 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-GMSI: A transformer-based generative model for spatial interpolation under sparse measurements
Dec 13, 2024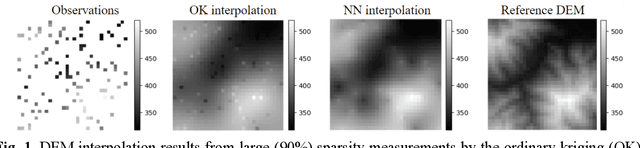
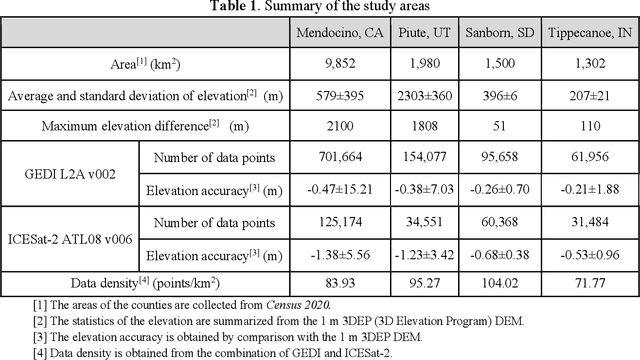
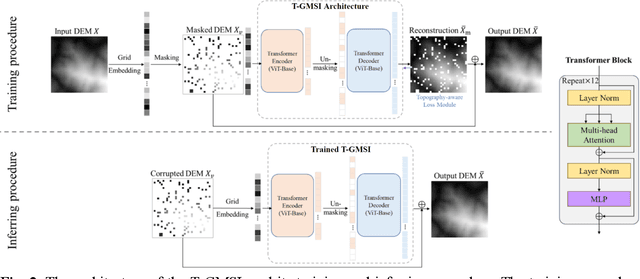
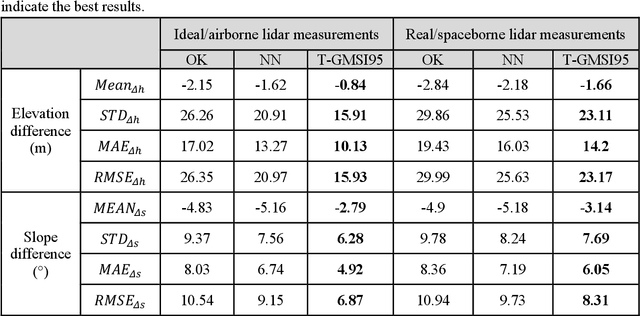
Generating continuous environmental models from sparsely sampled data is a critical challenge in spatial modeling, particularly for topography. Traditional spatial interpolation methods often struggle with handling sparse measurements. To address this, we propose a Transformer-based Generative Model for Spatial Interpolation (T-GMSI) using a vision transformer (ViT) architecture for digital elevation model (DEM) generation under sparse conditions. T-GMSI replaces traditional convolution-based methods with ViT for feature extraction and DEM interpolation while incorporating a terrain feature-aware loss function for enhanced accuracy. T-GMSI excels in producing high-quality elevation surfaces from datasets with over 70% sparsity and demonstrates strong transferability across diverse landscapes without fine-tuning. Its performance is validated through extensive experiments, outperforming traditional methods such as ordinary Kriging (OK) and natural neighbor (NN) and a conditional generative adversarial network (CGAN)-based model (CEDGAN). Compared to OK and NN, T-GMSI reduces root mean square error (RMSE) by 40% and 25% on airborne lidar data and by 23% and 10% on spaceborne lidar data. Against CEDGAN, T-GMSI achieves a 20% RMSE improvement on provided DEM data, requiring no fine-tuning. The ability of model on generalizing to large, unseen terrains underscores its transferability and potential applicability beyond topographic modeling. This research establishes T-GMSI as a state-of-the-art solution for spatial interpolation on sparse datasets and highlights its broader utility for other sparse data interpolation challenges.
Robust Registration of Multimodal Remote Sensing Images Based on Structural Similarity
Mar 31, 2021
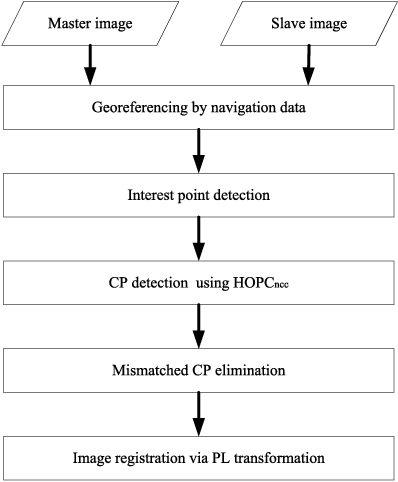


Automatic registration of multimodal remote sensing data (e.g., optical, LiDAR, SAR) is a challenging task due to the significant non-linear radiometric differences between these data. To address this problem, this paper proposes a novel feature descriptor named the Histogram of Orientated Phase Congruency (HOPC), which is based on the structural properties of images. Furthermore, a similarity metric named HOPCncc is defined, which uses the normalized correlation coefficient (NCC) of the HOPC descriptors for multimodal registration. In the definition of the proposed similarity metric, we first extend the phase congruency model to generate its orientation representation, and use the extended model to build HOPCncc. Then a fast template matching scheme for this metric is designed to detect the control points between images. The proposed HOPCncc aims to capture the structural similarity between images, and has been tested with a variety of optical, LiDAR, SAR and map data. The results show that HOPCncc is robust against complex non-linear radiometric differences and outperforms the state-of-the-art similarities metrics (i.e., NCC and mutual information) in matching performance. Moreover, a robust registration method is also proposed in this paper based on HOPCncc, which is evaluated using six pairs of multimodal remote sensing images. The experimental results demonstrate the effectiveness of the proposed method for multimodal image registration.
PSA-Net: Deep Learning based Physician Style-Aware Segmentation Network for Post-Operative Prostate Cancer Clinical Target Volume
Feb 15, 2021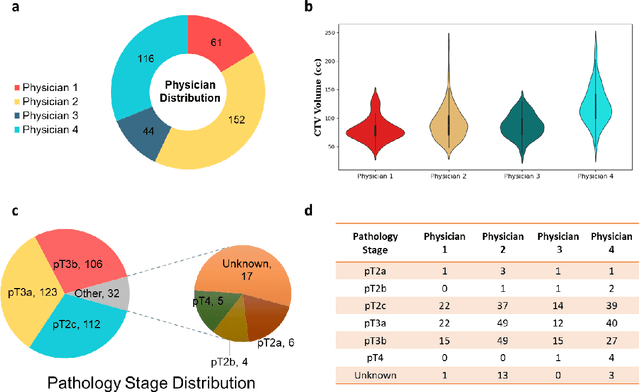
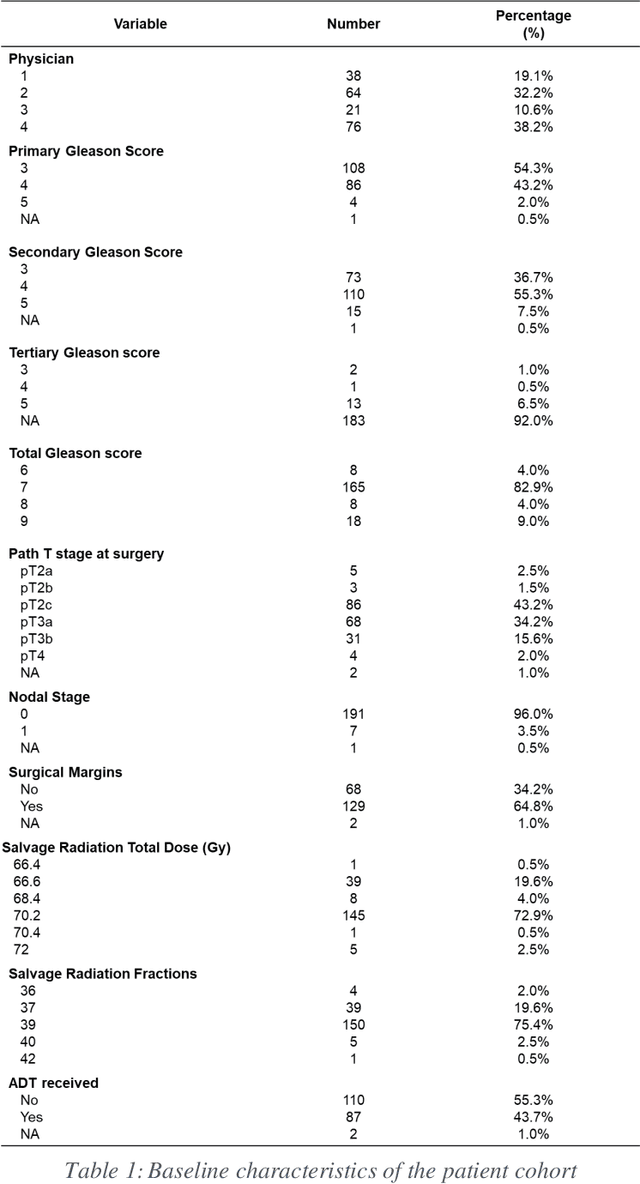
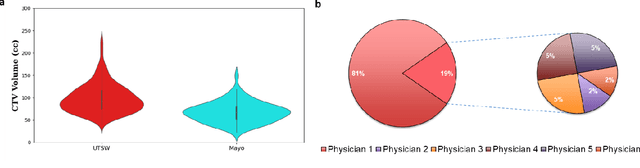
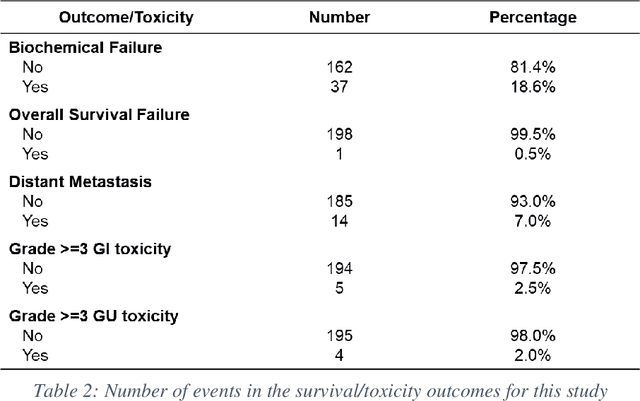
Automatic segmentation of medical images with DL algorithms has proven to be highly successful. With most of these algorithms, inter-observer variation is an acknowledged problem, leading to sub-optimal results. This problem is even more significant in post-operative clinical target volume (post-op CTV) segmentation due to the absence of macroscopic visual tumor in the image. This study, using post-op CTV segmentation as the test bed, tries to determine if physician styles are consistent and learnable, if there is an impact of physician styles on treatment outcome and toxicity; and how to explicitly deal with physician styles in DL algorithms to facilitate its clinical acceptance. A classifier is trained to identify which physician has contoured the CTV from just the contour and corresponding CT scan, to determine if physician styles are consistent and learnable. Next, we evaluate if adapting automatic segmentation to physician styles would be clinically feasible based on a lack of difference between outcomes. For modeling different physician styles of CTV segmentation, a concept called physician style-aware (PSA) segmentation is proposed which is an encoder-multidecoder network trained with perceptual loss. With the proposed physician style-aware network (PSA-Net), Dice similarity coefficient (DSC) accuracy increases on an average of 3.4% for all physicians from a general model that is not style adapted. We show that stylistic contouring variations also exist between institutions that follow the same segmentation guidelines and show the effectiveness of the proposed method in adapting to new institutional styles. We observed an accuracy improvement of 5% in terms of DSC when adapting to the style of a separate institution.
Holistic Parameteric Reconstruction of Building Models from Point Clouds
May 19, 2020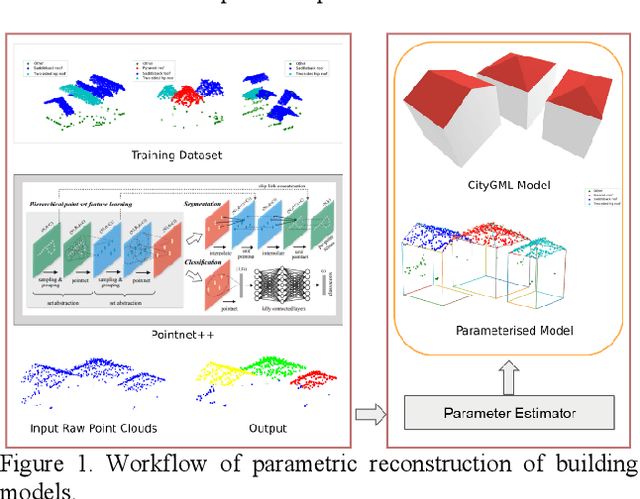


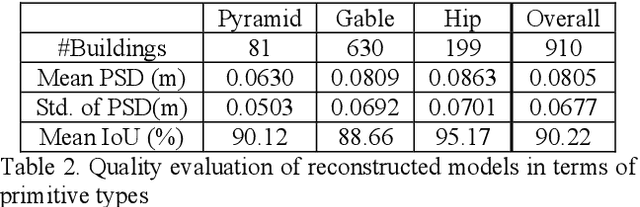
Building models are conventionally reconstructed by building roof points planar segmentation and then using a topology graph to group the planes together. Roof edges and vertices are then mathematically represented by intersecting segmented planes. Technically, such solution is based on sequential local fitting, i.e., the entire data of one building are not simultaneously participating in determining the building model. As a consequence, the solution is lack of topological integrity and geometric rigor. Fundamentally different from this traditional approach, we propose a holistic parametric reconstruction method which means taking into consideration the entire point clouds of one building simultaneously. In our work, building models are reconstructed from predefined parametric (roof) primitives. We first use a well-designed deep neural network to segment and identify primitives in the given building point clouds. A holistic optimization strategy is then introduced to simultaneously determine the parameters of a segmented primitive. In the last step, the optimal parameters are used to generate a watertight building model in CityGML format. The airborne LiDAR dataset RoofN3D with predefined roof types is used for our test. It is shown that PointNet++ applied to the entire dataset can achieve an accuracy of 83% for primitive classification. For a subset of 910 buildings in RoofN3D, the holistic approach is then used to determine the parameters of primitives and reconstruct the buildings. The achieved overall quality of reconstruction is 0.08 meters for point-surface-distance or 0.7 times RMSE of the input LiDAR points. The study demonstrates the efficiency and capability of the proposed approach and its potential to handle large scale urban point clouds.
Deep Learning Guided Building Reconstruction from Satellite Imagery-derived Point Clouds
May 19, 2020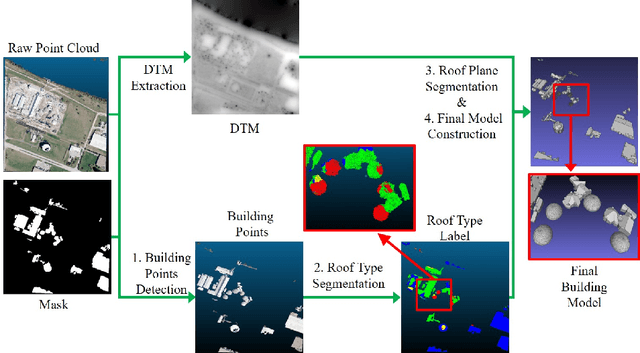
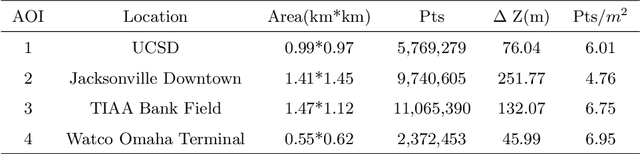
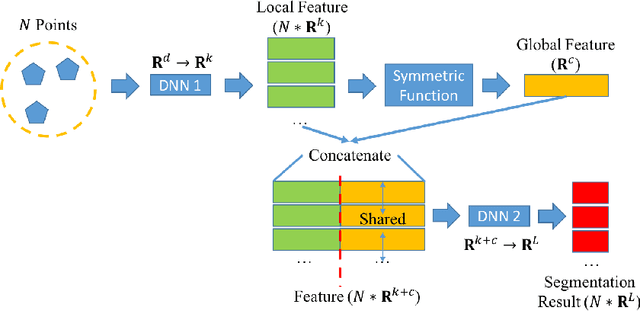
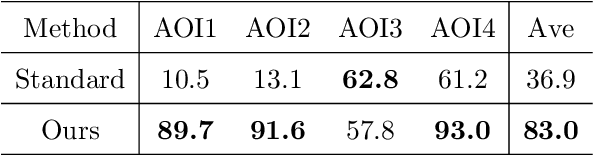
3D urban reconstruction of buildings from remotely sensed imagery has drawn significant attention during the past two decades. While aerial imagery and LiDAR provide higher resolution, satellite imagery is cheaper and more efficient to acquire for large scale need. However, the high, orbital altitude of satellite observation brings intrinsic challenges, like unpredictable atmospheric effect, multi view angles, significant radiometric differences due to the necessary multiple views, diverse land covers and urban structures in a scene, small base-height ratio or narrow field of view, all of which may degrade 3D reconstruction quality. To address these major challenges, we present a reliable and effective approach for building model reconstruction from the point clouds generated from multi-view satellite images. We utilize multiple types of primitive shapes to fit the input point cloud. Specifically, a deep-learning approach is adopted to distinguish the shape of building roofs in complex and yet noisy scenes. For points that belong to the same roof shape, a multi-cue, hierarchical RANSAC approach is proposed for efficient and reliable segmenting and reconstructing the building point cloud. Experimental results over four selected urban areas (0.34 to 2.04 sq km in size) demonstrate the proposed method can generate detailed roof structures under noisy data environments. The average successful rate for building shape recognition is 83.0%, while the overall completeness and correctness are over 70% with reference to ground truth created from airborne lidar. As the first effort to address the public need of large scale city model generation, the development is deployed as open source software.
Material Segmentation of Multi-View Satellite Imagery
Apr 17, 2019
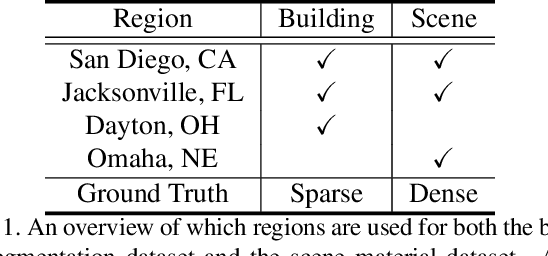
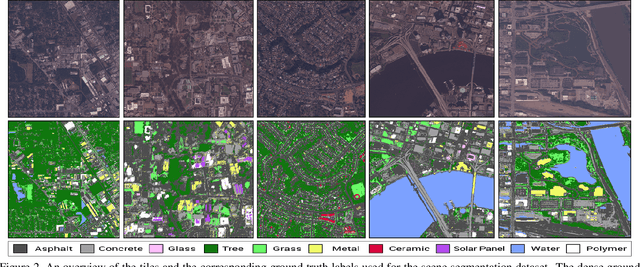

Material recognition methods use image context and local cues for pixel-wise classification. In many cases only a single image is available to make a material prediction. Image sequences, routinely acquired in applications such as mutliview stereo, can provide a sampling of the underlying reflectance functions that reveal pixel-level material attributes. We investigate multi-view material segmentation using two datasets generated for building material segmentation and scene material segmentation from the SpaceNet Challenge satellite image dataset. In this paper, we explore the impact of multi-angle reflectance information by introducing the \textit{reflectance residual encoding}, which captures both the multi-angle and multispectral information present in our datasets. The residuals are computed by differencing the sparse-sampled reflectance function with a dictionary of pre-defined dense-sampled reflectance functions. Our proposed reflectance residual features improves material segmentation performance when integrated into pixel-wise and semantic segmentation architectures. At test time, predictions from individual segmentations are combined through softmax fusion and refined by building segment voting. We demonstrate robust and accurate pixelwise segmentation results using the proposed material segmentation pipeline.
A Fast and Robust Matching Framework for Multimodal Remote Sensing Image Registration
Aug 19, 2018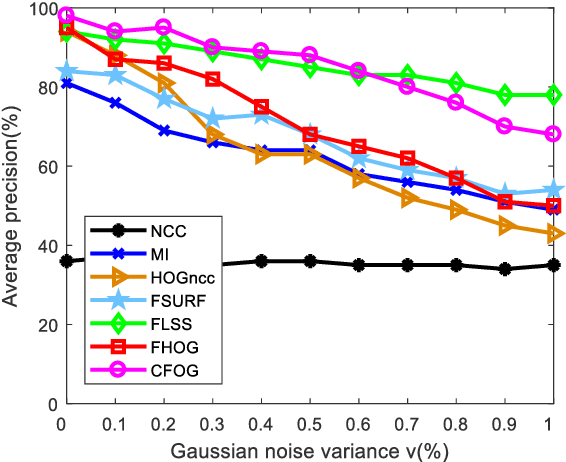
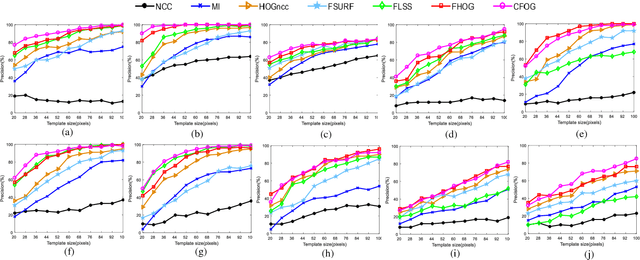
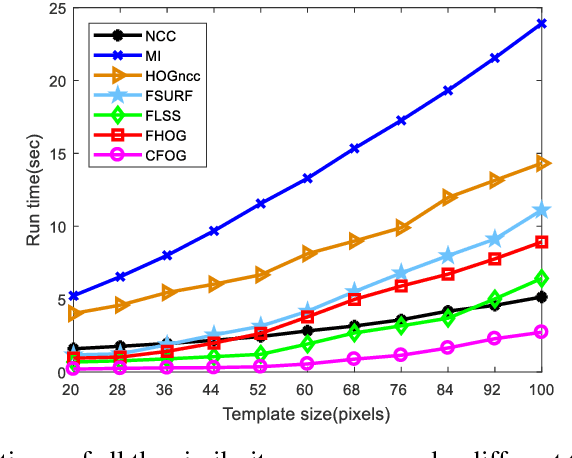

While image registration has been studied in remote sensing community for decades, registering multimodal data [e.g., optical, light detection and ranging (LiDAR), synthetic aperture radar (SAR), and map] remains a challenging problem because of significant nonlinear intensity differences between such data. To address this problem, we present a novel fast and robust matching framework integrating local descriptors for multimodal registration. In the proposed framework, a local descriptor (such as Histogram of Oriented Gradient (HOG), Local Self-Similarity or Speeded-Up Robust Feature) is first extracted at each pixel to form a pixel-wise feature representation of an image. Then we define a similarity measure based on the feature representation in frequency domain using the Fast Fourier Transform (FFT) technique, followed by a template matching scheme to detect control points between images. We also propose a novel pixel-wise feature representation using orientated gradients of images, which is named channel features of orientated gradients (CFOG). This novel feature is an extension of the pixel-wise HOG descriptor, and outperforms that both in matching performance and computational efficiency. The major advantages of the proposed framework include (1) structural similarity representation using the pixel-wise feature description and (2) high computational efficiency due to the use of FFT. Moreover, we design an automatic registration system for very large-size multimodal images based on the proposed framework. Experimental results obtained on many different types of multimodal images show the superior matching performance of the proposed framework with respect to the state-of-the-art methods and the effectiveness of the designed system, which show very good potential large-size image registration in real applications.