 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Semantic Segmentation Network Integrating Object-Level Label and Scene-Level Semantic Features for Multimodal Remote Sensing Images
Apr 27, 2026Semantic segmentation of multi-modal remote sensing imagery plays a pivotal role in land use/land cover (LULC) mapping, environmental monitoring, and precision earth observation. Current multi-modal approaches mainly focus on integrating complementary visual modalities, yet neglect the incorporating of non-visual textual data - a rich source of knowledge that can bridge semantic gaps between visual patterns and real-world concepts. To address this limitation, we propose TSMNet, a text supervised multi-modal open vocabulary semantic segmentation network that synergistically integrates textual supervision with visual representation for open-vocabulary semantic segmentation. Unlike conventional multi-modal segmentation frameworks, TSMNet introduces a dual-branch text encoder to extract both scene-level semantic and object-level label information from various textual data, enabling dynamic cross-modal fusion. These text-derived features dynamically interact with visual embeddings through the proposed text-guided visual semantic fusion module, enabling domain-aware feature refinement and human-interpretable decision-making. To verify our method, we innovatively construct two new multi-modal datasets, and carry out extensive experiments to make a comprehensive comparison between the proposed method and other state-of-the-art (SOTA) semantic segmentation models. Results demonstrate that TSMNet achieves superior segmentation accuracy while exhibiting robust generalization capabilities across diverse geographical and sensor-specific scenarios. This work establishes a new paradigm for explainable remote sensing analysis, demonstrating that textual knowledge integration significantly enhances model generalizability. The source code will be available at https://github.com/yeyuanxin110/TSMNet
Masked conditional variational autoencoders for chromosome straightening
Jun 25, 2023



Karyotyping is of importance for detecting chromosomal aberrations in human disease. However, chromosomes easily appear curved in microscopic images, which prevents cytogeneticists from analyzing chromosome types. To address this issue, we propose a framework for chromosome straightening, which comprises a preliminary processing algorithm and a generative model called masked conditional variational autoencoders (MC-VAE). The processing method utilizes patch rearrangement to address the difficulty in erasing low degrees of curvature, providing reasonable preliminary results for the MC-VAE. The MC-VAE further straightens the results by leveraging chromosome patches conditioned on their curvatures to learn the mapping between banding patterns and conditions. During model training, we apply a masking strategy with a high masking ratio to train the MC-VAE with eliminated redundancy. This yields a non-trivial reconstruction task, allowing the model to effectively preserve chromosome banding patterns and structure details in the reconstructed results. Extensive experiments on three public datasets with two stain styles show that our framework surpasses the performance of state-of-the-art methods in retaining banding patterns and structure details. Compared to using real-world bent chromosomes, the use of high-quality straightened chromosomes generated by our proposed method can improve the performance of various deep learning models for chromosome classification by a large margin. Such a straightening approach has the potential to be combined with other karyotyping systems to assist cytogeneticists in chromosome analysis.
Adjacent-level Feature Cross-Fusion with 3D CNN for Remote Sensing Image Change Detection
Feb 10, 2023



Deep learning-based change detection using remote sensing images has received increasing attention in recent years. However, how to effectively extract and fuse the deep features of bi-temporal images to improve the accuracy of change detection is still a challenge. To address that, a novel adjacent-level feature fusion network with 3D convolution (named AFCF3D-Net) is proposed in this article. First, through the inner fusion property of 3D convolution, we design a new feature fusion way that can simultaneously extract and fuse the feature information from bi-temporal images. Then, in order to bridge the semantic gap between low-level features and high-level features, we propose an adjacent-level feature cross-fusion (AFCF) module to aggregate complementary feature information between the adjacent-levels. Furthermore, the densely skip connection strategy is introduced to improve the capability of pixel-wise prediction and compactness of changed objects in the results. Finally, the proposed AFCF3D-Net has been validated on the three challenging remote sensing change detection datasets: Wuhan building dataset (WHU-CD), LEVIR building dataset (LEVIR-CD), and Sun Yat-Sen University (SYSU-CD). The results of quantitative analysis and qualitative comparison demonstrate that the proposed AFCF3D-Net achieves better performance compared to the other state-of-the-art change detection methods.
Exploiting Neighborhood Structural Features for Change Detection
Feb 10, 2023In this letter, a novel method for change detection is proposed using neighborhood structure correlation. Because structure features are insensitive to the intensity differences between bi-temporal images, we perform the correlation analysis on structure features rather than intensity information. First, we extract the structure feature maps by using multi-orientated gradient information. Then, the structure feature maps are used to obtain the Neighborhood Structural Correlation Image (NSCI), which can represent the context structure information. In addition, we introduce a measure named matching error which can be used to improve neighborhood information. Subsequently, a change detection model based on the random forest is constructed. The NSCI feature and matching error are used as the model inputs for training and prediction. Finally, the decision tree voting is used to produce the change detection result. To evaluate the performance of the proposed method, it was compared with three state-of-the-art change detection methods. The experimental results on two datasets demonstrated the effectiveness and robustness of the proposed method.
Advances and Challenges in Multimodal Remote Sensing Image Registration
Feb 07, 2023Over the past few decades, with the rapid development of global aerospace and aerial remote sensing technology, the types of sensors have evolved from the traditional monomodal sensors (e.g., optical sensors) to the new generation of multimodal sensors [e.g., multispectral, hyperspectral, light detection and ranging (LiDAR) and synthetic aperture radar (SAR) sensors]. These advanced devices can dynamically provide various and abundant multimodal remote sensing images with different spatial, temporal, and spectral resolutions according to different application requirements. Since then, it is of great scientific significance to carry out the research of multimodal remote sensing image registration, which is a crucial step for integrating the complementary information among multimodal data and making comprehensive observations and analysis of the Earths surface. In this work, we will present our own contributions to the field of multimodal image registration, summarize the advantages and limitations of existing multimodal image registration methods, and then discuss the remaining challenges and make a forward-looking prospect for the future development of the field.
R2FD2: Fast and Robust Matching of Multimodal Remote Sensing Image via Repeatable Feature Detector and Rotation-invariant Feature Descriptor
Dec 06, 2022Automatically identifying feature correspondences between multimodal images is facing enormous challenges because of the significant differences both in radiation and geometry. To address these problems, we propose a novel feature matching method (named R2FD2) that is robust to radiation and rotation differences. Our R2FD2 is conducted in two critical contributions, consisting of a repeatable feature detector and a rotation-invariant feature descriptor. In the first stage, a repeatable feature detector called the Multi-channel Auto-correlation of the Log-Gabor (MALG) is presented for feature detection, which combines the multi-channel auto-correlation strategy with the Log-Gabor wavelets to detect interest points (IPs) with high repeatability and uniform distribution. In the second stage, a rotation-invariant feature descriptor is constructed, named the Rotation-invariant Maximum index map of the Log-Gabor (RMLG), which consists of two components: fast assignment of dominant orientation and construction of feature representation. In the process of fast assignment of dominant orientation, a Rotation-invariant Maximum Index Map (RMIM) is built to address rotation deformations. Then, the proposed RMLG incorporates the rotation-invariant RMIM with the spatial configuration of DAISY to depict a more discriminative feature representation, which improves RMLG's resistance to radiation and rotation variances.Experimental results show that the proposed R2FD2 outperforms five state-of-the-art feature matching methods, and has superior advantages in adaptability and universality. Moreover, our R2FD2 achieves the accuracy of matching within two pixels and has a great advantage in matching efficiency over other state-of-the-art methods.
A Robust Multimodal Remote Sensing Image Registration Method and System Using Steerable Filters with First- and Second-order Gradients
Feb 27, 2022

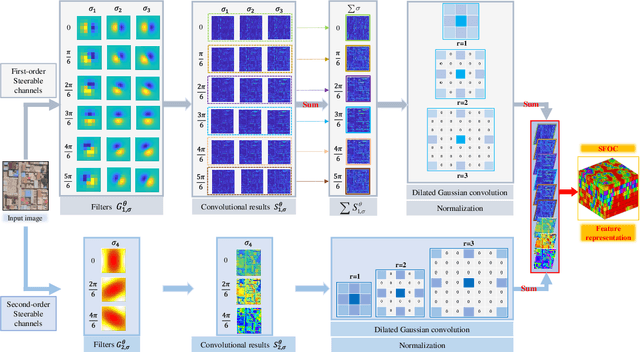

Co-registration of multimodal remote sensing images is still an ongoing challenge because of nonlinear radiometric differences (NRD) and significant geometric distortions (e.g., scale and rotation changes) between these images. In this paper, a robust matching method based on the Steerable filters is proposed consisting of two critical steps. First, to address severe NRD, a novel structural descriptor named the Steerable Filters of first- and second-Order Channels (SFOC) is constructed, which combines the first- and second-order gradient information by using the steerable filters with a multi-scale strategy to depict more discriminative structure features of images. Then, a fast similarity measure is established called Fast Normalized Cross-Correlation (Fast-NCCSFOC), which employs the Fast Fourier Transform technique and the integral image to improve the matching efficiency. Furthermore, to achieve reliable registration performance, a coarse-to-fine multimodal registration system is designed consisting of two pivotal modules. The local coarse registration is first conducted by involving both detection of interest points (IPs) and local geometric correction, which effectively utilizes the prior georeferencing information of RS images to address global geometric distortions. In the fine registration stage, the proposed SFOC is used to resist significant NRD, and to detect control points between multimodal images by a template matching scheme. The performance of the proposed matching method has been evaluated with many different kinds of multimodal RS images. The results show its superior matching performance compared with the state-of-the-art methods. Moreover, the designed registration system also outperforms the popular commercial software in both registration accuracy and computational efficiency. Our system is available at https://github.com/yeyuanxin110.
Robust Registration of Multimodal Remote Sensing Images Based on Structural Similarity
Mar 31, 2021
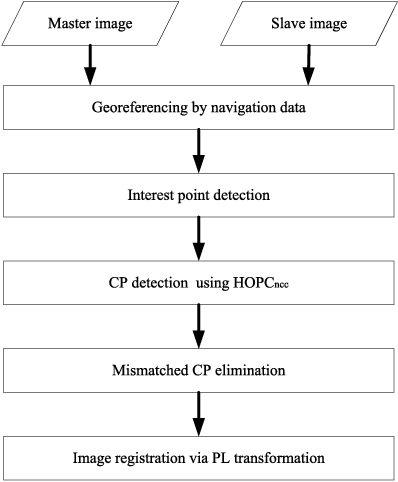


Automatic registration of multimodal remote sensing data (e.g., optical, LiDAR, SAR) is a challenging task due to the significant non-linear radiometric differences between these data. To address this problem, this paper proposes a novel feature descriptor named the Histogram of Orientated Phase Congruency (HOPC), which is based on the structural properties of images. Furthermore, a similarity metric named HOPCncc is defined, which uses the normalized correlation coefficient (NCC) of the HOPC descriptors for multimodal registration. In the definition of the proposed similarity metric, we first extend the phase congruency model to generate its orientation representation, and use the extended model to build HOPCncc. Then a fast template matching scheme for this metric is designed to detect the control points between images. The proposed HOPCncc aims to capture the structural similarity between images, and has been tested with a variety of optical, LiDAR, SAR and map data. The results show that HOPCncc is robust against complex non-linear radiometric differences and outperforms the state-of-the-art similarities metrics (i.e., NCC and mutual information) in matching performance. Moreover, a robust registration method is also proposed in this paper based on HOPCncc, which is evaluated using six pairs of multimodal remote sensing images. The experimental results demonstrate the effectiveness of the proposed method for multimodal image registration.
Misregistration Measurement and Improvement for Sentinel-1 SAR and Sentinel-2 Optical images
May 22, 2020


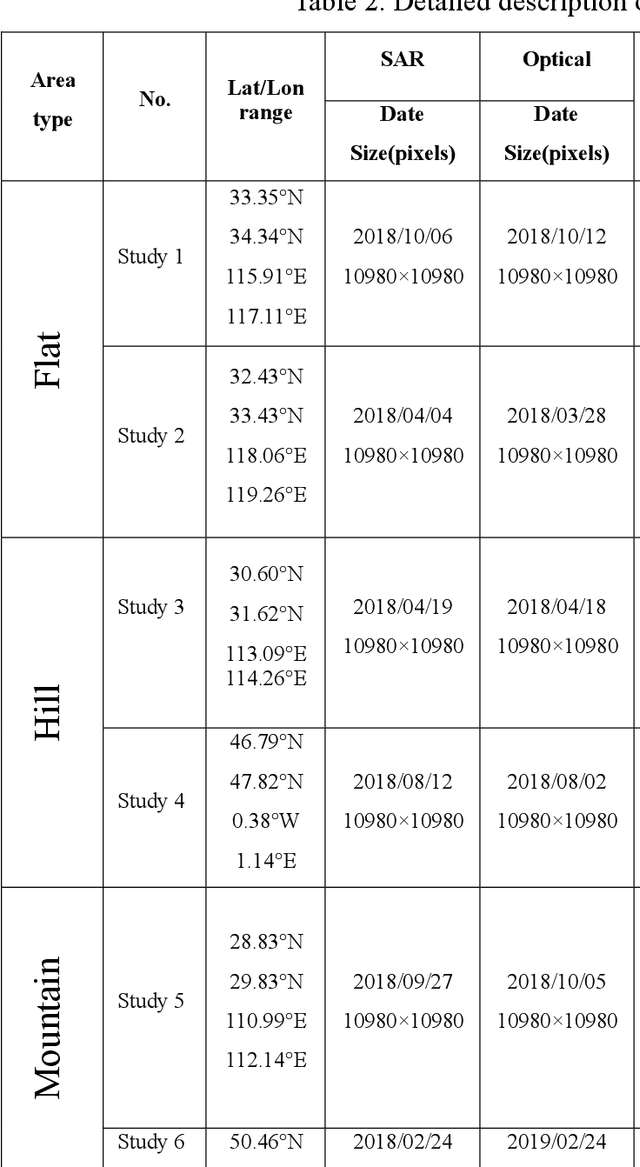
Co-registering the Sentinel-1 SAR and Sentinel-2 optical data of European Space Agency (ESA) is of great importance for many remote sensing applications. The Sentinel-1 and 2 product specifications from ESA show that the Sentinel-1 SAR L1 and the Sentinel-2 optical L1C images have a co-registration accuracy of within 2 pixels. However, we find that the actual misregistration errors are much larger than that between such images. This paper measures the misregistration errors by a block-based multimodal image matching strategy to six pairs of the Sentinel-1 SAR and Sentinel-2 optical images, which locate in China and Europe and cover three different terrains such as flat areas, hilly areas and mountainous areas. Our experimental results show the misregistration errors of the flat areas are 20-30 pixels, and these of the hilly areas are 20-40 pixels. While in the mountainous areas, the errors increase to 50-60 pixels. To eliminate the misregistration, we use some representative geometric transformation models such as polynomial models, projective models, and rational function models for the co-registration of the two types of images, and compare and analyze their registration accuracy under different number of control points and different terrains. The results of our analysis show that the 3rd. Order polynomial achieves the most satisfactory registration results. Its registration accuracy of the flat areas is less than 1.0 10m pixels, and that of the hilly areas is about 1.5 pixels, and that of the mountainous areas is between 1.8 and 2.3 pixels. In a word, this paper discloses and measures the misregistration between the Sentinel-1 SAR L1 and Sentinel-2 optical L1C images for the first time. Moreover, we also determine a relatively optimal geometric transformation model of the co-registration of the two types of images.
Fast and Robust Registration of Aerial Images and LiDAR data Based on Structrual Features and 3D Phase Correlation
Apr 21, 2020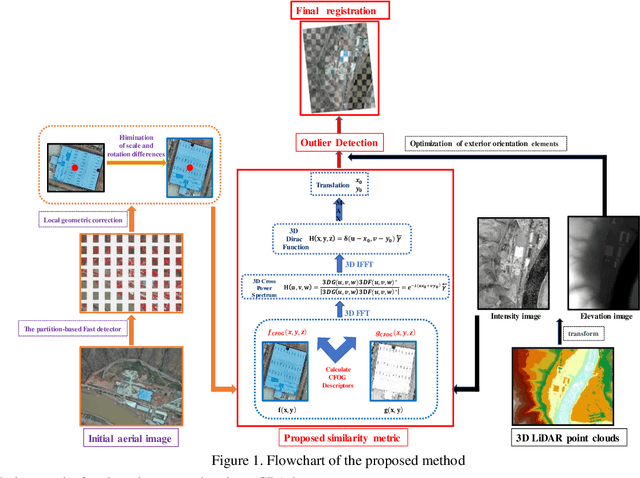

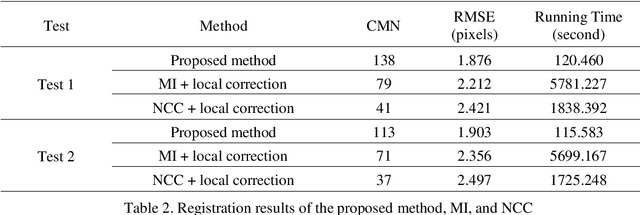

Co-Registration of aerial imagery and Light Detection and Ranging (LiDAR) data is quilt challenging because the different imaging mechanism causes significant geometric and radiometric distortions between such data. To tackle the problem, this paper proposes an automatic registration method based on structural features and three-dimension (3D) phase correlation. In the proposed method, the LiDAR point cloud data is first transformed into the intensity map, which is used as the reference image. Then, we employ the Fast operator to extract uniformly distributed interest points in the aerial image by a partition strategy and perform a local geometric correction by using the collinearity equation to eliminate scale and rotation difference between images. Subsequently, a robust structural feature descriptor is build based on dense gradient features, and the 3D phase correlation is used to detect control points (CPs) between aerial images and LiDAR data in the frequency domain, where the image matching is accelerated by the 3D Fast Fourier Transform (FFT). Finally, the obtained CPs are employed to correct the exterior orientation elements, which is used to achieve co-registration of aerial images and LiDAR data. Experiments with two datasets of aerial images and LiDAR data show that the proposed method is much faster and more robust than state of the art methods