 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEVID: Multi-view Extended Videos with Identities for Video Person Re-Identification
Nov 10, 2022In this paper, we present the Multi-view Extended Videos with Identities (MEVID) dataset for large-scale, video person re-identification (ReID) in the wild. To our knowledge, MEVID represents the most-varied video person ReID dataset, spanning an extensive indoor and outdoor environment across nine unique dates in a 73-day window, various camera viewpoints, and entity clothing changes. Specifically, we label the identities of 158 unique people wearing 598 outfits taken from 8, 092 tracklets, average length of about 590 frames, seen in 33 camera views from the very large-scale MEVA person activities dataset. While other datasets have more unique identities, MEVID emphasizes a richer set of information about each individual, such as: 4 outfits/identity vs. 2 outfits/identity in CCVID, 33 viewpoints across 17 locations vs. 6 in 5 simulated locations for MTA, and 10 million frames vs. 3 million for LS-VID. Being based on the MEVA video dataset, we also inherit data that is intentionally demographically balanced to the continental United States. To accelerate the annotation process, we developed a semi-automatic annotation framework and GUI that combines state-of-the-art real-time models for object detection, pose estimation, person ReID, and multi-object tracking. We evaluate several state-of-the-art methods on MEVID challenge problems and comprehensively quantify their robustness in terms of changes of outfit, scale, and background location. Our quantitative analysis on the realistic, unique aspects of MEVID shows that there are significant remaining challenges in video person ReID and indicates important directions for future research.
Cascade Transformers for End-to-End Person Search
Mar 17, 2022
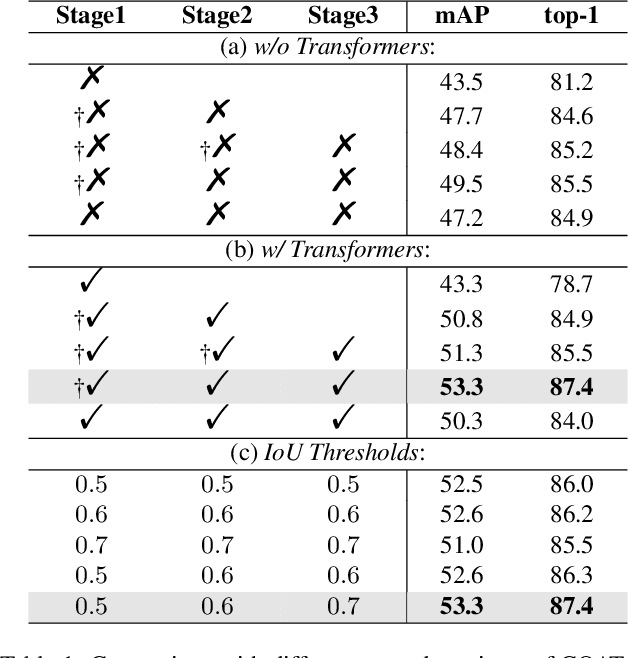
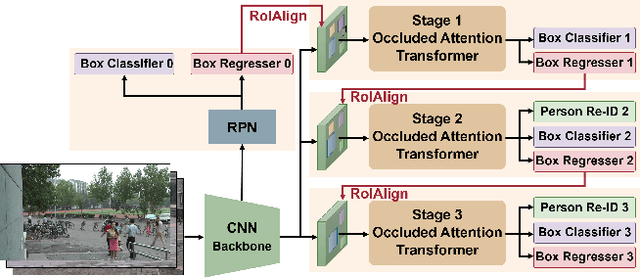
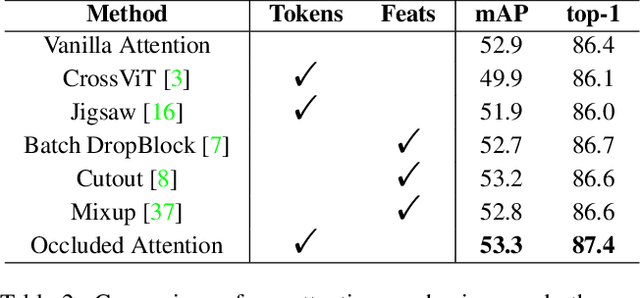
The goal of person search is to localize a target person from a gallery set of scene images, which is extremely challenging due to large scale variations, pose/viewpoint changes, and occlusions. In this paper, we propose the Cascade Occluded Attention Transformer (COAT) for end-to-end person search. Our three-stage cascade design focuses on detecting people in the first stage, while later stages simultaneously and progressively refine the representation for person detection and re-identification. At each stage the occluded attention transformer applies tighter intersection over union thresholds, forcing the network to learn coarse-to-fine pose/scale invariant features. Meanwhile, we calculate each detection's occluded attention to differentiate a person's tokens from other people or the background. In this way, we simulate the effect of other objects occluding a person of interest at the token-level. Through comprehensive experiments, we demonstrate the benefits of our method by achieving state-of-the-art performance on two benchmark datasets.
ADAPT: An Open-Source sUAS Payload for Real-Time Disaster Prediction and Response with AI
Jan 25, 2022
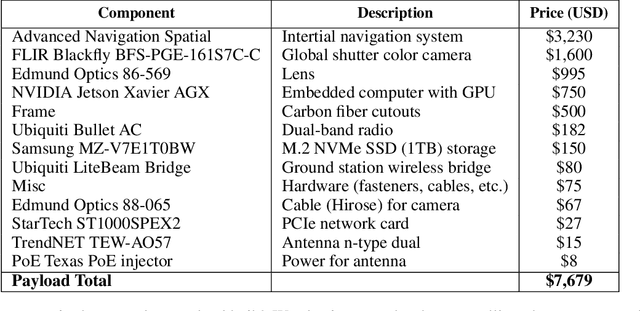

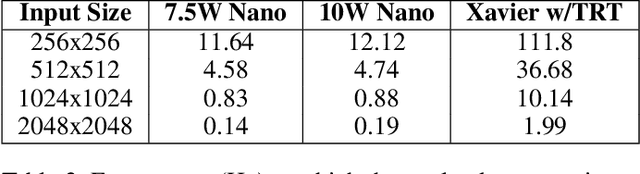
Small unmanned aircraft systems (sUAS) are becoming prominent components of many humanitarian assistance and disaster response (HADR) operations. Pairing sUAS with onboard artificial intelligence (AI) substantially extends their utility in covering larger areas with fewer support personnel. A variety of missions, such as search and rescue, assessing structural damage, and monitoring forest fires, floods, and chemical spills, can be supported simply by deploying the appropriate AI models. However, adoption by resource-constrained groups, such as local municipalities, regulatory agencies, and researchers, has been hampered by the lack of a cost-effective, readily-accessible baseline platform that can be adapted to their unique missions. To fill this gap, we have developed the free and open-source ADAPT multi-mission payload for deploying real-time AI and computer vision onboard a sUAS during local and beyond-line-of-site missions. We have emphasized a modular design with low-cost, readily-available components, open-source software, and thorough documentation (https://kitware.github.io/adapt/). The system integrates an inertial navigation system, high-resolution color camera, computer, and wireless downlink to process imagery and broadcast georegistered analytics back to a ground station. Our goal is to make it easy for the HADR community to build their own copies of the ADAPT payload and leverage the thousands of hours of engineering we have devoted to developing and testing. In this paper, we detail the development and testing of the ADAPT payload. We demonstrate the example mission of real-time, in-flight ice segmentation to monitor river ice state and provide timely predictions of catastrophic flooding events. We deploy a novel active learning workflow to annotate river ice imagery, train a real-time deep neural network for ice segmentation, and demonstrate operation in the field.