 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoWATCH for Detecting Heavy Construction in Heterogeneous Time Series of Satellite Images
Jul 08, 2024Learning from multiple sensors is challenging due to spatio-temporal misalignment and differences in resolution and captured spectra. To that end, we introduce GeoWATCH, a flexible framework for training models on long sequences of satellite images sourced from multiple sensor platforms, which is designed to handle image classification, activity recognition, object detection, or object tracking tasks. Our system includes a novel partial weight loading mechanism based on sub-graph isomorphism which allows for continually training and modifying a network over many training cycles. This has allowed us to train a lineage of models over a long period of time, which we have observed has improved performance as we adjust configurations while maintaining a core backbone.
Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks
Dec 03, 2021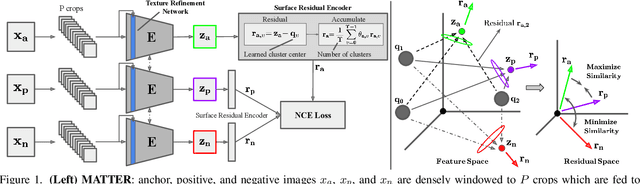



Self-supervised learning aims to learn image feature representations without the usage of manually annotated labels. It is often used as a precursor step to obtain useful initial network weights which contribute to faster convergence and superior performance of downstream tasks. While self-supervision allows one to reduce the domain gap between supervised and unsupervised learning without the usage of labels, the self-supervised objective still requires a strong inductive bias to downstream tasks for effective transfer learning. In this work, we present our material and texture based self-supervision method named MATTER (MATerial and TExture Representation Learning), which is inspired by classical material and texture methods. Material and texture can effectively describe any surface, including its tactile properties, color, and specularity. By extension, effective representation of material and texture can describe other semantic classes strongly associated with said material and texture. MATTER leverages multi-temporal, spatially aligned remote sensing imagery over unchanged regions to learn invariance to illumination and viewing angle as a mechanism to achieve consistency of material and texture representation. We show that our self-supervision pre-training method allows for up to 24.22% and 6.33% performance increase in unsupervised and fine-tuned setups, and up to 76% faster convergence on change detection, land cover classification, and semantic segmentation tasks.
Material Segmentation of Multi-View Satellite Imagery
Apr 17, 2019
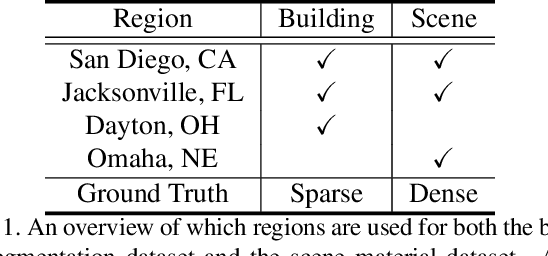
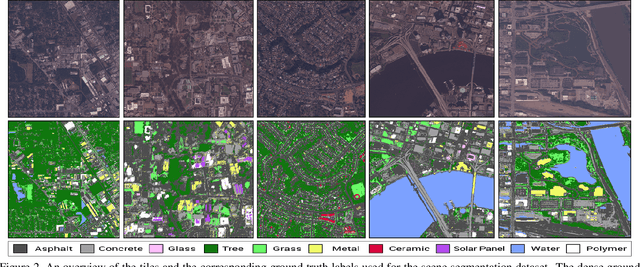

Material recognition methods use image context and local cues for pixel-wise classification. In many cases only a single image is available to make a material prediction. Image sequences, routinely acquired in applications such as mutliview stereo, can provide a sampling of the underlying reflectance functions that reveal pixel-level material attributes. We investigate multi-view material segmentation using two datasets generated for building material segmentation and scene material segmentation from the SpaceNet Challenge satellite image dataset. In this paper, we explore the impact of multi-angle reflectance information by introducing the \textit{reflectance residual encoding}, which captures both the multi-angle and multispectral information present in our datasets. The residuals are computed by differencing the sparse-sampled reflectance function with a dictionary of pre-defined dense-sampled reflectance functions. Our proposed reflectance residual features improves material segmentation performance when integrated into pixel-wise and semantic segmentation architectures. At test time, predictions from individual segmentations are combined through softmax fusion and refined by building segment voting. We demonstrate robust and accurate pixelwise segmentation results using the proposed material segmentation pipeline.