 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Trajectory Optimization with Parallelized Differentiable Traffic Simulation
Dec 21, 2024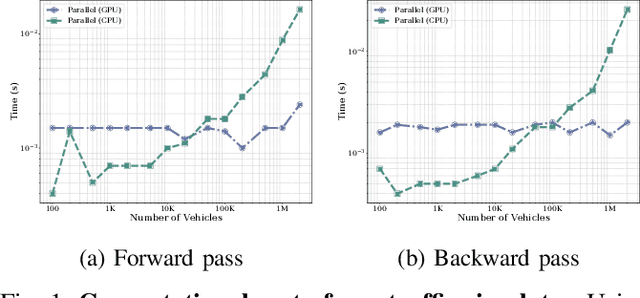
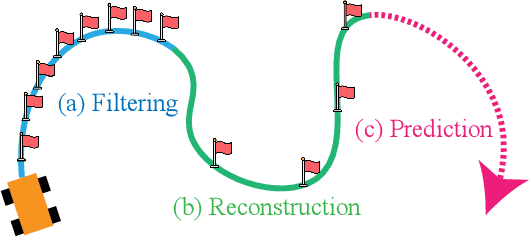
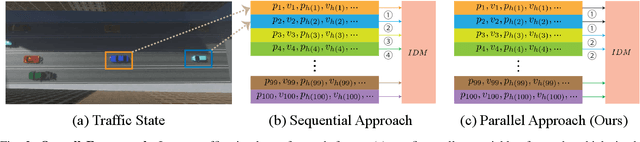

We present a parallelized differentiable traffic simulator based on the Intelligent Driver Model (IDM), a car-following framework that incorporates driver behavior as key variables. Our simulator efficiently models vehicle motion, generating trajectories that can be supervised to fit real-world data. By leveraging its differentiable nature, IDM parameters are optimized using gradient-based methods. With the capability to simulate up to 2 million vehicles in real time, the system is scalable for large-scale trajectory optimization. We show that we can use the simulator to filter noise in the input trajectories (trajectory filtering), reconstruct dense trajectories from sparse ones (trajectory reconstruction), and predict future trajectories (trajectory prediction), with all generated trajectories adhering to physical laws. We validate our simulator and algorithm on several datasets including NGSIM and Waymo Open Dataset.
GeoWATCH for Detecting Heavy Construction in Heterogeneous Time Series of Satellite Images
Jul 08, 2024Learning from multiple sensors is challenging due to spatio-temporal misalignment and differences in resolution and captured spectra. To that end, we introduce GeoWATCH, a flexible framework for training models on long sequences of satellite images sourced from multiple sensor platforms, which is designed to handle image classification, activity recognition, object detection, or object tracking tasks. Our system includes a novel partial weight loading mechanism based on sub-graph isomorphism which allows for continually training and modifying a network over many training cycles. This has allowed us to train a lineage of models over a long period of time, which we have observed has improved performance as we adjust configurations while maintaining a core backbone.
Weakly-Supervised Feature Learning via Text and Image Matching
Oct 06, 2020

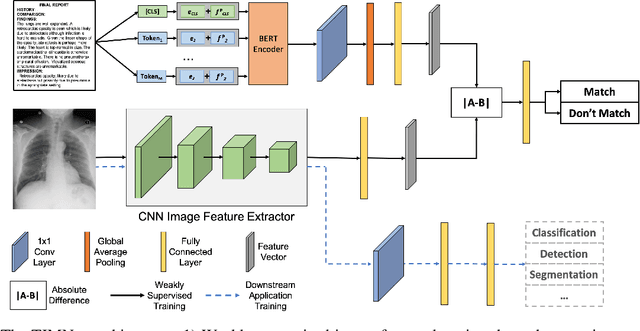
When training deep neural networks for medical image classification, obtaining a sufficient number of manually annotated images is often a significant challenge. We propose to use textual findings, which are routinely written by clinicians during manual image analysis, to help overcome this problem. The key idea is to use a contrastive loss to train image and text feature extractors to recognize if a given image-finding pair is a true match. The learned image feature extractor is then fine-tuned, in a transfer learning setting, for a supervised classification task. This approach makes it possible to train using large datasets because pairs of images and textual findings are widely available in medical records. We evaluate our method on three datasets and find consistent performance improvements. The biggest gains are realized when fewer manually labeled examples are available. In some cases, our method achieves the same performance as the baseline even when using 70\%--98\% fewer labeled examples.
Single Image Cloud Detection via Multi-Image Fusion
Jul 29, 2020



Artifacts in imagery captured by remote sensing, such as clouds, snow, and shadows, present challenges for various tasks, including semantic segmentation and object detection. A primary challenge in developing algorithms for identifying such artifacts is the cost of collecting annotated training data. In this work, we explore how recent advances in multi-image fusion can be leveraged to bootstrap single image cloud detection. We demonstrate that a network optimized to estimate image quality also implicitly learns to detect clouds. To support the training and evaluation of our approach, we collect a large dataset of Sentinel-2 images along with a per-pixel semantic labelling for land cover. Through various experiments, we demonstrate that our method reduces the need for annotated training data and improves cloud detection performance.
Learning Geo-Temporal Image Features
Sep 16, 2019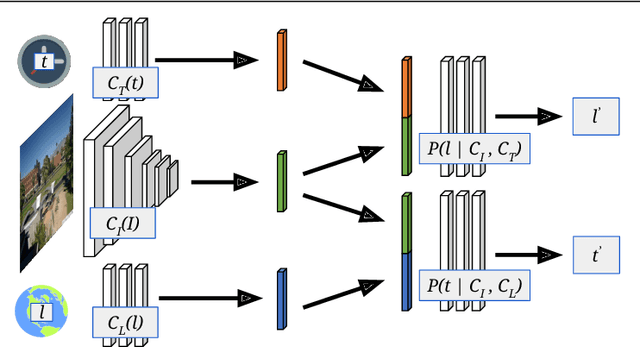

We propose to implicitly learn to extract geo-temporal image features, which are mid-level features related to when and where an image was captured, by explicitly optimizing for a set of location and time estimation tasks. To train our method, we take advantage of a large image dataset, captured by outdoor webcams and cell phones. The only form of supervision we provide are the known capture time and location of each image. We find that our approach learns features that are related to natural appearance changes in outdoor scenes. Additionally, we demonstrate the application of these geo-temporal features to time and location estimation.
Learning to Map Nearly Anything
Sep 16, 2019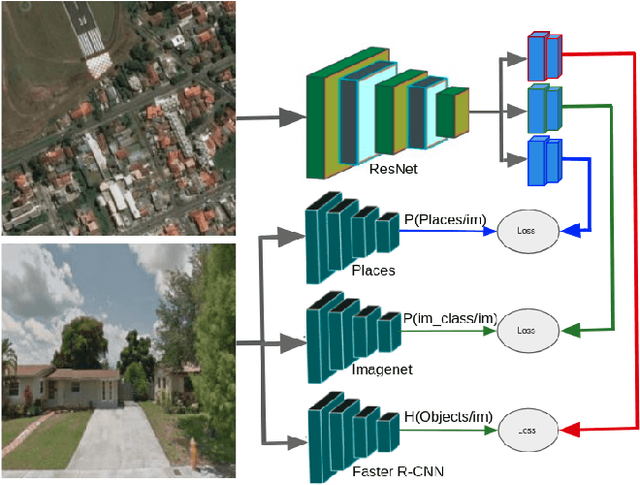


Looking at the world from above, it is possible to estimate many properties of a given location, including the type of land cover and the expected land use. Historically, such tasks have relied on relatively coarse-grained categories due to the difficulty of obtaining fine-grained annotations. In this work, we propose an easily extensible approach that makes it possible to estimate fine-grained properties from overhead imagery. In particular, we propose a cross-modal distillation strategy to learn to predict the distribution of fine-grained properties from overhead imagery, without requiring any manual annotation of overhead imagery. We show that our learned models can be used directly for applications in mapping and image localization.
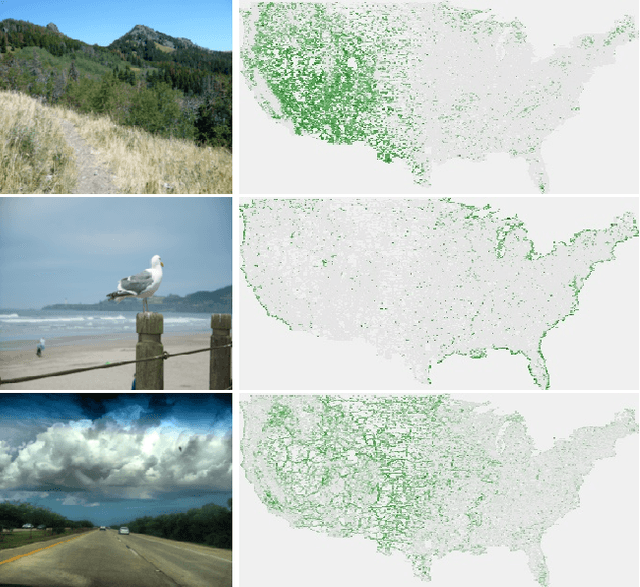
What Goes Where: Predicting Object Distributions from Above
Aug 02, 2018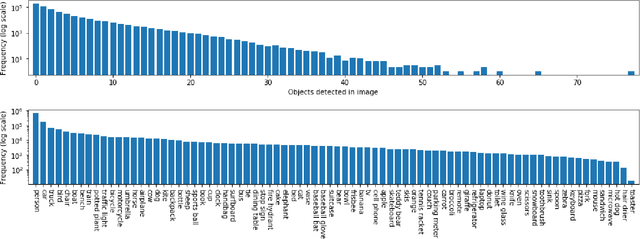

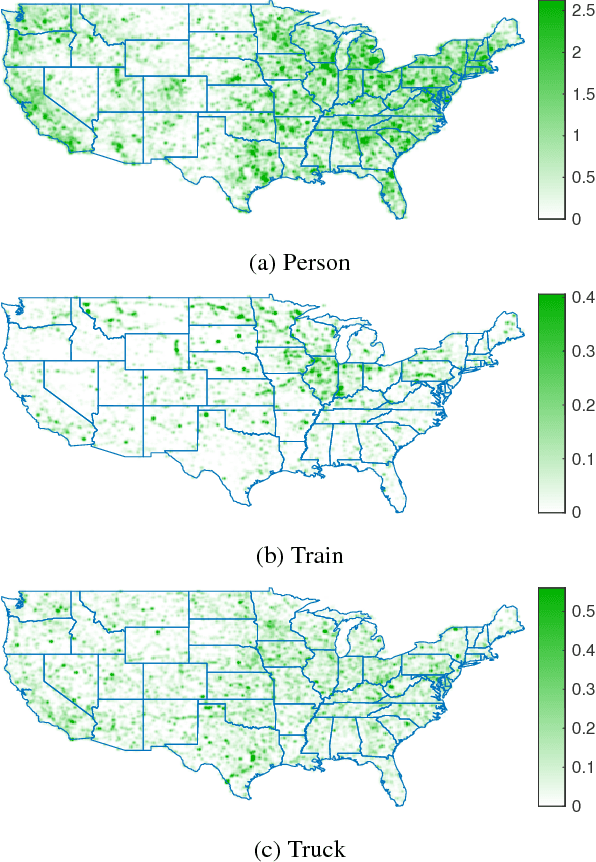
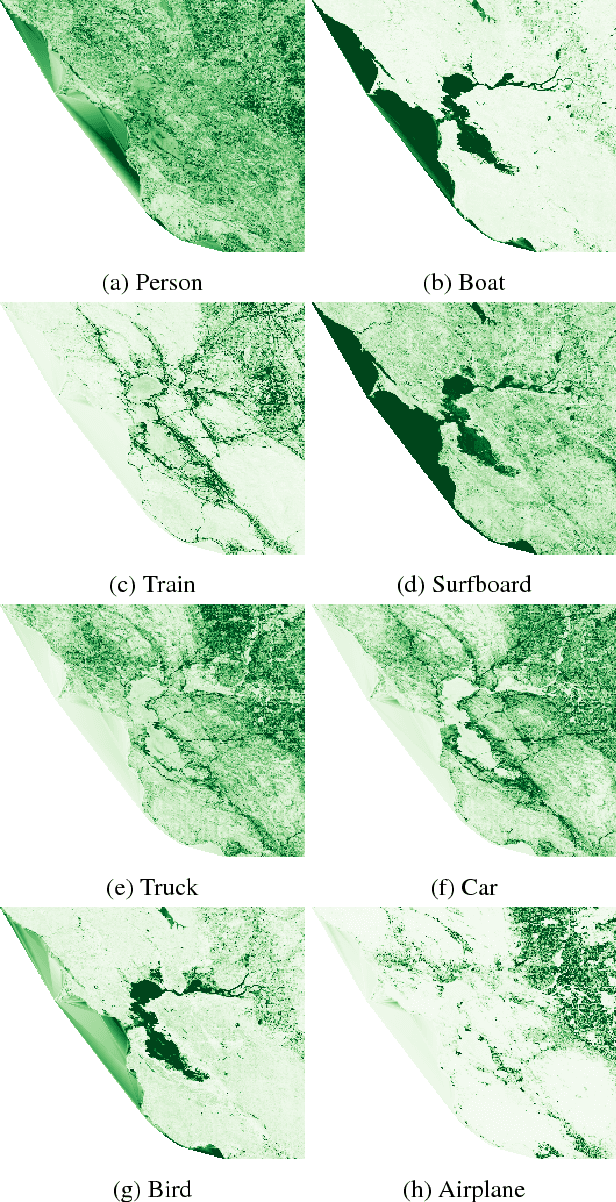
In this work, we propose a cross-view learning approach, in which images captured from a ground-level view are used as weakly supervised annotations for interpreting overhead imagery. The outcome is a convolutional neural network for overhead imagery that is capable of predicting the type and count of objects that are likely to be seen from a ground-level perspective. We demonstrate our approach on a large dataset of geotagged ground-level and overhead imagery and find that our network captures semantically meaningful features, despite being trained without manual annotations.