 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Near/Remote Sensing with Geospatial Attention
Apr 04, 2022



This work addresses the task of overhead image segmentation when auxiliary ground-level images are available. Recent work has shown that performing joint inference over these two modalities, often called near/remote sensing, can yield significant accuracy improvements. Extending this line of work, we introduce the concept of geospatial attention, a geometry-aware attention mechanism that explicitly considers the geospatial relationship between the pixels in a ground-level image and a geographic location. We propose an approach for computing geospatial attention that incorporates geometric features and the appearance of the overhead and ground-level imagery. We introduce a novel architecture for near/remote sensing that is based on geospatial attention and demonstrate its use for five segmentation tasks. The results demonstrate that our method significantly outperforms the previous state-of-the-art methods.
Augmenting Depth Estimation with Geospatial Context
Sep 20, 2021



Modern cameras are equipped with a wide array of sensors that enable recording the geospatial context of an image. Taking advantage of this, we explore depth estimation under the assumption that the camera is geocalibrated, a problem we refer to as geo-enabled depth estimation. Our key insight is that if capture location is known, the corresponding overhead viewpoint offers a valuable resource for understanding the scale of the scene. We propose an end-to-end architecture for depth estimation that uses geospatial context to infer a synthetic ground-level depth map from a co-located overhead image, then fuses it inside of an encoder/decoder style segmentation network. To support evaluation of our methods, we extend a recently released dataset with overhead imagery and corresponding height maps. Results demonstrate that integrating geospatial context significantly reduces error compared to baselines, both at close ranges and when evaluating at much larger distances than existing benchmarks consider.
A Structure-Aware Method for Direct Pose Estimation
Dec 22, 2020
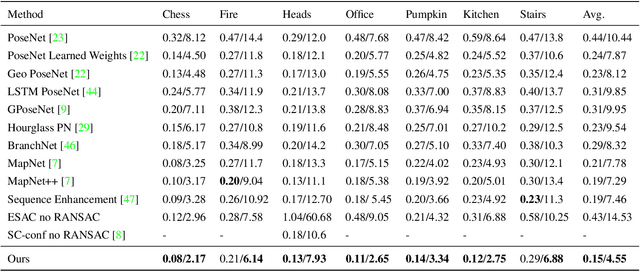

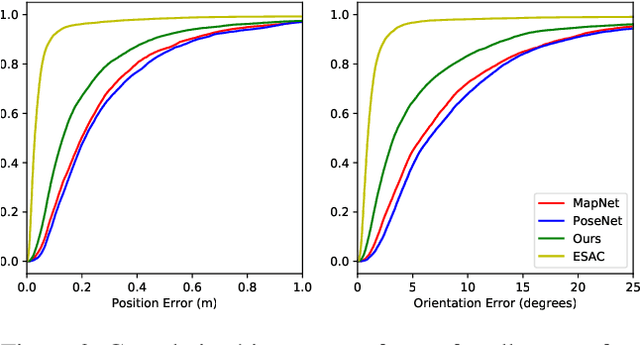
Estimating camera pose from a single image is a fundamental problem in computer vision. Existing methods for solving this task fall into two distinct categories, which we refer to as direct and indirect. Direct methods, such as PoseNet, regress pose from the image as a fixed function, for example using a feed-forward convolutional network. Such methods are desirable because they are deterministic and run in constant time. Indirect methods for pose regression are often non-deterministic, with various external dependencies such as image retrieval and hypothesis sampling. We propose a direct method that takes inspiration from structure-based approaches to incorporate explicit 3D constraints into the network. Our approach maintains the desirable qualities of other direct methods while achieving much lower error in general.
Dynamic Image for 3D MRI Image Alzheimer's Disease Classification
Nov 30, 2020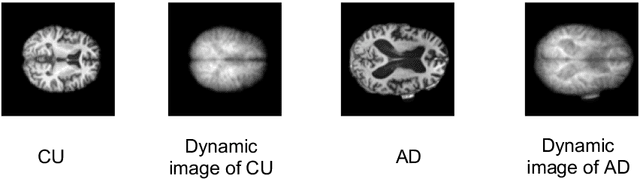
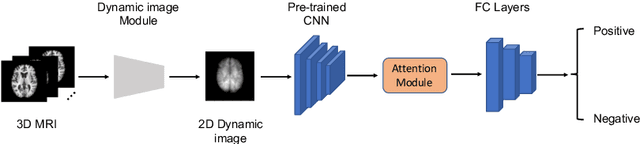
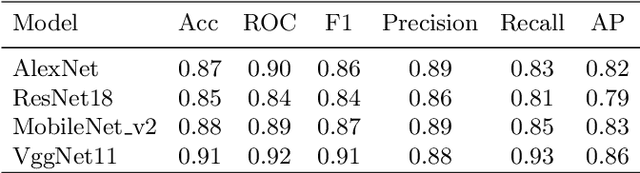
We propose to apply a 2D CNN architecture to 3D MRI image Alzheimer's disease classification. Training a 3D convolutional neural network (CNN) is time-consuming and computationally expensive. We make use of approximate rank pooling to transform the 3D MRI image volume into a 2D image to use as input to a 2D CNN. We show our proposed CNN model achieves $9.5\%$ better Alzheimer's disease classification accuracy than the baseline 3D models. We also show that our method allows for efficient training, requiring only 20% of the training time compared to 3D CNN models. The code is available online: https://github.com/UkyVision/alzheimer-project.
Single Image Cloud Detection via Multi-Image Fusion
Jul 29, 2020



Artifacts in imagery captured by remote sensing, such as clouds, snow, and shadows, present challenges for various tasks, including semantic segmentation and object detection. A primary challenge in developing algorithms for identifying such artifacts is the cost of collecting annotated training data. In this work, we explore how recent advances in multi-image fusion can be leveraged to bootstrap single image cloud detection. We demonstrate that a network optimized to estimate image quality also implicitly learns to detect clouds. To support the training and evaluation of our approach, we collect a large dataset of Sentinel-2 images along with a per-pixel semantic labelling for land cover. Through various experiments, we demonstrate that our method reduces the need for annotated training data and improves cloud detection performance.
RasterNet: Modeling Free-Flow Speed using LiDAR and Overhead Imagery
Jun 14, 2020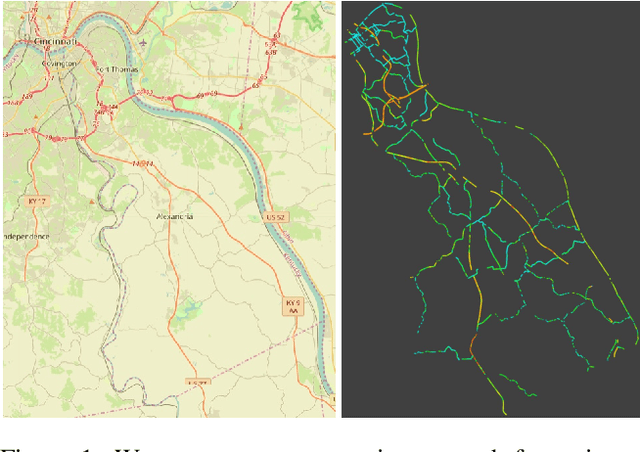
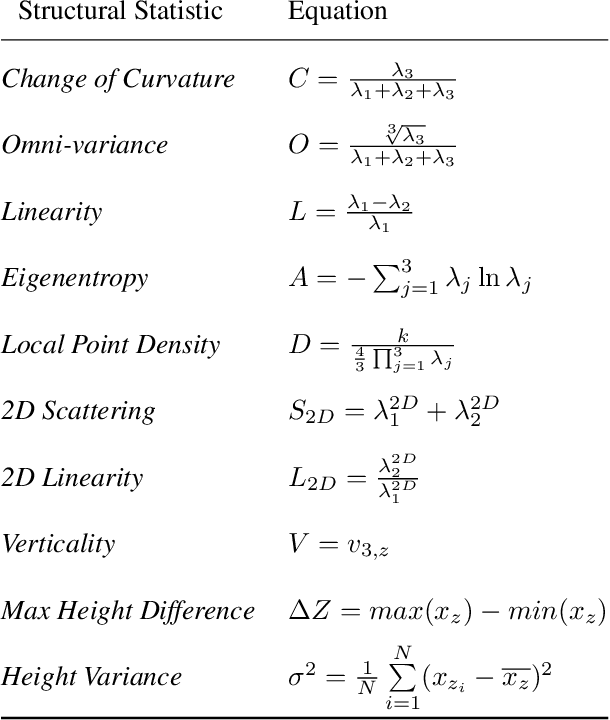


Roadway free-flow speed captures the typical vehicle speed in low traffic conditions. Modeling free-flow speed is an important problem in transportation engineering with applications to a variety of design, operation, planning, and policy decisions of highway systems. Unfortunately, collecting large-scale historical traffic speed data is expensive and time consuming. Traditional approaches for estimating free-flow speed use geometric properties of the underlying road segment, such as grade, curvature, lane width, lateral clearance and access point density, but for many roads such features are unavailable. We propose a fully automated approach, RasterNet, for estimating free-flow speed without the need for explicit geometric features. RasterNet is a neural network that fuses large-scale overhead imagery and aerial LiDAR point clouds using a geospatially consistent raster structure. To support training and evaluation, we introduce a novel dataset combining free-flow speeds of road segments, overhead imagery, and LiDAR point clouds across the state of Kentucky. Our method achieves state-of-the-art results on a benchmark dataset.
Joint 2D-3D Breast Cancer Classification
Feb 27, 2020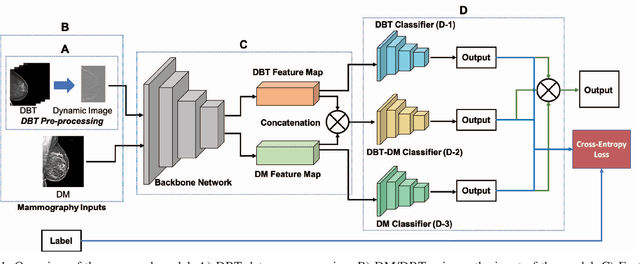
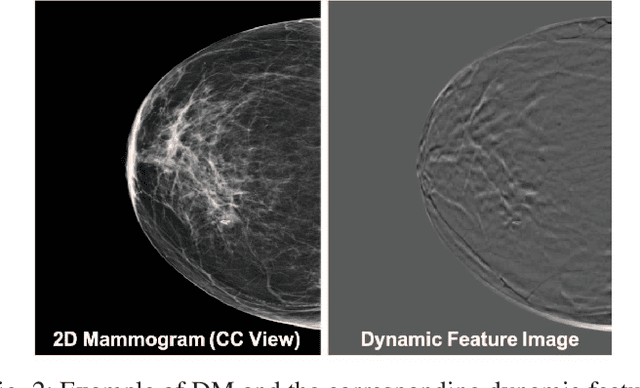
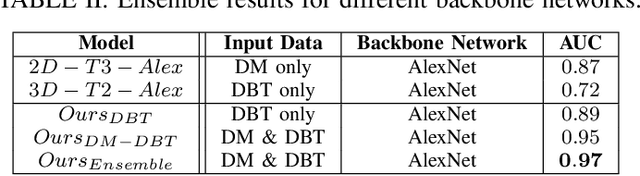

Breast cancer is the malignant tumor that causes the highest number of cancer deaths in females. Digital mammograms (DM or 2D mammogram) and digital breast tomosynthesis (DBT or 3D mammogram) are the two types of mammography imagery that are used in clinical practice for breast cancer detection and diagnosis. Radiologists usually read both imaging modalities in combination; however, existing computer-aided diagnosis tools are designed using only one imaging modality. Inspired by clinical practice, we propose an innovative convolutional neural network (CNN) architecture for breast cancer classification, which uses both 2D and 3D mammograms, simultaneously. Our experiment shows that the proposed method significantly improves the performance of breast cancer classification. By assembling three CNN classifiers, the proposed model achieves 0.97 AUC, which is 34.72% higher than the methods using only one imaging modality.
2D Convolutional Neural Networks for 3D Digital Breast Tomosynthesis Classification
Feb 27, 2020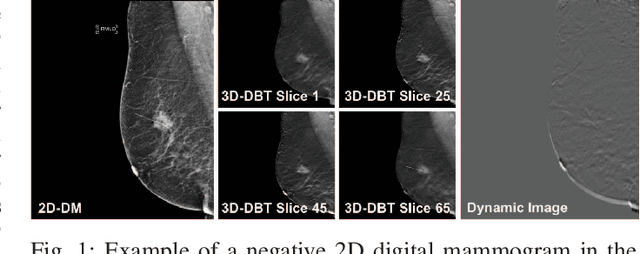
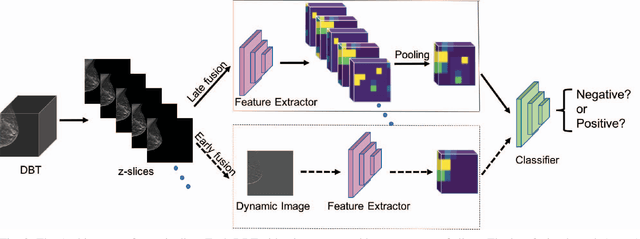
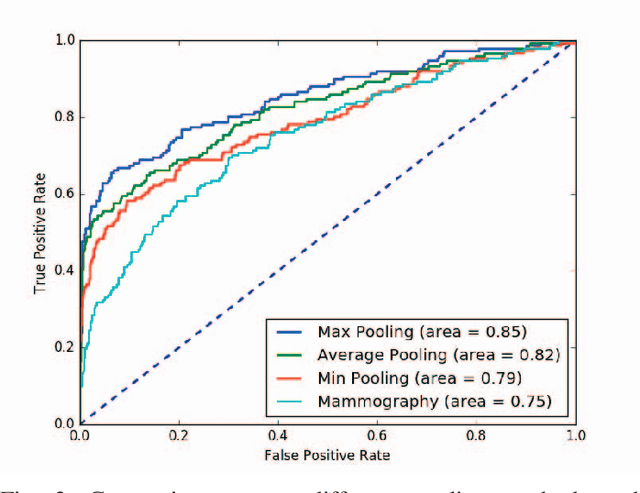
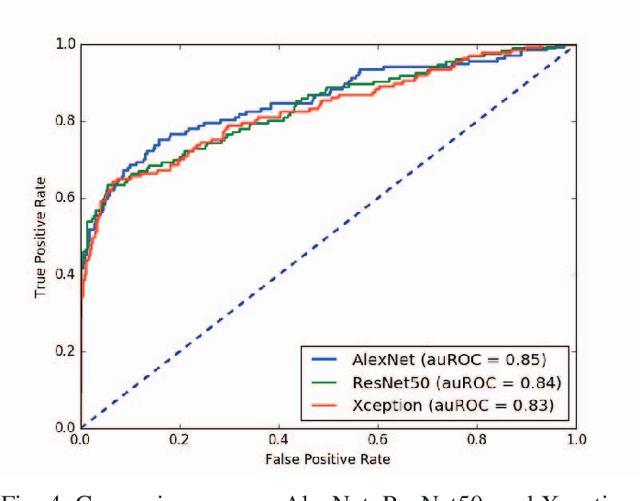
Automated methods for breast cancer detection have focused on 2D mammography and have largely ignored 3D digital breast tomosynthesis (DBT), which is frequently used in clinical practice. The two key challenges in developing automated methods for DBT classification are handling the variable number of slices and retaining slice-to-slice changes. We propose a novel deep 2D convolutional neural network (CNN) architecture for DBT classification that simultaneously overcomes both challenges. Our approach operates on the full volume, regardless of the number of slices, and allows the use of pre-trained 2D CNNs for feature extraction, which is important given the limited amount of annotated training data. In an extensive evaluation on a real-world clinical dataset, our approach achieves 0.854 auROC, which is 28.80% higher than approaches based on 3D CNNs. We also find that these improvements are stable across a range of model configurations.
Learning to Map Nearly Anything
Sep 16, 2019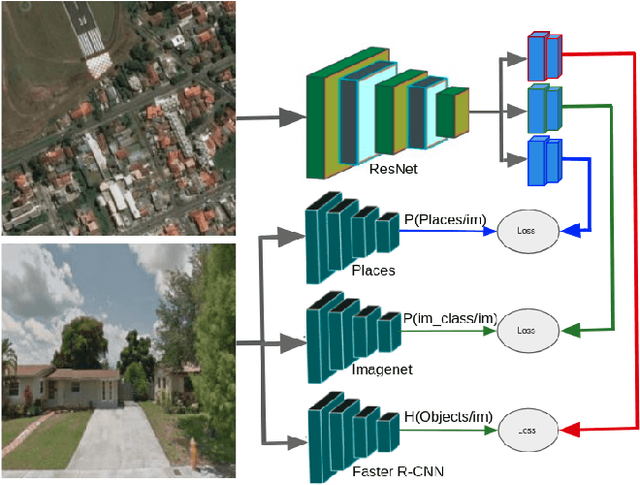


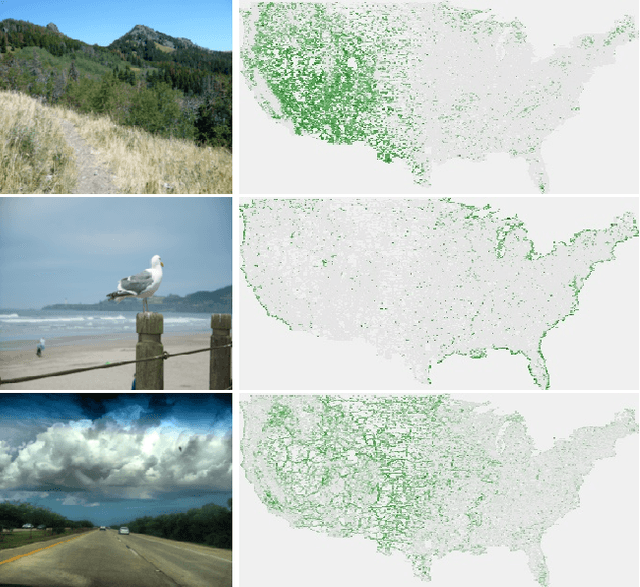
Looking at the world from above, it is possible to estimate many properties of a given location, including the type of land cover and the expected land use. Historically, such tasks have relied on relatively coarse-grained categories due to the difficulty of obtaining fine-grained annotations. In this work, we propose an easily extensible approach that makes it possible to estimate fine-grained properties from overhead imagery. In particular, we propose a cross-modal distillation strategy to learn to predict the distribution of fine-grained properties from overhead imagery, without requiring any manual annotation of overhead imagery. We show that our learned models can be used directly for applications in mapping and image localization.
Remote Estimation of Free-Flow Speeds
Jun 24, 2019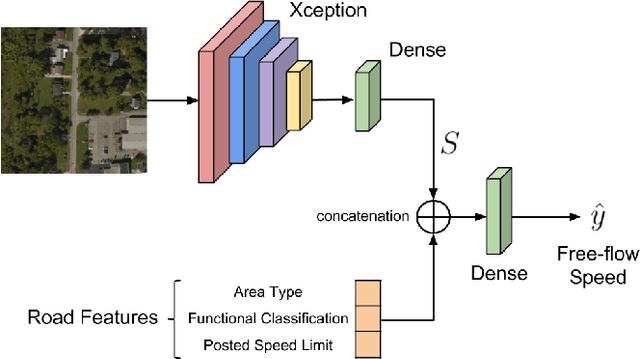



We propose an automated method to estimate a road segment's free-flow speed from overhead imagery and road metadata. The free-flow speed of a road segment is the average observed vehicle speed in ideal conditions, without congestion or adverse weather. Standard practice for estimating free-flow speeds depends on several road attributes, including grade, curve, and width of the right of way. Unfortunately, many of these fine-grained labels are not always readily available and are costly to manually annotate. To compensate, our model uses a small, easy to obtain subset of road features along with aerial imagery to directly estimate free-flow speed with a deep convolutional neural network (CNN). We evaluate our approach on a large dataset, and demonstrate that using imagery alone performs nearly as well as the road features and that the combination of imagery with road features leads to the highest accuracy.