 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Trajectory Optimization with Parallelized Differentiable Traffic Simulation
Dec 21, 2024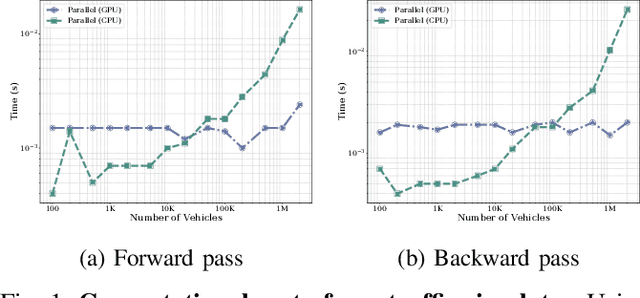
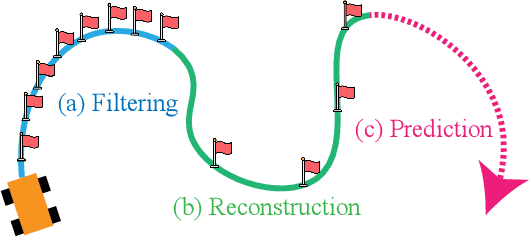
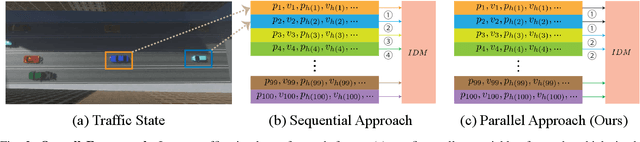

We present a parallelized differentiable traffic simulator based on the Intelligent Driver Model (IDM), a car-following framework that incorporates driver behavior as key variables. Our simulator efficiently models vehicle motion, generating trajectories that can be supervised to fit real-world data. By leveraging its differentiable nature, IDM parameters are optimized using gradient-based methods. With the capability to simulate up to 2 million vehicles in real time, the system is scalable for large-scale trajectory optimization. We show that we can use the simulator to filter noise in the input trajectories (trajectory filtering), reconstruct dense trajectories from sparse ones (trajectory reconstruction), and predict future trajectories (trajectory prediction), with all generated trajectories adhering to physical laws. We validate our simulator and algorithm on several datasets including NGSIM and Waymo Open Dataset.
Deep Stochastic Kinematic Models for Probabilistic Motion Forecasting in Traffic
Jun 03, 2024



Kinematic priors have shown to be helpful in boosting generalization and performance in prior work on trajectory forecasting. Specifically, kinematic priors have been applied such that models predict a set of actions instead of future output trajectories. By unrolling predicted trajectories via time integration and models of kinematic dynamics, predicted trajectories are not only kinematically feasible on average but also relate uncertainty from one timestep to the next. With benchmarks supporting prediction of multiple trajectory predictions, deterministic kinematic priors are less and less applicable to current models. We propose a method for integrating probabilistic kinematic priors into modern probabilistic trajectory forecasting architectures. The primary difference between our work and previous techniques is the analytical quantification of variance, or uncertainty, in predicted trajectories. With negligible additional computational overhead, our method can be generalized and easily implemented with any modern probabilistic method that models candidate trajectories as Gaussian distributions. In particular, our method works especially well in unoptimal settings, such as with small datasets or in the presence of noise. Our method achieves up to a 50% performance boost in small dataset settings and up to an 8% performance boost in large-scale learning compared to previous kinematic prediction methods on SOTA trajectory forecasting architectures out-of-the-box, with minimal fine-tuning. In this paper, we show four analytical formulations of probabilistic kinematic priors which can be used for any Gaussian Mixture Model (GMM)-based deep learning models, quantify the error bound on linear approximations applied during trajectory unrolling, and show results to evaluate each formulation in trajectory forecasting.
xFBD: Focused Building Damage Dataset and Analysis
Jan 03, 2023



The xView2 competition and xBD dataset spurred significant advancements in overhead building damage detection, but the competition's pixel level scoring can lead to reduced solution performance in areas with tight clusters of buildings or uninformative context. We seek to advance automatic building damage assessment for disaster relief by proposing an auxiliary challenge to the original xView2 competition. This new challenge involves a new dataset and metrics indicating solution performance when damage is more local and limited than in xBD. Our challenge measures a network's ability to identify individual buildings and their damage level without excessive reliance on the buildings' surroundings. Methods that succeed on this challenge will provide more fine-grained, precise damage information than original xView2 solutions. The best-performing xView2 networks' performances dropped noticeably in our new limited/local damage detection task. The common causes of failure observed are that (1) building objects and their classifications are not separated well, and (2) when they are, the classification is strongly biased by surrounding buildings and other damage context. Thus, we release our augmented version of the dataset with additional object-level scoring metrics https://gitlab.kitware.com/dennis.melamed/xfbd to test independence and separability of building objects, alongside the pixel-level performance metrics of the original competition. We also experiment with new baseline models which improve independence and separability of building damage predictions. Our results indicate that building damage detection is not a fully-solved problem, and we invite others to use and build on our dataset augmentations and metrics.
Scale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning
Jan 02, 2023
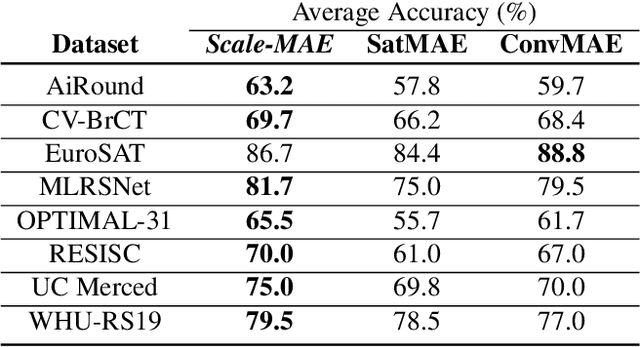
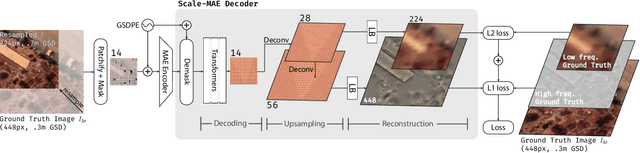

Remote sensing imagery provides comprehensive views of the Earth, where different sensors collect complementary data at different spatial scales. Large, pretrained models are commonly finetuned with imagery that is heavily augmented to mimic different conditions and scales, with the resulting models used for various tasks with imagery from a range of spatial scales. Such models overlook scale-specific information in the data. In this paper, we present Scale-MAE, a pretraining method that explicitly learns relationships between data at different, known scales throughout the pretraining process. Scale-MAE pretrains a network by masking an input image at a known input scale, where the area of the Earth covered by the image determines the scale of the ViT positional encoding, not the image resolution. Scale-MAE encodes the masked image with a standard ViT backbone, and then decodes the masked image through a bandpass filter to reconstruct low/high frequency images at lower/higher scales. We find that tasking the network with reconstructing both low/high frequency images leads to robust multiscale representations for remote sensing imagery. Scale-MAE achieves an average of a $5.0\%$ non-parametric kNN classification improvement across eight remote sensing datasets compared to current state-of-the-art and obtains a $0.9$ mIoU to $3.8$ mIoU improvement on the SpaceNet building segmentation transfer task for a range of evaluation scales.
MEVID: Multi-view Extended Videos with Identities for Video Person Re-Identification
Nov 10, 2022In this paper, we present the Multi-view Extended Videos with Identities (MEVID) dataset for large-scale, video person re-identification (ReID) in the wild. To our knowledge, MEVID represents the most-varied video person ReID dataset, spanning an extensive indoor and outdoor environment across nine unique dates in a 73-day window, various camera viewpoints, and entity clothing changes. Specifically, we label the identities of 158 unique people wearing 598 outfits taken from 8, 092 tracklets, average length of about 590 frames, seen in 33 camera views from the very large-scale MEVA person activities dataset. While other datasets have more unique identities, MEVID emphasizes a richer set of information about each individual, such as: 4 outfits/identity vs. 2 outfits/identity in CCVID, 33 viewpoints across 17 locations vs. 6 in 5 simulated locations for MTA, and 10 million frames vs. 3 million for LS-VID. Being based on the MEVA video dataset, we also inherit data that is intentionally demographically balanced to the continental United States. To accelerate the annotation process, we developed a semi-automatic annotation framework and GUI that combines state-of-the-art real-time models for object detection, pose estimation, person ReID, and multi-object tracking. We evaluate several state-of-the-art methods on MEVID challenge problems and comprehensively quantify their robustness in terms of changes of outfit, scale, and background location. Our quantitative analysis on the realistic, unique aspects of MEVID shows that there are significant remaining challenges in video person ReID and indicates important directions for future research.
Cascade Transformers for End-to-End Person Search
Mar 17, 2022
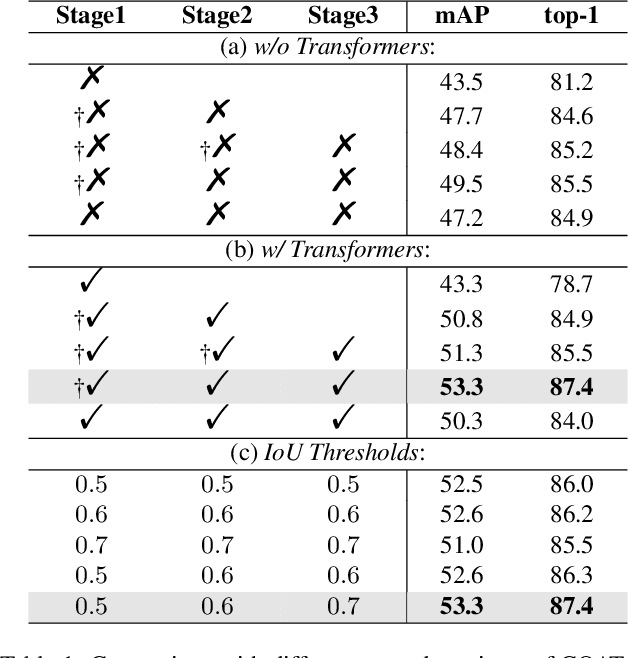
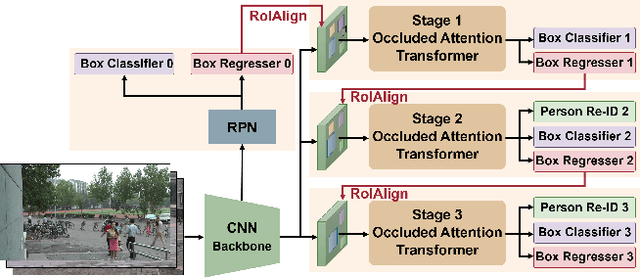
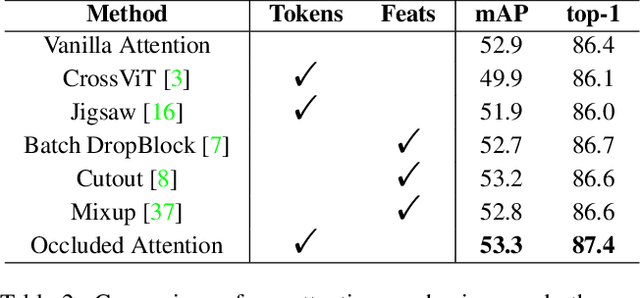
The goal of person search is to localize a target person from a gallery set of scene images, which is extremely challenging due to large scale variations, pose/viewpoint changes, and occlusions. In this paper, we propose the Cascade Occluded Attention Transformer (COAT) for end-to-end person search. Our three-stage cascade design focuses on detecting people in the first stage, while later stages simultaneously and progressively refine the representation for person detection and re-identification. At each stage the occluded attention transformer applies tighter intersection over union thresholds, forcing the network to learn coarse-to-fine pose/scale invariant features. Meanwhile, we calculate each detection's occluded attention to differentiate a person's tokens from other people or the background. In this way, we simulate the effect of other objects occluding a person of interest at the token-level. Through comprehensive experiments, we demonstrate the benefits of our method by achieving state-of-the-art performance on two benchmark datasets.