 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-View Panorama Synthesis using Geospatially Guided Diffusion
Jul 12, 2024We introduce the task of mixed-view panorama synthesis, where the goal is to synthesize a novel panorama given a small set of input panoramas and a satellite image of the area. This contrasts with previous work which only uses input panoramas (same-view synthesis), or an input satellite image (cross-view synthesis). We argue that the mixed-view setting is the most natural to support panorama synthesis for arbitrary locations worldwide. A critical challenge is that the spatial coverage of panoramas is uneven, with few panoramas available in many regions of the world. We introduce an approach that utilizes diffusion-based modeling and an attention-based architecture for extracting information from all available input imagery. Experimental results demonstrate the effectiveness of our proposed method. In particular, our model can handle scenarios when the available panoramas are sparse or far from the location of the panorama we are attempting to synthesize.
Probabilistic Image-Driven Traffic Modeling via Remote Sensing
Mar 08, 2024



This work addresses the task of modeling spatiotemporal traffic patterns directly from overhead imagery, which we refer to as image-driven traffic modeling. We extend this line of work and introduce a multi-modal, multi-task transformer-based segmentation architecture that can be used to create dense city-scale traffic models. Our approach includes a geo-temporal positional encoding module for integrating geo-temporal context and a probabilistic objective function for estimating traffic speeds that naturally models temporal variations. We evaluate our method extensively using the Dynamic Traffic Speeds (DTS) benchmark dataset and significantly improve the state-of-the-art. Finally, we introduce the DTS++ dataset to support mobility-related location adaptation experiments.
Handling Image and Label Resolution Mismatch in Remote Sensing
Nov 28, 2022Though semantic segmentation has been heavily explored in vision literature, unique challenges remain in the remote sensing domain. One such challenge is how to handle resolution mismatch between overhead imagery and ground-truth label sources, due to differences in ground sample distance. To illustrate this problem, we introduce a new dataset and use it to showcase weaknesses inherent in existing strategies that naively upsample the target label to match the image resolution. Instead, we present a method that is supervised using low-resolution labels (without upsampling), but takes advantage of an exemplar set of high-resolution labels to guide the learning process. Our method incorporates region aggregation, adversarial learning, and self-supervised pretraining to generate fine-grained predictions, without requiring high-resolution annotations. Extensive experiments demonstrate the real-world applicability of our approach.
Revisiting Near/Remote Sensing with Geospatial Attention
Apr 04, 2022



This work addresses the task of overhead image segmentation when auxiliary ground-level images are available. Recent work has shown that performing joint inference over these two modalities, often called near/remote sensing, can yield significant accuracy improvements. Extending this line of work, we introduce the concept of geospatial attention, a geometry-aware attention mechanism that explicitly considers the geospatial relationship between the pixels in a ground-level image and a geographic location. We propose an approach for computing geospatial attention that incorporates geometric features and the appearance of the overhead and ground-level imagery. We introduce a novel architecture for near/remote sensing that is based on geospatial attention and demonstrate its use for five segmentation tasks. The results demonstrate that our method significantly outperforms the previous state-of-the-art methods.
Augmenting Depth Estimation with Geospatial Context
Sep 20, 2021



Modern cameras are equipped with a wide array of sensors that enable recording the geospatial context of an image. Taking advantage of this, we explore depth estimation under the assumption that the camera is geocalibrated, a problem we refer to as geo-enabled depth estimation. Our key insight is that if capture location is known, the corresponding overhead viewpoint offers a valuable resource for understanding the scale of the scene. We propose an end-to-end architecture for depth estimation that uses geospatial context to infer a synthetic ground-level depth map from a co-located overhead image, then fuses it inside of an encoder/decoder style segmentation network. To support evaluation of our methods, we extend a recently released dataset with overhead imagery and corresponding height maps. Results demonstrate that integrating geospatial context significantly reduces error compared to baselines, both at close ranges and when evaluating at much larger distances than existing benchmarks consider.
Content-Based Detection of Temporal Metadata Manipulation
Mar 08, 2021
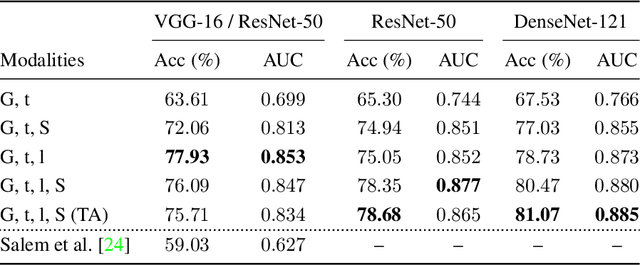
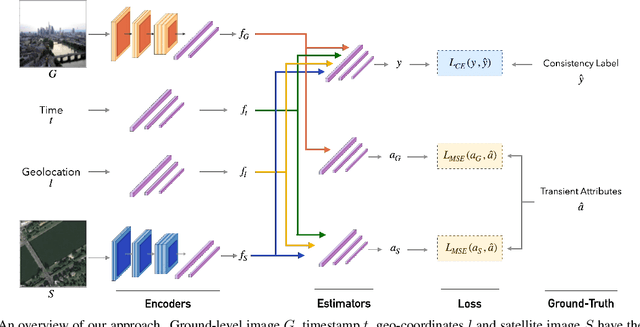
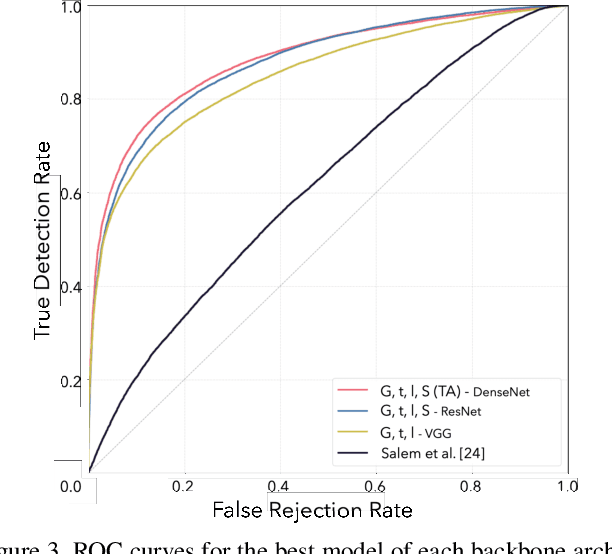
Most pictures shared online are accompanied by a temporal context (i.e., the moment they were taken) that aids their understanding and the history behind them. Claiming that these images were captured in a different moment can be misleading and help to convey a distorted version of reality. In this work, we present the nascent problem of detecting timestamp manipulation. We propose an end-to-end approach to verify whether the purported time of capture of an image is consistent with its content and geographic location. The central idea is the use of supervised consistency verification, in which we predict the probability that the image content, capture time, and geographical location are consistent. We also include a pair of auxiliary tasks, which can be used to explain the network decision. Our approach improves upon previous work on a large benchmark dataset, increasing the classification accuracy from 59.03% to 81.07%. Finally, an ablation study highlights the importance of various components of the method, showing what types of tampering are detectable using our approach.
Learning a Dynamic Map of Visual Appearance
Dec 29, 2020


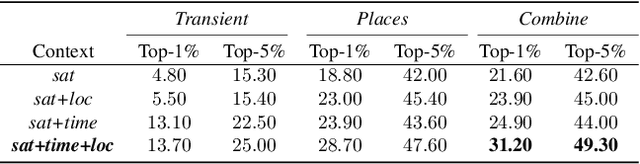
The appearance of the world varies dramatically not only from place to place but also from hour to hour and month to month. Every day billions of images capture this complex relationship, many of which are associated with precise time and location metadata. We propose to use these images to construct a global-scale, dynamic map of visual appearance attributes. Such a map enables fine-grained understanding of the expected appearance at any geographic location and time. Our approach integrates dense overhead imagery with location and time metadata into a general framework capable of mapping a wide variety of visual attributes. A key feature of our approach is that it requires no manual data annotation. We demonstrate how this approach can support various applications, including image-driven mapping, image geolocalization, and metadata verification.
A Structure-Aware Method for Direct Pose Estimation
Dec 22, 2020
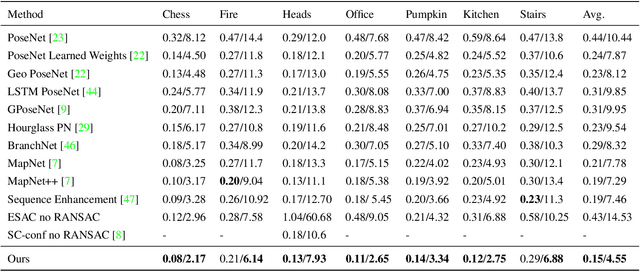

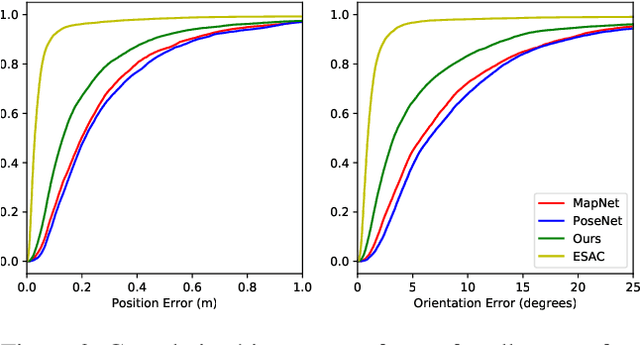
Estimating camera pose from a single image is a fundamental problem in computer vision. Existing methods for solving this task fall into two distinct categories, which we refer to as direct and indirect. Direct methods, such as PoseNet, regress pose from the image as a fixed function, for example using a feed-forward convolutional network. Such methods are desirable because they are deterministic and run in constant time. Indirect methods for pose regression are often non-deterministic, with various external dependencies such as image retrieval and hypothesis sampling. We propose a direct method that takes inspiration from structure-based approaches to incorporate explicit 3D constraints into the network. Our approach maintains the desirable qualities of other direct methods while achieving much lower error in general.
Dynamic Traffic Modeling From Overhead Imagery
Dec 18, 2020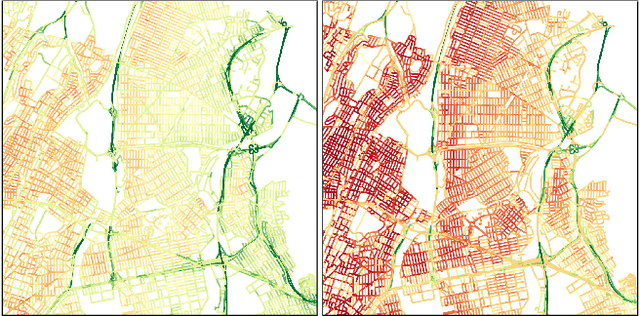



Our goal is to use overhead imagery to understand patterns in traffic flow, for instance answering questions such as how fast could you traverse Times Square at 3am on a Sunday. A traditional approach for solving this problem would be to model the speed of each road segment as a function of time. However, this strategy is limited in that a significant amount of data must first be collected before a model can be used and it fails to generalize to new areas. Instead, we propose an automatic approach for generating dynamic maps of traffic speeds using convolutional neural networks. Our method operates on overhead imagery, is conditioned on location and time, and outputs a local motion model that captures likely directions of travel and corresponding travel speeds. To train our model, we take advantage of historical traffic data collected from New York City. Experimental results demonstrate that our method can be applied to generate accurate city-scale traffic models.
Single Image Cloud Detection via Multi-Image Fusion
Jul 29, 2020



Artifacts in imagery captured by remote sensing, such as clouds, snow, and shadows, present challenges for various tasks, including semantic segmentation and object detection. A primary challenge in developing algorithms for identifying such artifacts is the cost of collecting annotated training data. In this work, we explore how recent advances in multi-image fusion can be leveraged to bootstrap single image cloud detection. We demonstrate that a network optimized to estimate image quality also implicitly learns to detect clouds. To support the training and evaluation of our approach, we collect a large dataset of Sentinel-2 images along with a per-pixel semantic labelling for land cover. Through various experiments, we demonstrate that our method reduces the need for annotated training data and improves cloud detection performance.