 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeow-Omni 1: A Multimodal Large Language Model for Feline Ethology
May 09, 2026Deciphering animal intent is a fundamental challenge in computational ethology, largely because of semantic aliasing, the phenomenon where identical external signals (e.g., a cat's purr) correspond to radically different internal states depending on physiological context. Existing Multimodal Large Language Models (MLLMs) are blind to high-frequency biological time-series data, restricting them to superficial behavioural pattern matching rather than genuine latent-state reasoning. To bridge this gap, we introduce Meow-Omni 1, the first open-source, quad-modal MLLM purpose-built for computational ethology. It natively fuses video, audio, and physiological time-series streams with textual reasoning. Through targeted architectural adaptation, we integrate specialized scientific encoders into a unified backbone and formalize intent inference via physiologically grounded cross-modal alignment. Evaluated on MeowBench, a novel, expert-verified quad-modal benchmark, Meow-Omni 1 achieves state-of-the-art intent-recognition accuracy (71.16%), substantially outperforming leading vision-language and omni-modal baselines. We release the complete open-source pipeline including model weights, training framework, and the Meow-10K dataset, to establish a scalable paradigm for inter-species intent understanding and to advance foundation models toward real-world veterinary diagnostics and wildlife conservation.
Visualization of Machine Learning Models through Their Spatial and Temporal Listeners
Mar 29, 2026Model visualization (ModelVis) has emerged as a major research direction, yet existing taxonomies are largely organized by data or tasks, making it difficult to treat models as first-class analysis objects. We present a model-centric two-stage framework that employs abstract listeners to capture spatial and temporal model behaviors, and then connects the translated model behavior data to the classical InfoVis pipeline. To apply the framework at scale, we build a retrieval-augmented human--large language model (LLM) extraction workflow and curate a corpus of 128 VIS/VAST ModelVis papers with 331 coded figures. Our analysis shows a dominant result-centric priority on visualizing model outcomes, quantitative/nominal data type, statistical charts, and performance evaluation. Citation-weighted trends further indicate that less frequent model-mechanism-oriented studies have disproportionately high impact while are less investigated recently. Overall, the framework is a general approach for comparing existing ModelVis systems and guiding possible future designs.
Certified L2-Norm Robustness of 3D Point Cloud Recognition in the Frequency Domain
Nov 10, 2025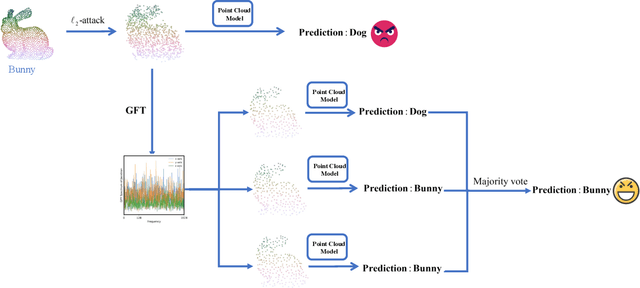
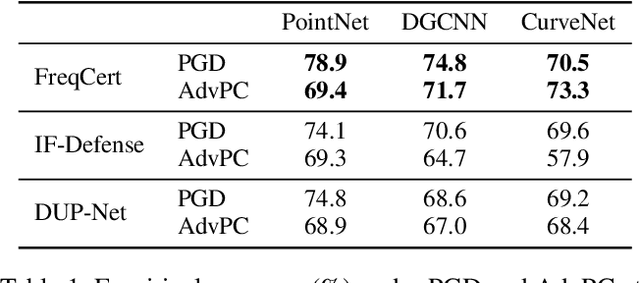

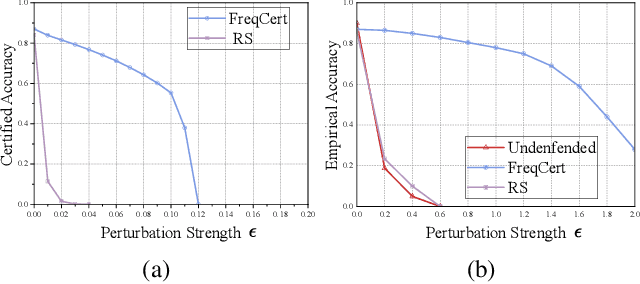
3D point cloud classification is a fundamental task in safety-critical applications such as autonomous driving, robotics, and augmented reality. However, recent studies reveal that point cloud classifiers are vulnerable to structured adversarial perturbations and geometric corruptions, posing risks to their deployment in safety-critical scenarios. Existing certified defenses limit point-wise perturbations but overlook subtle geometric distortions that preserve individual points yet alter the overall structure, potentially leading to misclassification. In this work, we propose FreqCert, a novel certification framework that departs from conventional spatial domain defenses by shifting robustness analysis to the frequency domain, enabling structured certification against global L2-bounded perturbations. FreqCert first transforms the input point cloud via the graph Fourier transform (GFT), then applies structured frequency-aware subsampling to generate multiple sub-point clouds. Each sub-cloud is independently classified by a standard model, and the final prediction is obtained through majority voting, where sub-clouds are constructed based on spectral similarity rather than spatial proximity, making the partitioning more stable under L2 perturbations and better aligned with the object's intrinsic structure. We derive a closed-form lower bound on the certified L2 robustness radius and prove its tightness under minimal and interpretable assumptions, establishing a theoretical foundation for frequency domain certification. Extensive experiments on the ModelNet40 and ScanObjectNN datasets demonstrate that FreqCert consistently achieves higher certified accuracy and empirical accuracy under strong perturbations. Our results suggest that spectral representations provide an effective pathway toward certifiable robustness in 3D point cloud recognition.
Ensemble Visualization With Variational Autoencoder
Sep 16, 2025We present a new method to visualize data ensembles by constructing structured probabilistic representations in latent spaces, i.e., lower-dimensional representations of spatial data features. Our approach transforms the spatial features of an ensemble into a latent space through feature space conversion and unsupervised learning using a variational autoencoder (VAE). The resulting latent spaces follow multivariate standard Gaussian distributions, enabling analytical computation of confidence intervals and density estimation of the probabilistic distribution that generates the data ensemble. Preliminary results on a weather forecasting ensemble demonstrate the effectiveness and versatility of our method.
Attonsecond Streaking Phase Retrieval Via Deep Learning Methods
May 06, 2025Attosecond streaking phase retrieval is essential for resolving electron dynamics on sub-femtosecond time scales yet traditional algorithms rely on iterative minimization and central momentum approximations that degrade accuracy for broadband pulses. In this work phase retrieval is reformulated as a supervised computer-vision problem and four neural architectures are systematically compared. A convolutional network demonstrates strong sensitivity to local streak edges but lacks global context; a vision transformer captures long-range delay-energy correlations at the expense of local inductive bias; a hybrid CNN-ViT model unites local feature extraction and full-graph attention; and a capsule network further enforces spatial pose agreement through dynamic routing. A theoretical analysis introduces local, global and positional sensitivity measures and derives surrogate error bounds that predict the strict ordering $CNN<ViT<Hybrid<Capsule$. Controlled experiments on synthetic streaking spectrograms confirm this hierarchy, with the capsule network achieving the highest retrieval fidelity. Looking forward, embedding the strong-field integral into physics-informed neural networks and exploring photonic hardware implementations promise pathways toward real-time attosecond pulse characterization under demanding experimental conditions.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Visual Analysis of Multi-outcome Causal Graphs
Jul 31, 2024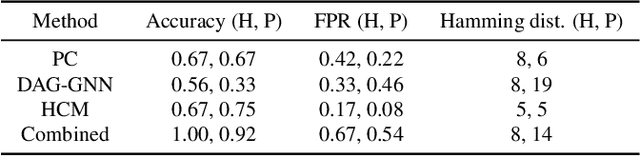


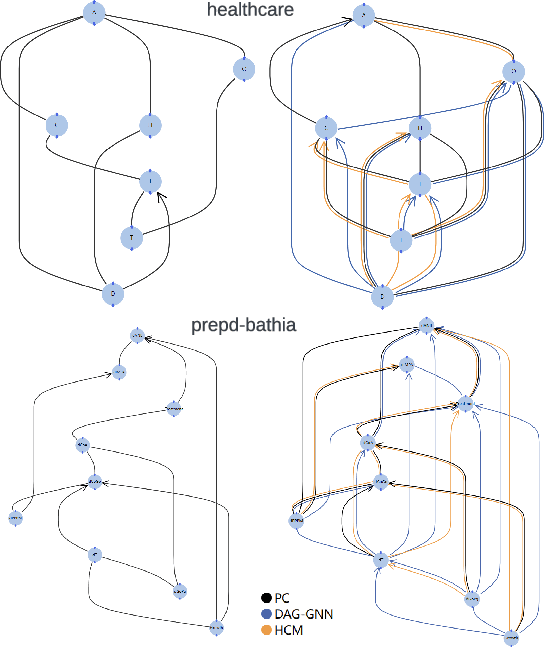
We introduce a visual analysis method for multiple causal graphs with different outcome variables, namely, multi-outcome causal graphs. Multi-outcome causal graphs are important in healthcare for understanding multimorbidity and comorbidity. To support the visual analysis, we collaborated with medical experts to devise two comparative visualization techniques at different stages of the analysis process. First, a progressive visualization method is proposed for comparing multiple state-of-the-art causal discovery algorithms. The method can handle mixed-type datasets comprising both continuous and categorical variables and assist in the creation of a fine-tuned causal graph of a single outcome. Second, a comparative graph layout technique and specialized visual encodings are devised for the quick comparison of multiple causal graphs. In our visual analysis approach, analysts start by building individual causal graphs for each outcome variable, and then, multi-outcome causal graphs are generated and visualized with our comparative technique for analyzing differences and commonalities of these causal graphs. Evaluation includes quantitative measurements on benchmark datasets, a case study with a medical expert, and expert user studies with real-world health research data.
A Plug-and-Play Untrained Neural Network for Full Waveform Inversion in Reconstructing Sound Speed Images of Ultrasound Computed Tomography
Jun 14, 2024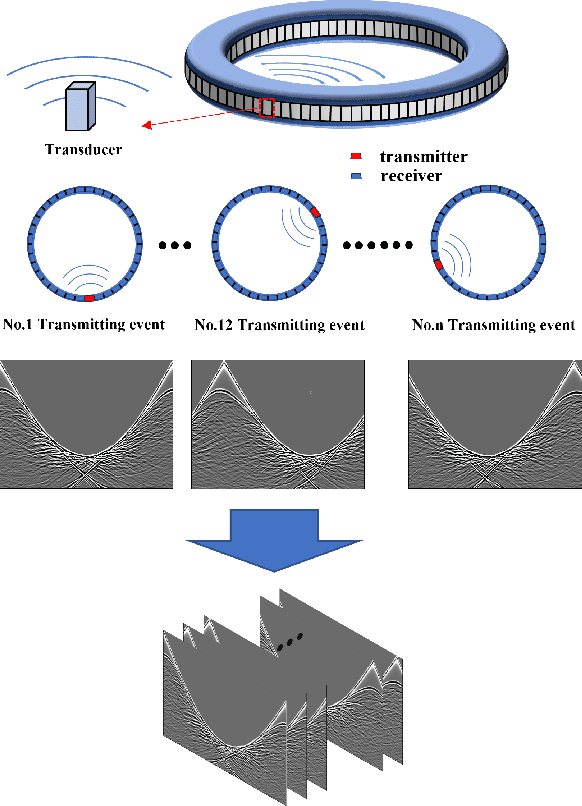
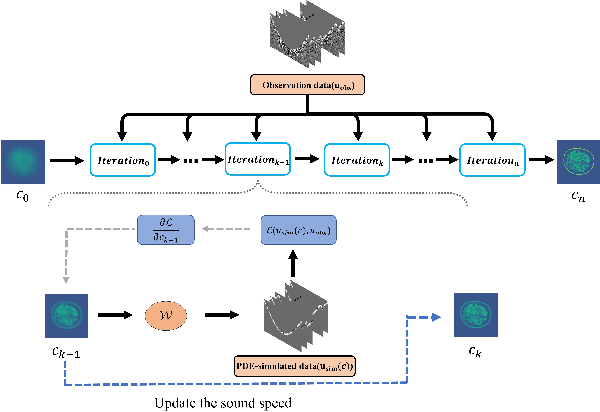
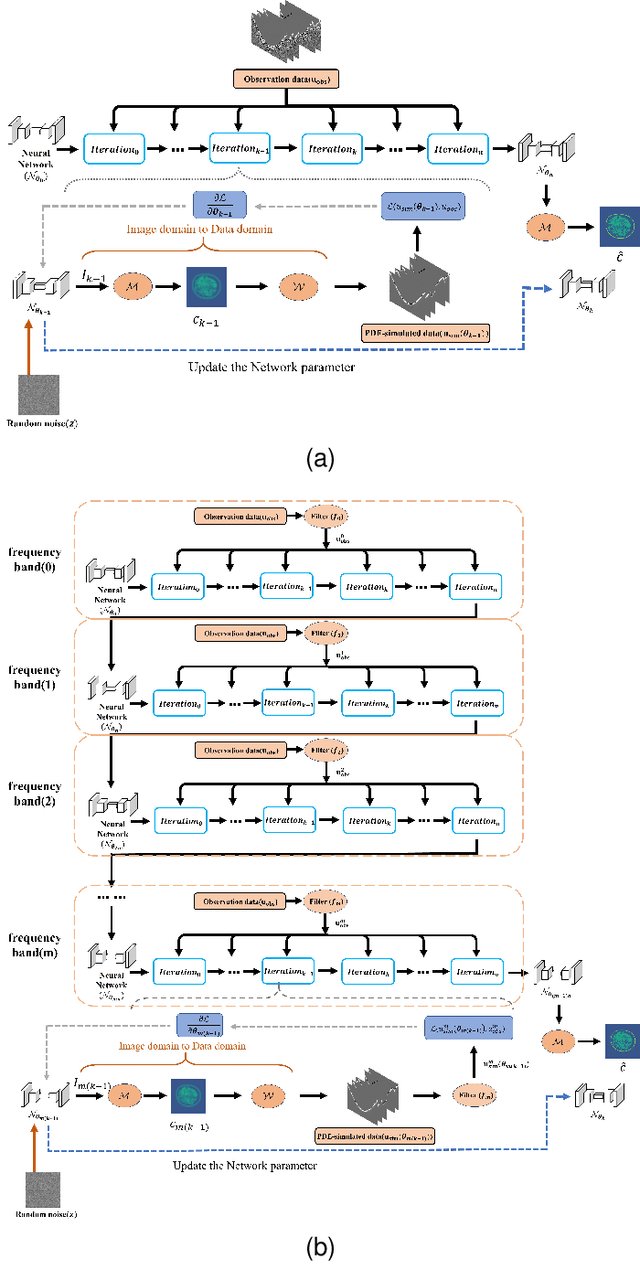
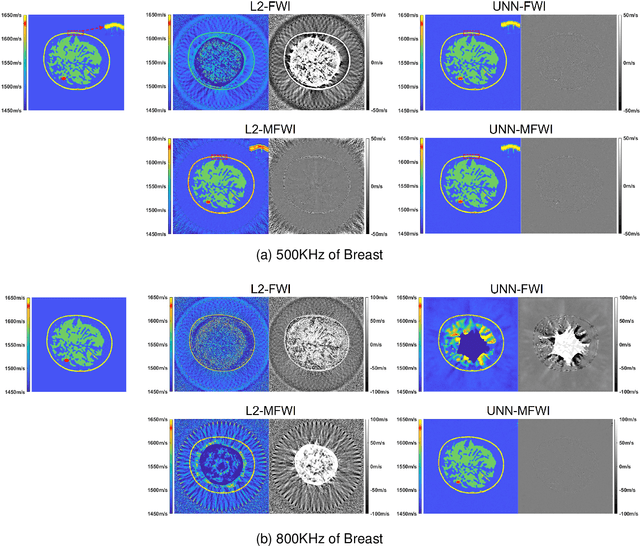
Ultrasound computed tomography (USCT), as an emerging technology, can provide multiple quantitative parametric images of human tissue, such as sound speed and attenuation images, distinguishing it from conventional B-mode (reflection) ultrasound imaging. Full waveform inversion (FWI) is acknowledged as a technique with the greatest potential for reconstructing high-resolution sound speed images in USCT. However, traditional FWI for sound speed image reconstruction suffers from high sensitivity to the initial model caused by its strong non-convex nonlinearity, resulting in poor performance when ultrasound signals are at high frequencies. This limitation significantly restricts the application of FWI in the USCT imaging field. In this paper, we propose an untrained neural network (UNN) that can be integrated into the traditional iteration-based FWI framework as an implicit regularization prior. This integration allows for seamless deployment as a plug-and-play module within existing FWI algorithms or their variants. Notably, the proposed UNN method can be trained in an unsupervised fashion, a vital aspect in medical imaging where ground truth data is often unavailable. Evaluations of the numerical simulation and phantom experiment of the breast demonstrate that the proposed UNN improves the robustness of image reconstruction, reduces image artifacts, and achieves great image contrast. To the best of our knowledge, this study represents the first attempt to propose an implicit UNN for FWI in reconstructing sound speed images for USCT.
Adjacent-level Feature Cross-Fusion with 3D CNN for Remote Sensing Image Change Detection
Feb 10, 2023



Deep learning-based change detection using remote sensing images has received increasing attention in recent years. However, how to effectively extract and fuse the deep features of bi-temporal images to improve the accuracy of change detection is still a challenge. To address that, a novel adjacent-level feature fusion network with 3D convolution (named AFCF3D-Net) is proposed in this article. First, through the inner fusion property of 3D convolution, we design a new feature fusion way that can simultaneously extract and fuse the feature information from bi-temporal images. Then, in order to bridge the semantic gap between low-level features and high-level features, we propose an adjacent-level feature cross-fusion (AFCF) module to aggregate complementary feature information between the adjacent-levels. Furthermore, the densely skip connection strategy is introduced to improve the capability of pixel-wise prediction and compactness of changed objects in the results. Finally, the proposed AFCF3D-Net has been validated on the three challenging remote sensing change detection datasets: Wuhan building dataset (WHU-CD), LEVIR building dataset (LEVIR-CD), and Sun Yat-Sen University (SYSU-CD). The results of quantitative analysis and qualitative comparison demonstrate that the proposed AFCF3D-Net achieves better performance compared to the other state-of-the-art change detection methods.
Advances and Challenges in Multimodal Remote Sensing Image Registration
Feb 07, 2023Over the past few decades, with the rapid development of global aerospace and aerial remote sensing technology, the types of sensors have evolved from the traditional monomodal sensors (e.g., optical sensors) to the new generation of multimodal sensors [e.g., multispectral, hyperspectral, light detection and ranging (LiDAR) and synthetic aperture radar (SAR) sensors]. These advanced devices can dynamically provide various and abundant multimodal remote sensing images with different spatial, temporal, and spectral resolutions according to different application requirements. Since then, it is of great scientific significance to carry out the research of multimodal remote sensing image registration, which is a crucial step for integrating the complementary information among multimodal data and making comprehensive observations and analysis of the Earths surface. In this work, we will present our own contributions to the field of multimodal image registration, summarize the advantages and limitations of existing multimodal image registration methods, and then discuss the remaining challenges and make a forward-looking prospect for the future development of the field.