 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEARN: A Unified Framework for Multi-Task Domain Adapt Few-Shot Learning
Dec 20, 2024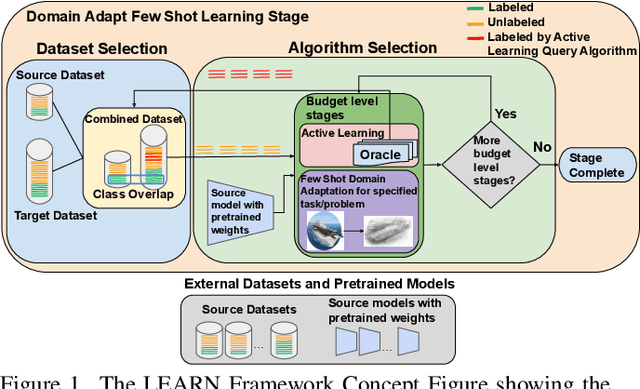
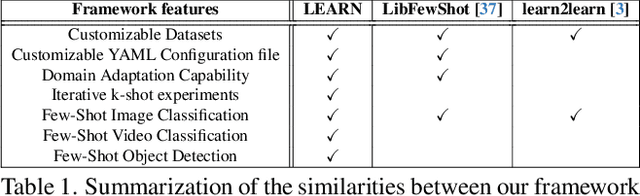
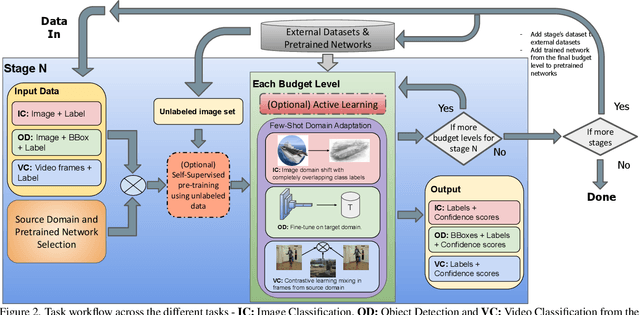
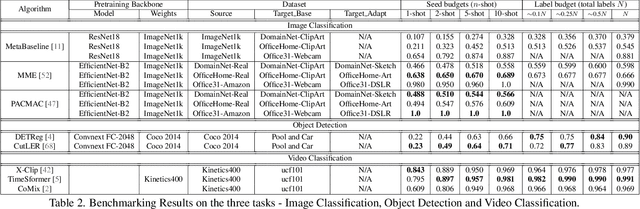
Both few-shot learning and domain adaptation sub-fields in Computer Vision have seen significant recent progress in terms of the availability of state-of-the-art algorithms and datasets. Frameworks have been developed for each sub-field; however, building a common system or framework that combines both is something that has not been explored. As part of our research, we present the first unified framework that combines domain adaptation for the few-shot learning setting across 3 different tasks - image classification, object detection and video classification. Our framework is highly modular with the capability to support few-shot learning with/without the inclusion of domain adaptation depending on the algorithm. Furthermore, the most important configurable feature of our framework is the on-the-fly setup for incremental $n$-shot tasks with the optional capability to configure the system to scale to a traditional many-shot task. With more focus on Self-Supervised Learning (SSL) for current few-shot learning approaches, our system also supports multiple SSL pre-training configurations. To test our framework's capabilities, we provide benchmarks on a wide range of algorithms and datasets across different task and problem settings. The code is open source has been made publicly available here: https://gitlab.kitware.com/darpa_learn/learn
Scale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning
Jan 02, 2023
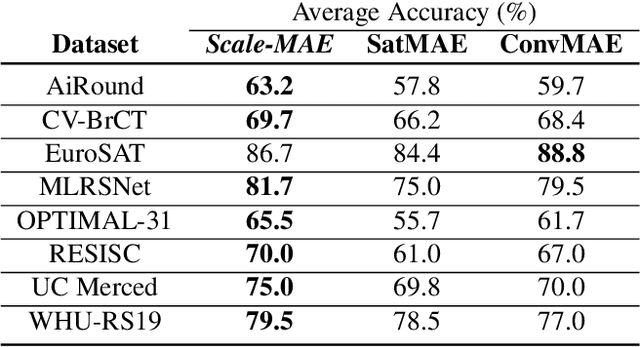
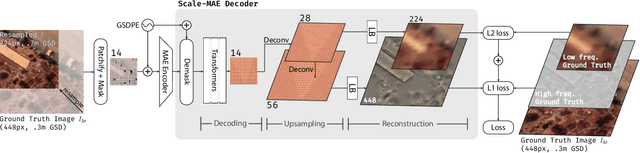

Remote sensing imagery provides comprehensive views of the Earth, where different sensors collect complementary data at different spatial scales. Large, pretrained models are commonly finetuned with imagery that is heavily augmented to mimic different conditions and scales, with the resulting models used for various tasks with imagery from a range of spatial scales. Such models overlook scale-specific information in the data. In this paper, we present Scale-MAE, a pretraining method that explicitly learns relationships between data at different, known scales throughout the pretraining process. Scale-MAE pretrains a network by masking an input image at a known input scale, where the area of the Earth covered by the image determines the scale of the ViT positional encoding, not the image resolution. Scale-MAE encodes the masked image with a standard ViT backbone, and then decodes the masked image through a bandpass filter to reconstruct low/high frequency images at lower/higher scales. We find that tasking the network with reconstructing both low/high frequency images leads to robust multiscale representations for remote sensing imagery. Scale-MAE achieves an average of a $5.0\%$ non-parametric kNN classification improvement across eight remote sensing datasets compared to current state-of-the-art and obtains a $0.9$ mIoU to $3.8$ mIoU improvement on the SpaceNet building segmentation transfer task for a range of evaluation scales.