 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Transformers for End-to-End Person Search
Mar 17, 2022
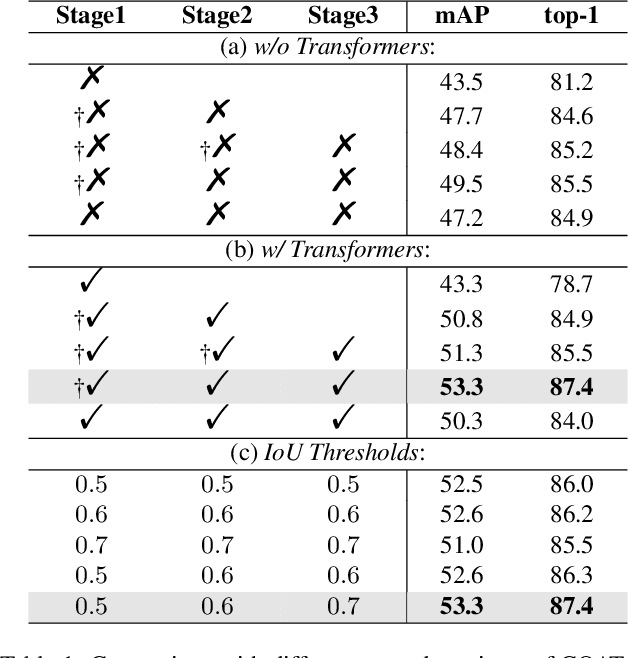
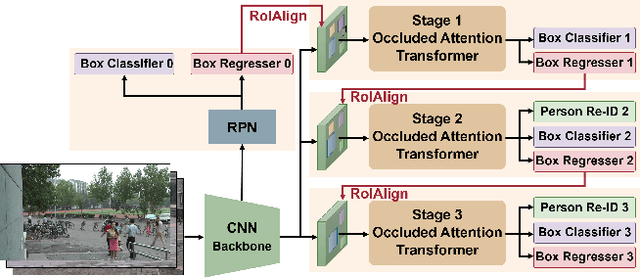
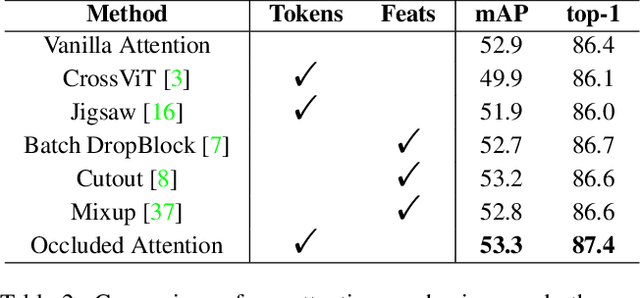
The goal of person search is to localize a target person from a gallery set of scene images, which is extremely challenging due to large scale variations, pose/viewpoint changes, and occlusions. In this paper, we propose the Cascade Occluded Attention Transformer (COAT) for end-to-end person search. Our three-stage cascade design focuses on detecting people in the first stage, while later stages simultaneously and progressively refine the representation for person detection and re-identification. At each stage the occluded attention transformer applies tighter intersection over union thresholds, forcing the network to learn coarse-to-fine pose/scale invariant features. Meanwhile, we calculate each detection's occluded attention to differentiate a person's tokens from other people or the background. In this way, we simulate the effect of other objects occluding a person of interest at the token-level. Through comprehensive experiments, we demonstrate the benefits of our method by achieving state-of-the-art performance on two benchmark datasets.
Capsules for Biomedical Image Segmentation
Apr 09, 2020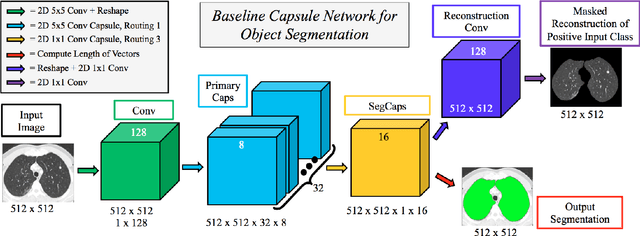
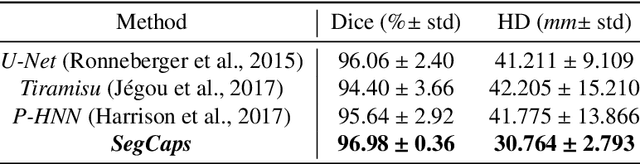
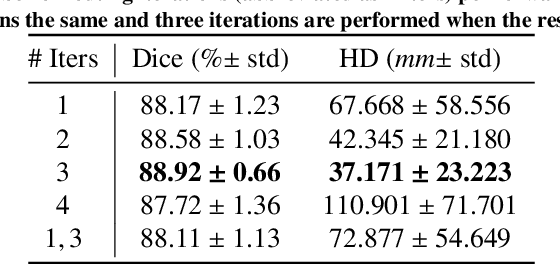

Our work expands the use of capsule networks to the task of object segmentation for the first time in the literature. This is made possible via the introduction of locally-constrained routing and transformation matrix sharing, which reduces the parameter/memory burden and allows for the segmentation of objects at large resolutions. To compensate for the loss of global information in constraining the routing, we propose the concept of "deconvolutional" capsules to create a deep encoder-decoder style network, called SegCaps. We extend the masked reconstruction regularization to the task of segmentation and perform thorough ablation experiments on each component of our method. The proposed convolutional-deconvolutional capsule network, SegCaps, shows state-of-the-art results while using a fraction of the parameters of popular segmentation networks. To validate our proposed method, we perform the largest-scale study in pathological lung segmentation in the literature, where we conduct experiments across five extremely challenging datasets, containing both clinical and pre-clinical subjects, and nearly 2000 computed-tomography scans. Our newly developed segmentation platform outperforms other methods across all datasets while utilizing 95% fewer parameters than the popular U-Net for biomedical image segmentation. We also provide proof-of-concept results on thin, tree-like structures in retinal imagery as well as demonstrate capsules' handling of rotations/reflections on natural images.
Diagnosing Colorectal Polyps in the Wild with Capsule Networks
Jan 10, 2020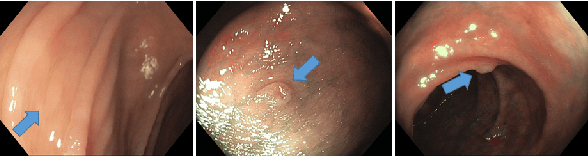
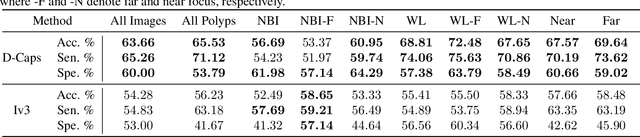
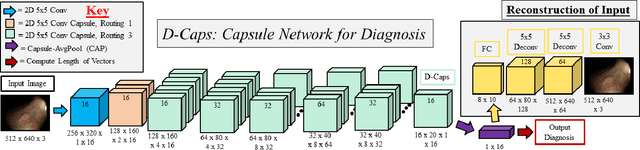
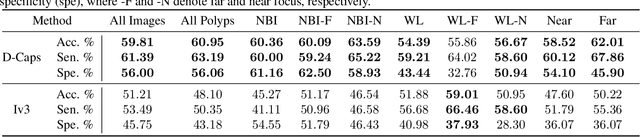
Colorectal cancer, largely arising from precursor lesions called polyps, remains one of the leading causes of cancer-related death worldwide. Current clinical standards require the resection and histopathological analysis of polyps due to test accuracy and sensitivity of optical biopsy methods falling substantially below recommended levels. In this study, we design a novel capsule network architecture (D-Caps) to improve the viability of optical biopsy of colorectal polyps. Our proposed method introduces several technical novelties including a novel capsule architecture with a capsule-average pooling (CAP) method to improve efficiency in large-scale image classification. We demonstrate improved results over the previous state-of-the-art convolutional neural network (CNN) approach by as much as 43%. This work provides an important benchmark on the new Mayo Polyp dataset, a significantly more challenging and larger dataset than previous polyp studies, with results stratified across all available categories, imaging devices and modalities, and focus modes to promote future direction into AI-driven colorectal cancer screening systems. Code is publicly available at https://github.com/lalonderodney/D-Caps .
Encoding High-Level Visual Attributes in Capsules for Explainable Medical Diagnoses
Sep 12, 2019
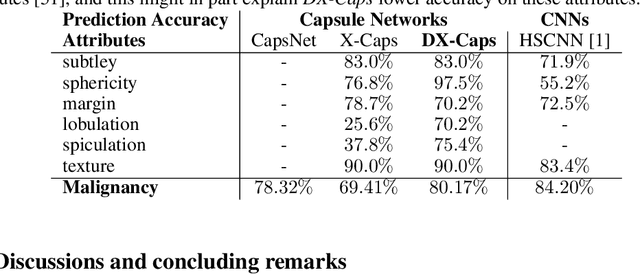
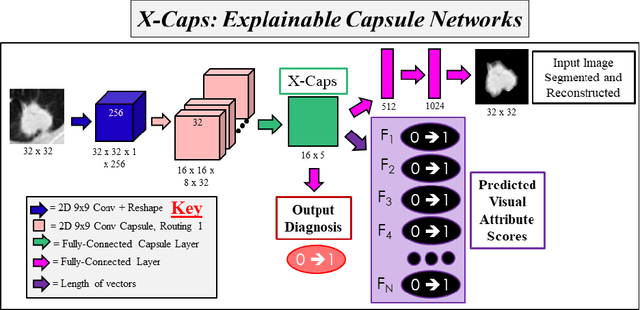
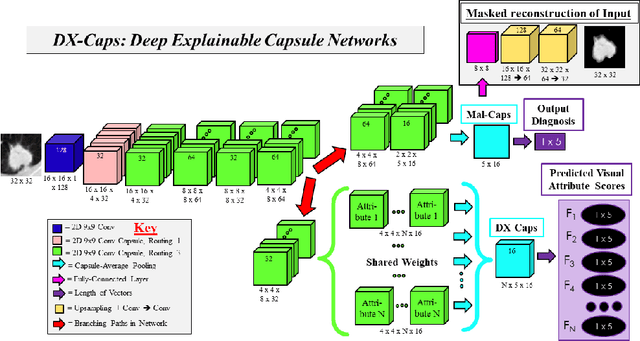
Deep neural networks are often called black-boxes due to their difficult-to-interpret decisions. This is characteristic of a deeper trend in machine learning, where predictive performance typically comes at the cost of interpretability. In some domains, such as image-based diagnostic tasks, understanding the reasons behind machine generated predictions is vital in assessing trust. In this study, we introduce novel designs of capsule networks to provide explainable diagnoses. Our proposed deep explainable capsule architecture, called DX-Caps, can encode high-level visual attributes within the vectors of capsules in order to simultaneously produce malignancy predictions for lung cancer as well as approximations of six visually-interpretable attributes, used by radiologists to explain their predictions. To reduce parameter and memory burden of this deeper network, we introduce a new capsule-average pooling function. With this simple, but fundamental addition, capsule networks can be designed in a deeper fashion than was possible before. Our overall approach can be characterized as multi-task learning; we learn to approximate the six high-level visual attributes of a lung nodule within the vectors of our uniquely constructed deep capsule network, while simultaneously segmenting the nodule and predicting its malignancy potential (diagnosis). Tested on over 1000 CT scans, our experimental results show that our proposed algorithm can approximate the visual attributes of lung nodules far better than a deep multi-path dense 3D CNN. The proposed network also achieves higher diagnostic accuracy than a baseline explainable capsule network X-Caps and CapsNet when applied to this task for the first time as well. To the best of our knowledge, this is the first study to investigate capsule networks for visual attribute prediction in general, and explainable medical image diagnosis in particular.
INN: Inflated Neural Networks for IPMN Diagnosis
Jun 30, 2019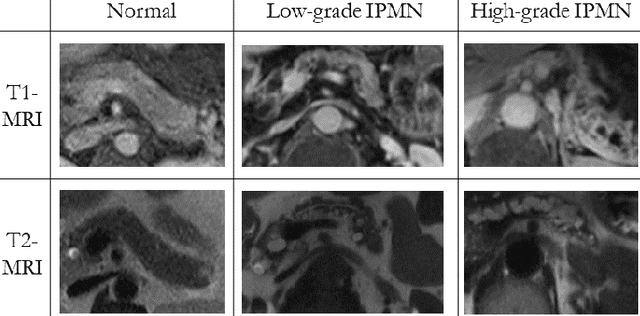
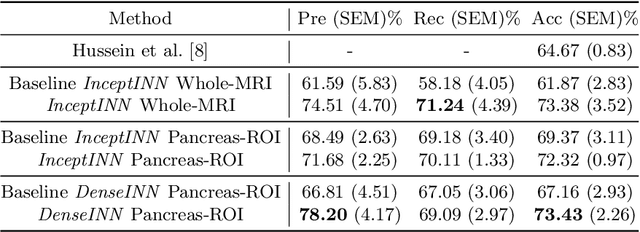
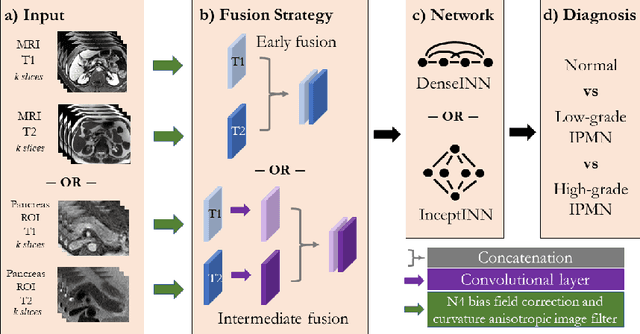
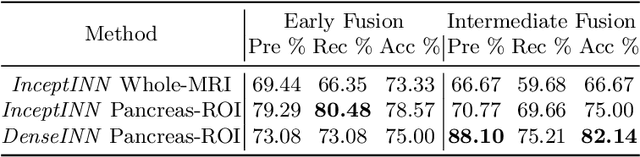
Intraductal papillary mucinous neoplasm (IPMN) is a precursor to pancreatic ductal adenocarcinoma. While over half of patients are diagnosed with pancreatic cancer at a distant stage, patients who are diagnosed early enjoy a much higher 5-year survival rate of $34\%$ compared to $3\%$ in the former; hence, early diagnosis is key. Unique challenges in the medical imaging domain such as extremely limited annotated data sets and typically large 3D volumetric data have made it difficult for deep learning to secure a strong foothold. In this work, we construct two novel "inflated" deep network architectures, $\textit{InceptINN}$ and $\textit{DenseINN}$, for the task of diagnosing IPMN from multisequence (T1 and T2) MRI. These networks inflate their 2D layers to 3D and bootstrap weights from their 2D counterparts (Inceptionv3 and DenseNet121 respectively) trained on ImageNet to the new 3D kernels. We also extend the inflation process by further expanding the pre-trained kernels to handle any number of input modalities and different fusion strategies. This is one of the first studies to train an end-to-end deep network on multisequence MRI for IPMN diagnosis, and shows that our proposed novel inflated network architectures are able to handle the extremely limited training data (139 MRI scans), while providing an absolute improvement of $8.76\%$ in accuracy for diagnosing IPMN over the current state-of-the-art. Code is publicly available at https://github.com/lalonderodney/INN-Inflated-Neural-Nets.
Capsules for Object Segmentation
Apr 11, 2018
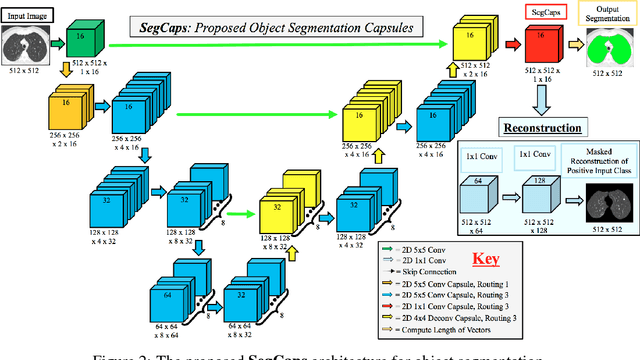


Convolutional neural networks (CNNs) have shown remarkable results over the last several years for a wide range of computer vision tasks. A new architecture recently introduced by Sabour et al., referred to as a capsule networks with dynamic routing, has shown great initial results for digit recognition and small image classification. The success of capsule networks lies in their ability to preserve more information about the input by replacing max-pooling layers with convolutional strides and dynamic routing, allowing for preservation of part-whole relationships in the data. This preservation of the input is demonstrated by reconstructing the input from the output capsule vectors. Our work expands the use of capsule networks to the task of object segmentation for the first time in the literature. We extend the idea of convolutional capsules with locally-connected routing and propose the concept of deconvolutional capsules. Further, we extend the masked reconstruction to reconstruct the positive input class. The proposed convolutional-deconvolutional capsule network, called SegCaps, shows strong results for the task of object segmentation with substantial decrease in parameter space. As an example application, we applied the proposed SegCaps to segment pathological lungs from low dose CT scans and compared its accuracy and efficiency with other U-Net-based architectures. SegCaps is able to handle large image sizes (512 x 512) as opposed to baseline capsules (typically less than 32 x 32). The proposed SegCaps reduced the number of parameters of U-Net architecture by 95.4% while still providing a better segmentation accuracy.
ClusterNet: Detecting Small Objects in Large Scenes by Exploiting Spatio-Temporal Information
Dec 04, 2017



Object detection in wide area motion imagery (WAMI) has drawn the attention of the computer vision research community for a number of years. WAMI proposes a number of unique challenges including extremely small object sizes, both sparse and densely-packed objects, and extremely large search spaces (large video frames). Nearly all state-of-the-art methods in WAMI object detection report that appearance-based classifiers fail in this challenging data and instead rely almost entirely on motion information in the form of background subtraction or frame-differencing. In this work, we experimentally verify the failure of appearance-based classifiers in WAMI, such as Faster R-CNN and a heatmap-based fully convolutional neural network (CNN), and propose a novel two-stage spatio-temporal CNN which effectively and efficiently combines both appearance and motion information to significantly surpass the state-of-the-art in WAMI object detection. To reduce the large search space, the first stage (ClusterNet) takes in a set of extremely large video frames, combines the motion and appearance information within the convolutional architecture, and proposes regions of objects of interest (ROOBI). These ROOBI can contain from one to clusters of several hundred objects due to the large video frame size and varying object density in WAMI. The second stage (FoveaNet) then estimates the centroid location of all objects in that given ROOBI simultaneously via heatmap estimation. The proposed method exceeds state-of-the-art results on the WPAFB 2009 dataset by 5-16% for moving objects and nearly 50% for stopped objects, as well as being the first proposed method in wide area motion imagery to detect completely stationary objects.