 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Based Detection of Temporal Metadata Manipulation
Mar 08, 2021
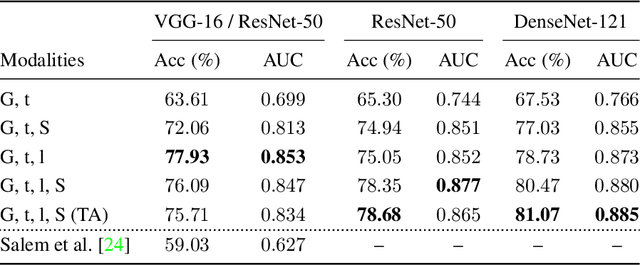
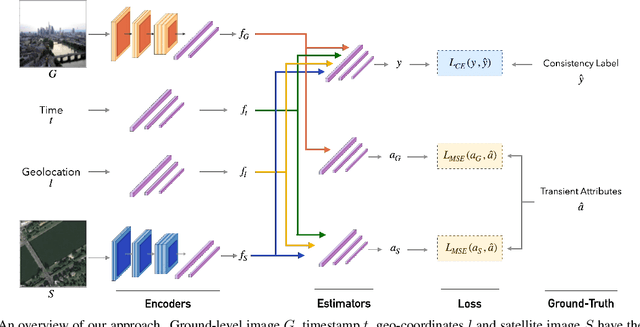
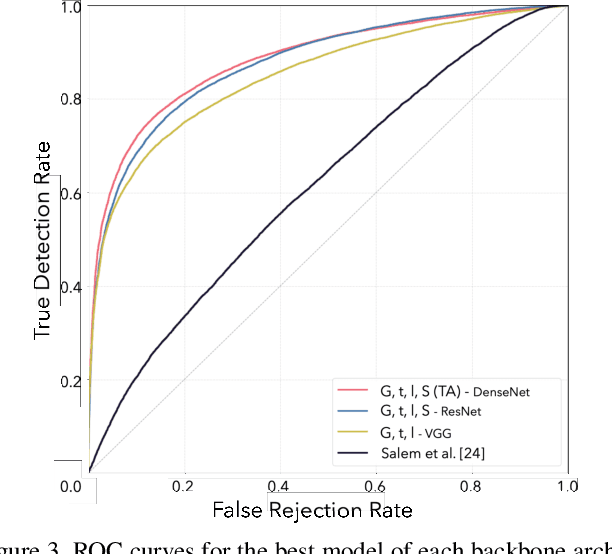
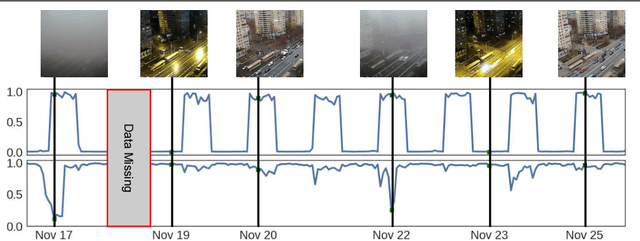
Most pictures shared online are accompanied by a temporal context (i.e., the moment they were taken) that aids their understanding and the history behind them. Claiming that these images were captured in a different moment can be misleading and help to convey a distorted version of reality. In this work, we present the nascent problem of detecting timestamp manipulation. We propose an end-to-end approach to verify whether the purported time of capture of an image is consistent with its content and geographic location. The central idea is the use of supervised consistency verification, in which we predict the probability that the image content, capture time, and geographical location are consistent. We also include a pair of auxiliary tasks, which can be used to explain the network decision. Our approach improves upon previous work on a large benchmark dataset, increasing the classification accuracy from 59.03% to 81.07%. Finally, an ablation study highlights the importance of various components of the method, showing what types of tampering are detectable using our approach.
Learning a Dynamic Map of Visual Appearance
Dec 29, 2020


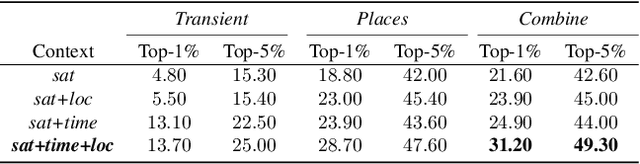
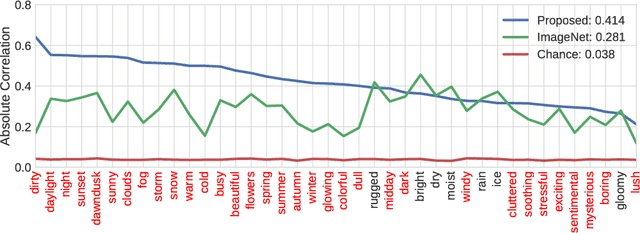
The appearance of the world varies dramatically not only from place to place but also from hour to hour and month to month. Every day billions of images capture this complex relationship, many of which are associated with precise time and location metadata. We propose to use these images to construct a global-scale, dynamic map of visual appearance attributes. Such a map enables fine-grained understanding of the expected appearance at any geographic location and time. Our approach integrates dense overhead imagery with location and time metadata into a general framework capable of mapping a wide variety of visual attributes. A key feature of our approach is that it requires no manual data annotation. We demonstrate how this approach can support various applications, including image-driven mapping, image geolocalization, and metadata verification.
Joint 2D-3D Breast Cancer Classification
Feb 27, 2020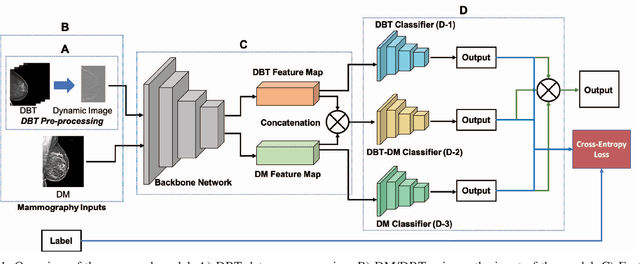
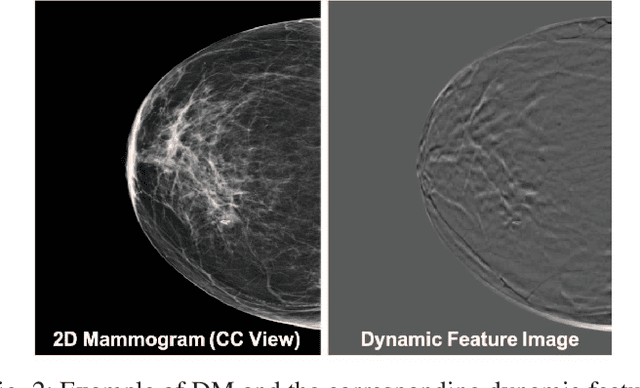
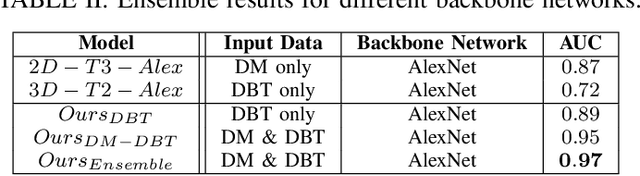

Breast cancer is the malignant tumor that causes the highest number of cancer deaths in females. Digital mammograms (DM or 2D mammogram) and digital breast tomosynthesis (DBT or 3D mammogram) are the two types of mammography imagery that are used in clinical practice for breast cancer detection and diagnosis. Radiologists usually read both imaging modalities in combination; however, existing computer-aided diagnosis tools are designed using only one imaging modality. Inspired by clinical practice, we propose an innovative convolutional neural network (CNN) architecture for breast cancer classification, which uses both 2D and 3D mammograms, simultaneously. Our experiment shows that the proposed method significantly improves the performance of breast cancer classification. By assembling three CNN classifiers, the proposed model achieves 0.97 AUC, which is 34.72% higher than the methods using only one imaging modality.
Defense-PointNet: Protecting PointNet Against Adversarial Attacks
Feb 27, 2020


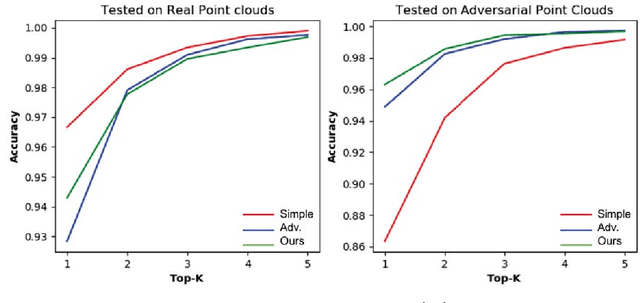
Despite remarkable performance across a broad range of tasks, neural networks have been shown to be vulnerable to adversarial attacks. Many works focus on adversarial attacks and defenses on 2D images, but few focus on 3D point clouds. In this paper, our goal is to enhance the adversarial robustness of PointNet, which is one of the most widely used models for 3D point clouds. We apply the fast gradient sign attack method (FGSM) on 3D point clouds and find that FGSM can be used to generate not only adversarial images but also adversarial point clouds. To minimize the vulnerability of PointNet to adversarial attacks, we propose Defense-PointNet. We compare our model with two baseline approaches and show that Defense-PointNet significantly improves the robustness of the network against adversarial samples.
Learning Geo-Temporal Image Features
Sep 16, 2019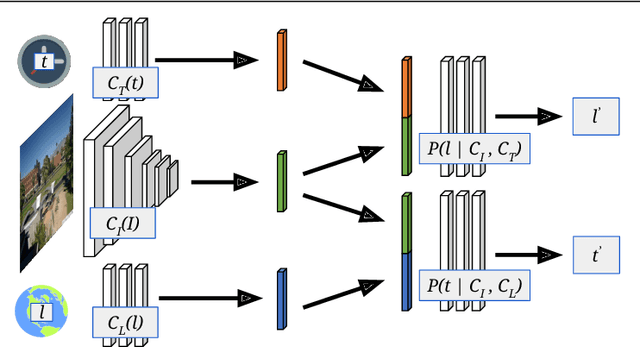

We propose to implicitly learn to extract geo-temporal image features, which are mid-level features related to when and where an image was captured, by explicitly optimizing for a set of location and time estimation tasks. To train our method, we take advantage of a large image dataset, captured by outdoor webcams and cell phones. The only form of supervision we provide are the known capture time and location of each image. We find that our approach learns features that are related to natural appearance changes in outdoor scenes. Additionally, we demonstrate the application of these geo-temporal features to time and location estimation.
Learning to Map Nearly Anything
Sep 16, 2019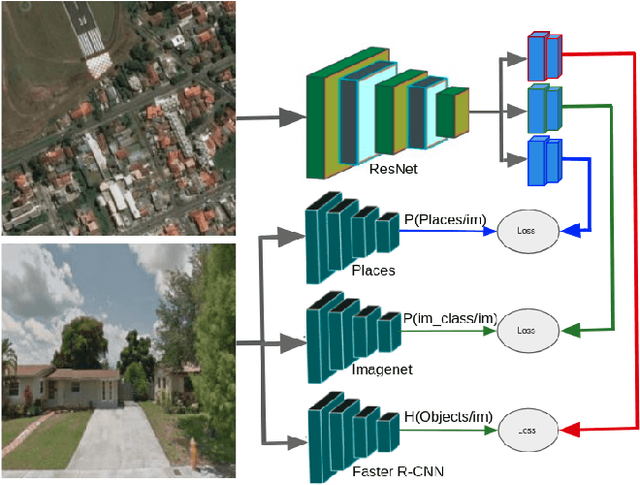


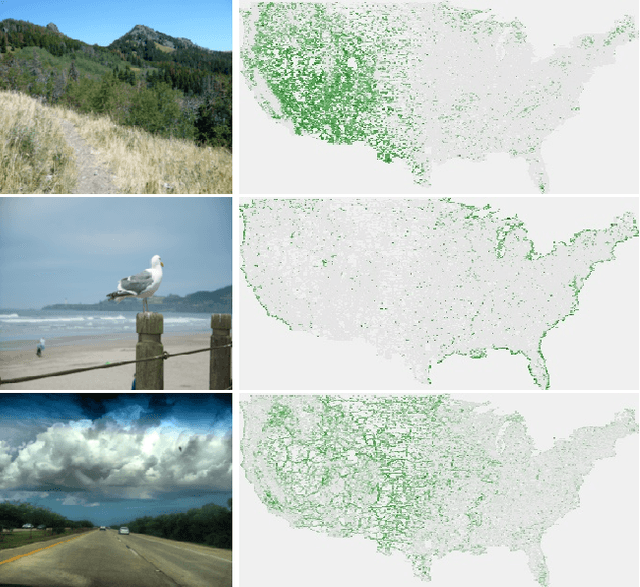
Looking at the world from above, it is possible to estimate many properties of a given location, including the type of land cover and the expected land use. Historically, such tasks have relied on relatively coarse-grained categories due to the difficulty of obtaining fine-grained annotations. In this work, we propose an easily extensible approach that makes it possible to estimate fine-grained properties from overhead imagery. In particular, we propose a cross-modal distillation strategy to learn to predict the distribution of fine-grained properties from overhead imagery, without requiring any manual annotation of overhead imagery. We show that our learned models can be used directly for applications in mapping and image localization.
Remote Estimation of Free-Flow Speeds
Jun 24, 2019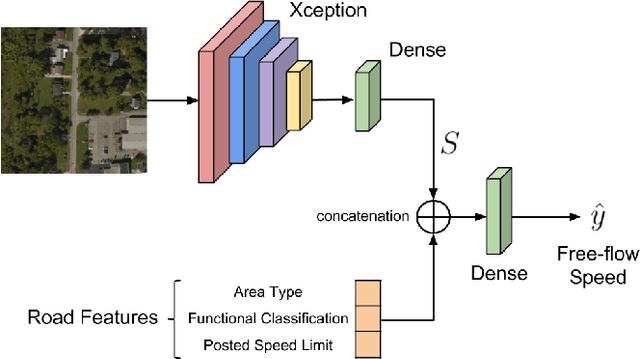



We propose an automated method to estimate a road segment's free-flow speed from overhead imagery and road metadata. The free-flow speed of a road segment is the average observed vehicle speed in ideal conditions, without congestion or adverse weather. Standard practice for estimating free-flow speeds depends on several road attributes, including grade, curve, and width of the right of way. Unfortunately, many of these fine-grained labels are not always readily available and are costly to manually annotate. To compensate, our model uses a small, easy to obtain subset of road features along with aerial imagery to directly estimate free-flow speed with a deep convolutional neural network (CNN). We evaluate our approach on a large dataset, and demonstrate that using imagery alone performs nearly as well as the road features and that the combination of imagery with road features leads to the highest accuracy.