 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging AI to Accelerate Clinical Data Cleaning: A Comparative Study of AI-Assisted vs. Traditional Methods
Aug 07, 2025Clinical trial data cleaning represents a critical bottleneck in drug development, with manual review processes struggling to manage exponentially increasing data volumes and complexity. This paper presents Octozi, an artificial intelligence-assisted platform that combines large language models with domain-specific heuristics to transform clinical data review. In a controlled experimental study with experienced clinical reviewers (n=10), we demonstrate that AI assistance increased data cleaning throughput by 6.03-fold while simultaneously decreasing cleaning errors from 54.67% to 8.48% (a 6.44-fold improvement). Crucially, the system reduced false positive queries by 15.48-fold, minimizing unnecessary site burden. These improvements were consistent across reviewers regardless of experience level, suggesting broad applicability. Our findings indicate that AI-assisted approaches can address fundamental inefficiencies in clinical trial operations, potentially accelerating drug development timelines and reducing costs while maintaining regulatory compliance. This work establishes a framework for integrating AI into safety-critical clinical workflows and demonstrates the transformative potential of human-AI collaboration in pharmaceutical clinical trials.
Inferring the past: a combined CNN-LSTM deep learning framework to fuse satellites for historical inundation mapping
May 01, 2023Mapping floods using satellite data is crucial for managing and mitigating flood risks. Satellite imagery enables rapid and accurate analysis of large areas, providing critical information for emergency response and disaster management. Historical flood data derived from satellite imagery can inform long-term planning, risk management strategies, and insurance-related decisions. The Sentinel-1 satellite is effective for flood detection, but for longer time series, other satellites such as MODIS can be used in combination with deep learning models to accurately identify and map past flood events. We here develop a combined CNN--LSTM deep learning framework to fuse Sentinel-1 derived fractional flooded area with MODIS data in order to infer historical floods over Bangladesh. The results show how our framework outperforms a CNN-only approach and takes advantage of not only space, but also time in order to predict the fractional inundated area. The model is applied to historical MODIS data to infer the past 20 years of inundation extents over Bangladesh and compared to a thresholding algorithm and a physical model. Our fusion model outperforms both models in consistency and capacity to predict peak inundation extents.
Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks
Dec 03, 2021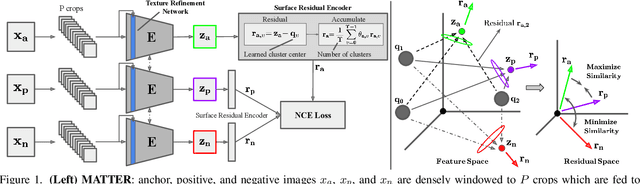



Self-supervised learning aims to learn image feature representations without the usage of manually annotated labels. It is often used as a precursor step to obtain useful initial network weights which contribute to faster convergence and superior performance of downstream tasks. While self-supervision allows one to reduce the domain gap between supervised and unsupervised learning without the usage of labels, the self-supervised objective still requires a strong inductive bias to downstream tasks for effective transfer learning. In this work, we present our material and texture based self-supervision method named MATTER (MATerial and TExture Representation Learning), which is inspired by classical material and texture methods. Material and texture can effectively describe any surface, including its tactile properties, color, and specularity. By extension, effective representation of material and texture can describe other semantic classes strongly associated with said material and texture. MATTER leverages multi-temporal, spatially aligned remote sensing imagery over unchanged regions to learn invariance to illumination and viewing angle as a mechanism to achieve consistency of material and texture representation. We show that our self-supervision pre-training method allows for up to 24.22% and 6.33% performance increase in unsupervised and fine-tuned setups, and up to 76% faster convergence on change detection, land cover classification, and semantic segmentation tasks.
Street to Cloud: Improving Flood Maps With Crowdsourcing and Semantic Segmentation
Nov 05, 2020
To address the mounting destruction caused by floods in climate-vulnerable regions, we propose Street to Cloud, a machine learning pipeline for incorporating crowdsourced ground truth data into the segmentation of satellite imagery of floods. We propose this approach as a solution to the labor-intensive task of generating high-quality, hand-labeled training data, and demonstrate successes and failures of different plausible crowdsourcing approaches in our model. Street to Cloud leverages community reporting and machine learning to generate novel, near-real time insights into the extent of floods to be used for emergency response.
H2O-Net: Self-Supervised Flood Segmentation via Adversarial Domain Adaptation and Label Refinement
Oct 11, 2020



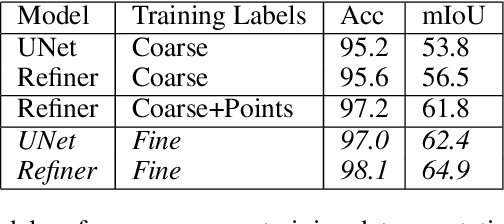
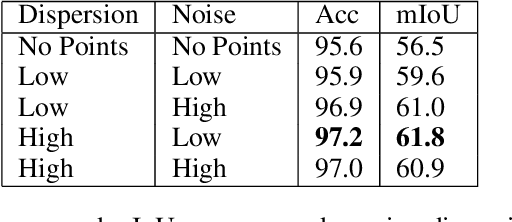
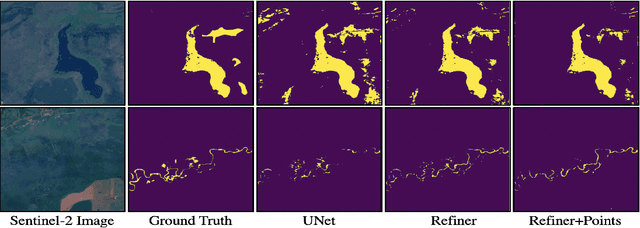
Accurate flood detection in near real time via high resolution, high latency satellite imagery is essential to prevent loss of lives by providing quick and actionable information. Instruments and sensors useful for flood detection are only available in low resolution, low latency satellites with region re-visit periods of up to 16 days, making flood alerting systems that use such satellites unreliable. This work presents H2O-Network, a self supervised deep learning method to segment floods from satellites and aerial imagery by bridging domain gap between low and high latency satellite and coarse-to-fine label refinement. H2O-Net learns to synthesize signals highly correlative with water presence as a domain adaptation step for semantic segmentation in high resolution satellite imagery. Our work also proposes a self-supervision mechanism, which does not require any hand annotation, used during training to generate high quality ground truth data. We demonstrate that H2O-Net outperforms the state-of-the-art semantic segmentation methods on satellite imagery by 10% and 12% pixel accuracy and mIoU respectively for the task of flood segmentation. We emphasize the generalizability of our model by transferring model weights trained on satellite imagery to drone imagery, a highly different sensor and domain.
Angular Luminance for Material Segmentation
Sep 22, 2020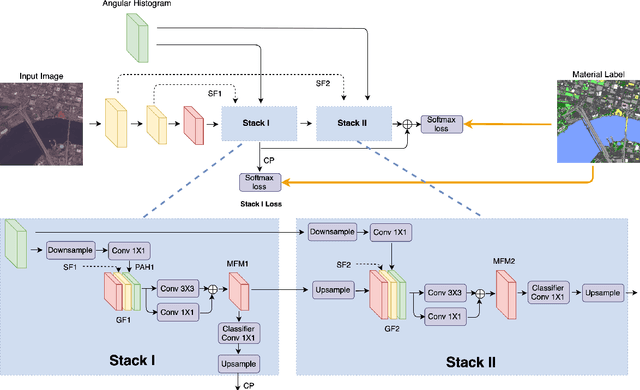
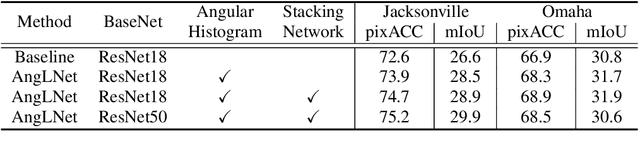


Moving cameras provide multiple intensity measurements per pixel, yet often semantic segmentation, material recognition, and object recognition do not utilize this information. With basic alignment over several frames of a moving camera sequence, a distribution of intensities over multiple angles is obtained. It is well known from prior work that luminance histograms and the statistics of natural images provide a strong material recognition cue. We utilize per-pixel {\it angular luminance distributions} as a key feature in discriminating the material of the surface. The angle-space sampling in a multiview satellite image sequence is an unstructured sampling of the underlying reflectance function of the material. For real-world materials there is significant intra-class variation that can be managed by building a angular luminance network (AngLNet). This network combines angular reflectance cues from multiple images with spatial cues as input to fully convolutional networks for material segmentation. We demonstrate the increased performance of AngLNet over prior state-of-the-art in material segmentation from satellite imagery.
* IEEE International Geoscience and Remote Sensing Symposium (IGARSS) 2020
Teaching Cameras to Feel: Estimating Tactile Physical Properties of Surfaces From Images
May 07, 2020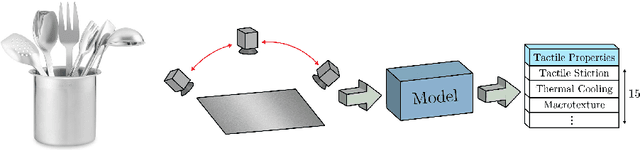



The connection between visual input and tactile sensing is critical for object manipulation tasks such as grasping and pushing. In this work, we introduce the challenging task of estimating a set of tactile physical properties from visual information. We aim to build a model that learns the complex mapping between visual information and tactile physical properties. We construct a first of its kind image-tactile dataset with over 400 multiview image sequences and the corresponding tactile properties. A total of fifteen tactile physical properties across categories including friction, compliance, adhesion, texture, and thermal conductance are measured and then estimated by our models. We develop a cross-modal framework comprised of an adversarial objective and a novel visuo-tactile joint classification loss. Additionally, we develop a neural architecture search framework capable of selecting optimal combinations of viewing angles for estimating a given physical property.
Material Segmentation of Multi-View Satellite Imagery
Apr 17, 2019
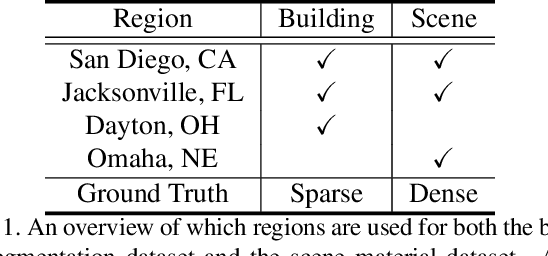
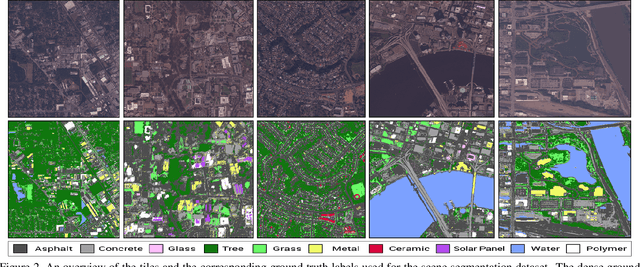

Material recognition methods use image context and local cues for pixel-wise classification. In many cases only a single image is available to make a material prediction. Image sequences, routinely acquired in applications such as mutliview stereo, can provide a sampling of the underlying reflectance functions that reveal pixel-level material attributes. We investigate multi-view material segmentation using two datasets generated for building material segmentation and scene material segmentation from the SpaceNet Challenge satellite image dataset. In this paper, we explore the impact of multi-angle reflectance information by introducing the \textit{reflectance residual encoding}, which captures both the multi-angle and multispectral information present in our datasets. The residuals are computed by differencing the sparse-sampled reflectance function with a dictionary of pre-defined dense-sampled reflectance functions. Our proposed reflectance residual features improves material segmentation performance when integrated into pixel-wise and semantic segmentation architectures. At test time, predictions from individual segmentations are combined through softmax fusion and refined by building segment voting. We demonstrate robust and accurate pixelwise segmentation results using the proposed material segmentation pipeline.