 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Geo-Temporal Image Features
Sep 16, 2019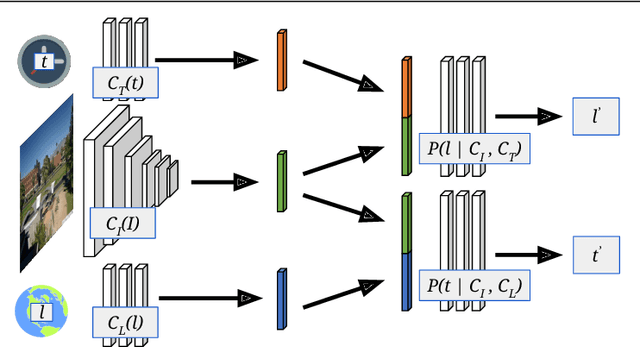

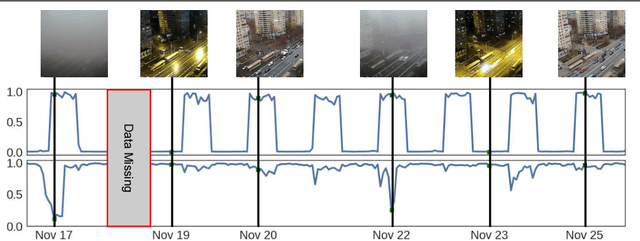
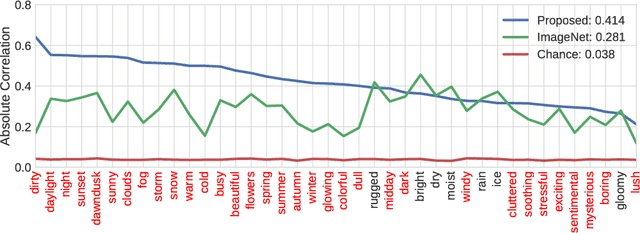
We propose to implicitly learn to extract geo-temporal image features, which are mid-level features related to when and where an image was captured, by explicitly optimizing for a set of location and time estimation tasks. To train our method, we take advantage of a large image dataset, captured by outdoor webcams and cell phones. The only form of supervision we provide are the known capture time and location of each image. We find that our approach learns features that are related to natural appearance changes in outdoor scenes. Additionally, we demonstrate the application of these geo-temporal features to time and location estimation.
Learning to Look around Objects for Top-View Representations of Outdoor Scenes
Mar 28, 2018



Given a single RGB image of a complex outdoor road scene in the perspective view, we address the novel problem of estimating an occlusion-reasoned semantic scene layout in the top-view. This challenging problem not only requires an accurate understanding of both the 3D geometry and the semantics of the visible scene, but also of occluded areas. We propose a convolutional neural network that learns to predict occluded portions of the scene layout by looking around foreground objects like cars or pedestrians. But instead of hallucinating RGB values, we show that directly predicting the semantics and depths in the occluded areas enables a better transformation into the top-view. We further show that this initial top-view representation can be significantly enhanced by learning priors and rules about typical road layouts from simulated or, if available, map data. Crucially, training our model does not require costly or subjective human annotations for occluded areas or the top-view, but rather uses readily available annotations for standard semantic segmentation. We extensively evaluate and analyze our approach on the KITTI and Cityscapes data sets.
A Unified Model for Near and Remote Sensing
Aug 09, 2017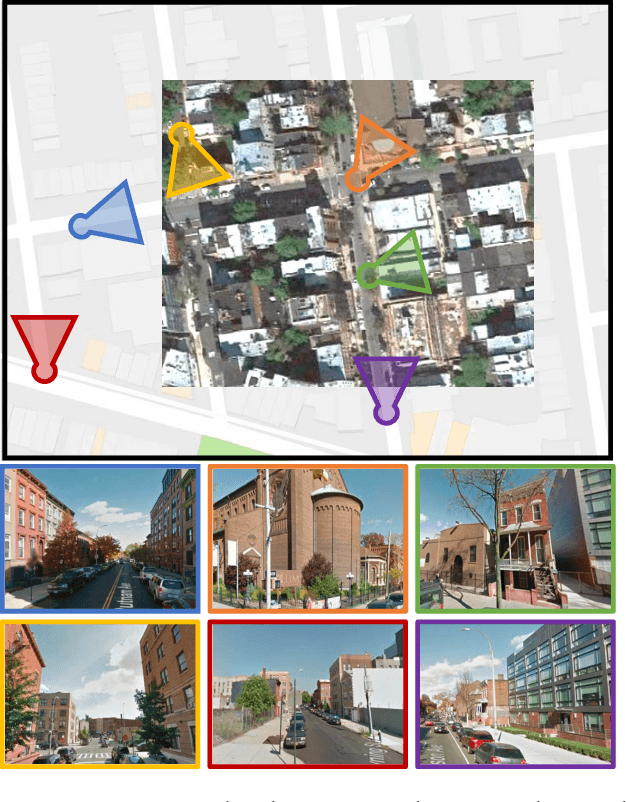
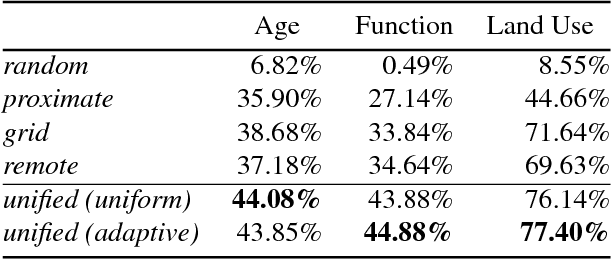

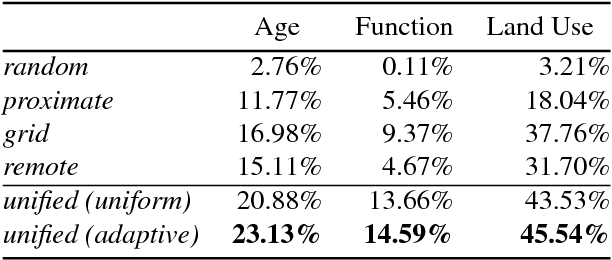
We propose a novel convolutional neural network architecture for estimating geospatial functions such as population density, land cover, or land use. In our approach, we combine overhead and ground-level images in an end-to-end trainable neural network, which uses kernel regression and density estimation to convert features extracted from the ground-level images into a dense feature map. The output of this network is a dense estimate of the geospatial function in the form of a pixel-level labeling of the overhead image. To evaluate our approach, we created a large dataset of overhead and ground-level images from a major urban area with three sets of labels: land use, building function, and building age. We find that our approach is more accurate for all tasks, in some cases dramatically so.
Predicting Ground-Level Scene Layout from Aerial Imagery
Dec 08, 2016

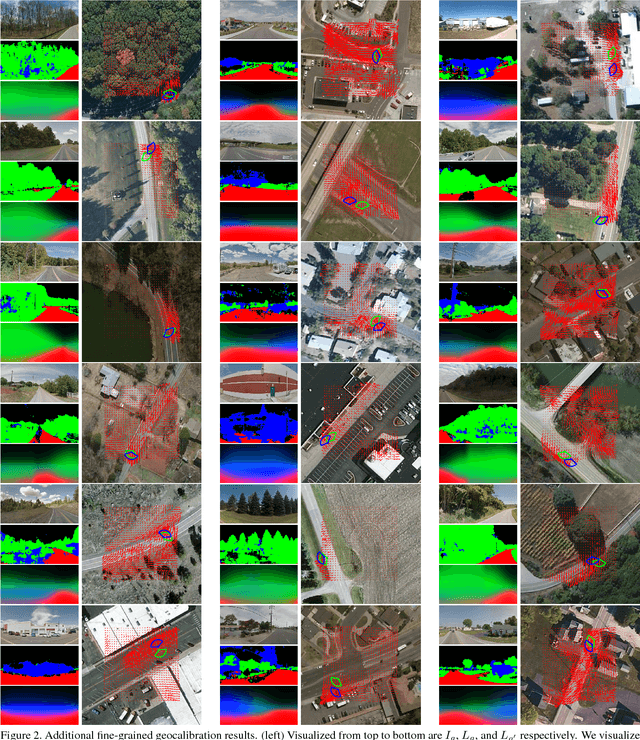

We introduce a novel strategy for learning to extract semantically meaningful features from aerial imagery. Instead of manually labeling the aerial imagery, we propose to predict (noisy) semantic features automatically extracted from co-located ground imagery. Our network architecture takes an aerial image as input, extracts features using a convolutional neural network, and then applies an adaptive transformation to map these features into the ground-level perspective. We use an end-to-end learning approach to minimize the difference between the semantic segmentation extracted directly from the ground image and the semantic segmentation predicted solely based on the aerial image. We show that a model learned using this strategy, with no additional training, is already capable of rough semantic labeling of aerial imagery. Furthermore, we demonstrate that by finetuning this model we can achieve more accurate semantic segmentation than two baseline initialization strategies. We use our network to address the task of estimating the geolocation and geoorientation of a ground image. Finally, we show how features extracted from an aerial image can be used to hallucinate a plausible ground-level panorama.
Detecting Vanishing Points using Global Image Context in a Non-Manhattan World
Aug 19, 2016

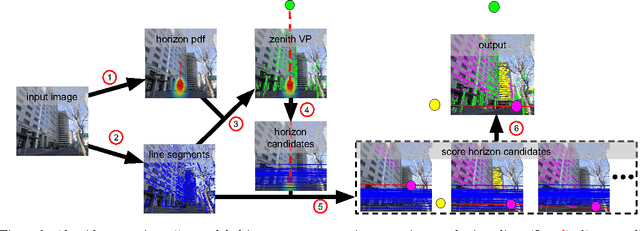
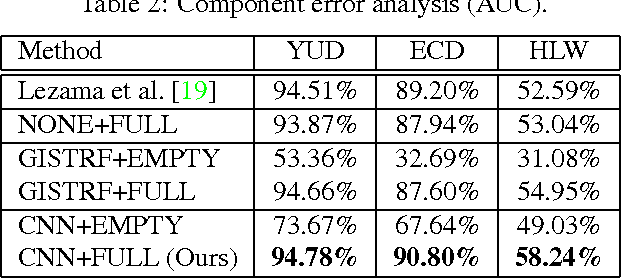
We propose a novel method for detecting horizontal vanishing points and the zenith vanishing point in man-made environments. The dominant trend in existing methods is to first find candidate vanishing points, then remove outliers by enforcing mutual orthogonality. Our method reverses this process: we propose a set of horizon line candidates and score each based on the vanishing points it contains. A key element of our approach is the use of global image context, extracted with a deep convolutional network, to constrain the set of candidates under consideration. Our method does not make a Manhattan-world assumption and can operate effectively on scenes with only a single horizontal vanishing point. We evaluate our approach on three benchmark datasets and achieve state-of-the-art performance on each. In addition, our approach is significantly faster than the previous best method.
Horizon Lines in the Wild
Aug 16, 2016
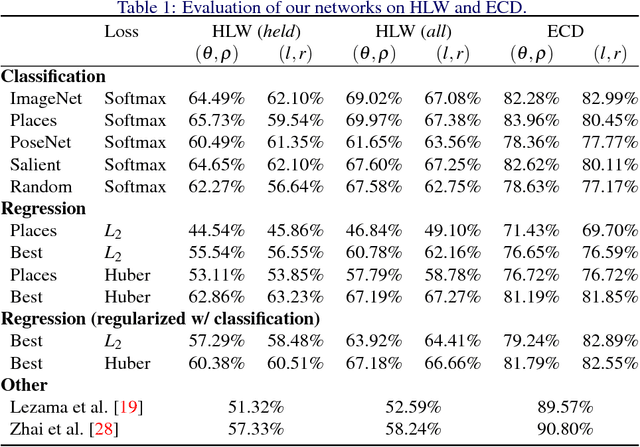
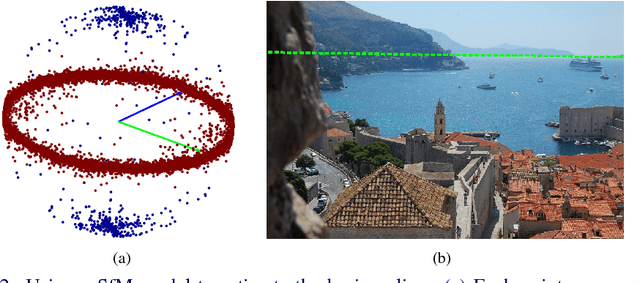
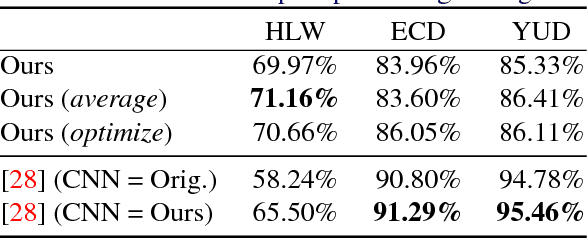
The horizon line is an important contextual attribute for a wide variety of image understanding tasks. As such, many methods have been proposed to estimate its location from a single image. These methods typically require the image to contain specific cues, such as vanishing points, coplanar circles, and regular textures, thus limiting their real-world applicability. We introduce a large, realistic evaluation dataset, Horizon Lines in the Wild (HLW), containing natural images with labeled horizon lines. Using this dataset, we investigate the application of convolutional neural networks for directly estimating the horizon line, without requiring any explicit geometric constraints or other special cues. An extensive evaluation shows that using our CNNs, either in isolation or in conjunction with a previous geometric approach, we achieve state-of-the-art results on the challenging HLW dataset and two existing benchmark datasets.