet for short) with novel components to make the best use of all seismic data. Specifically, we start with every seismic trace and enhance it with its neighborhood information, its observation setup and global context of its corresponding seismic profile. Then from enhanced seismic traces, the spatially aligned feature maps can be learned and further concatenated to reconstruct velocity model. In general, we let every seismic trace contribute to the reconstruction of the whole velocity model by finding spatial correspondence. The proposed SeisInvNet consistently produces improvements over the baselines and achieves promising performance on our proposed SeisInv dataset according to various evaluation metrics, and the inversion results are more consistent with the target from the aspects of velocity value, subsurface structure and geological interface. In addition to the superior performance, the mechanism is also carefully discussed, and some potential problems are identified for further study.