 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedProbCLIP: Probabilistic Adaptation of Vision-Language Foundation Model for Reliable Radiograph-Report Retrieval
Feb 17, 2026Vision-language foundation models have emerged as powerful general-purpose representation learners with strong potential for multimodal understanding, but their deterministic embeddings often fail to provide the reliability required for high-stakes biomedical applications. This work introduces MedProbCLIP, a probabilistic vision-language learning framework for chest X-ray and radiology report representation learning and bidirectional retrieval. MedProbCLIP models image and text representations as Gaussian embeddings through a probabilistic contrastive objective that explicitly captures uncertainty and many-to-many correspondences between radiographs and clinical narratives. A variational information bottleneck mitigates overconfident predictions, while MedProbCLIP employs multi-view radiograph encoding and multi-section report encoding during training to provide fine-grained supervision for clinically aligned correspondence, yet requires only a single radiograph and a single report at inference. Evaluated on the MIMIC-CXR dataset, MedProbCLIP outperforms deterministic and probabilistic baselines, including CLIP, CXR-CLIP, and PCME++, in both retrieval and zero-shot classification. Beyond accuracy, MedProbCLIP demonstrates superior calibration, risk-coverage behavior, selective retrieval reliability, and robustness to clinically relevant corruptions, underscoring the value of probabilistic vision-language modeling for improving the trustworthiness and safety of radiology image-text retrieval systems.
Beta Distribution Learning for Reliable Roadway Crash Risk Assessment
Nov 07, 2025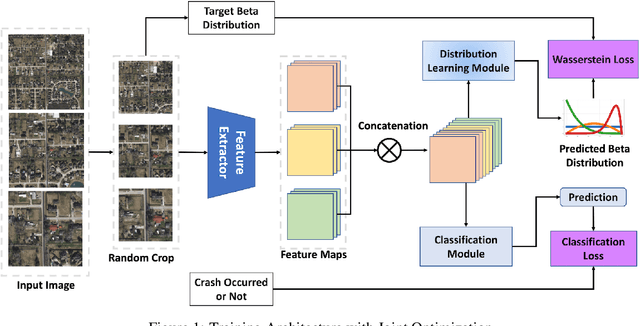

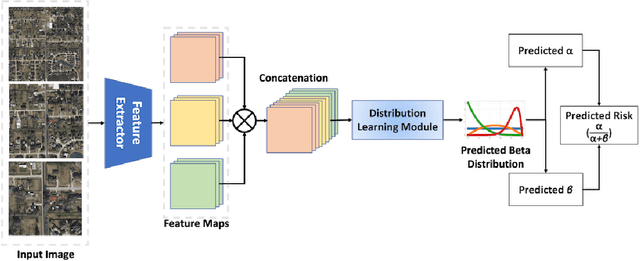

Roadway traffic accidents represent a global health crisis, responsible for over a million deaths annually and costing many countries up to 3% of their GDP. Traditional traffic safety studies often examine risk factors in isolation, overlooking the spatial complexity and contextual interactions inherent in the built environment. Furthermore, conventional Neural Network-based risk estimators typically generate point estimates without conveying model uncertainty, limiting their utility in critical decision-making. To address these shortcomings, we introduce a novel geospatial deep learning framework that leverages satellite imagery as a comprehensive spatial input. This approach enables the model to capture the nuanced spatial patterns and embedded environmental risk factors that contribute to fatal crash risks. Rather than producing a single deterministic output, our model estimates a full Beta probability distribution over fatal crash risk, yielding accurate and uncertainty-aware predictions--a critical feature for trustworthy AI in safety-critical applications. Our model outperforms baselines by achieving a 17-23% improvement in recall, a key metric for flagging potential dangers, while delivering superior calibration. By providing reliable and interpretable risk assessments from satellite imagery alone, our method enables safer autonomous navigation and offers a highly scalable tool for urban planners and policymakers to enhance roadway safety equitably and cost-effectively.
Benchmarking Robustness of Contrastive Learning Models for Medical Image-Report Retrieval
Jan 15, 2025



Medical images and reports offer invaluable insights into patient health. The heterogeneity and complexity of these data hinder effective analysis. To bridge this gap, we investigate contrastive learning models for cross-domain retrieval, which associates medical images with their corresponding clinical reports. This study benchmarks the robustness of four state-of-the-art contrastive learning models: CLIP, CXR-RePaiR, MedCLIP, and CXR-CLIP. We introduce an occlusion retrieval task to evaluate model performance under varying levels of image corruption. Our findings reveal that all evaluated models are highly sensitive to out-of-distribution data, as evidenced by the proportional decrease in performance with increasing occlusion levels. While MedCLIP exhibits slightly more robustness, its overall performance remains significantly behind CXR-CLIP and CXR-RePaiR. CLIP, trained on a general-purpose dataset, struggles with medical image-report retrieval, highlighting the importance of domain-specific training data. The evaluation of this work suggests that more effort needs to be spent on improving the robustness of these models. By addressing these limitations, we can develop more reliable cross-domain retrieval models for medical applications.
Mutation-Based Adversarial Attacks on Neural Text Detectors
Feb 11, 2023


Neural text detectors aim to decide the characteristics that distinguish neural (machine-generated) from human texts. To challenge such detectors, adversarial attacks can alter the statistical characteristics of the generated text, making the detection task more and more difficult. Inspired by the advances of mutation analysis in software development and testing, in this paper, we propose character- and word-based mutation operators for generating adversarial samples to attack state-of-the-art natural text detectors. This falls under white-box adversarial attacks. In such attacks, attackers have access to the original text and create mutation instances based on this original text. The ultimate goal is to confuse machine learning models and classifiers and decrease their prediction accuracy.
A Mutation-based Text Generation for Adversarial Machine Learning Applications
Dec 21, 2022Many natural language related applications involve text generation, created by humans or machines. While in many of those applications machines support humans, yet in few others, (e.g. adversarial machine learning, social bots and trolls) machines try to impersonate humans. In this scope, we proposed and evaluated several mutation-based text generation approaches. Unlike machine-based generated text, mutation-based generated text needs human text samples as inputs. We showed examples of mutation operators but this work can be extended in many aspects such as proposing new text-based mutation operators based on the nature of the application.
Benchmark Assessment for DeepSpeed Optimization Library
Feb 12, 2022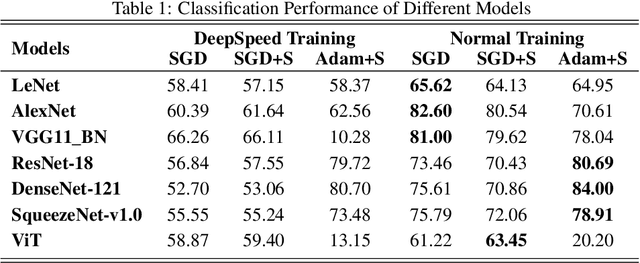
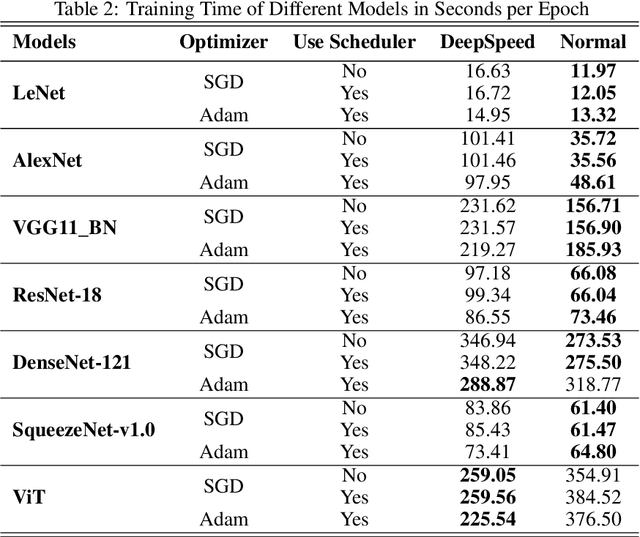
Deep Learning (DL) models are widely used in machine learning due to their performance and ability to deal with large datasets while producing high accuracy and performance metrics. The size of such datasets and the complexity of DL models cause such models to be complex, consuming large amount of resources and time to train. Many recent libraries and applications are introduced to deal with DL complexity and efficiency issues. In this paper, we evaluated one example, Microsoft DeepSpeed library through classification tasks. DeepSpeed public sources reported classification performance metrics on the LeNet architecture. We extended this through evaluating the library on several modern neural network architectures, including convolutional neural networks (CNNs) and Vision Transformer (ViT). Results indicated that DeepSpeed, while can make improvements in some of those cases, it has no or negative impact on others.
Dynamic Feature Alignment for Semi-supervised Domain Adaptation
Oct 18, 2021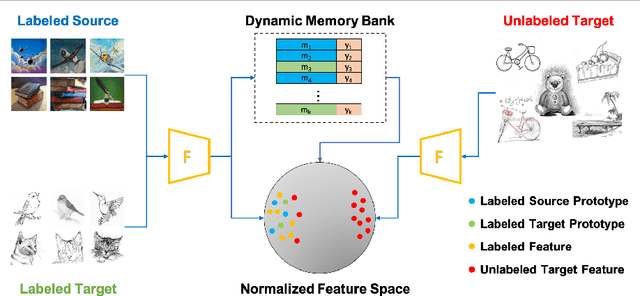
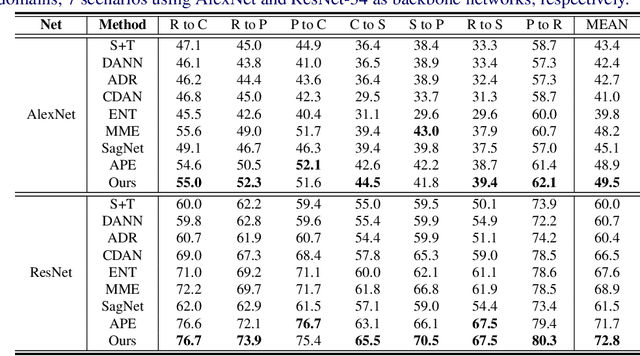
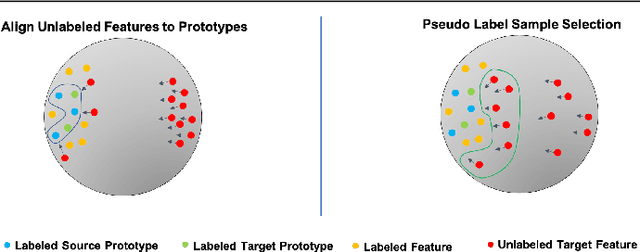
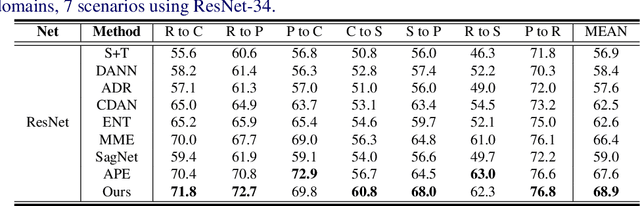
Most research on domain adaptation has focused on the purely unsupervised setting, where no labeled examples in the target domain are available. However, in many real-world scenarios, a small amount of labeled target data is available and can be used to improve adaptation. We address this semi-supervised setting and propose to use dynamic feature alignment to address both inter- and intra-domain discrepancy. Unlike previous approaches, which attempt to align source and target features within a mini-batch, we propose to align the target features to a set of dynamically updated class prototypes, which we use both for minimizing divergence and pseudo-labeling. By updating based on class prototypes, we avoid problems that arise in previous approaches due to class imbalances. Our approach, which doesn't require extensive tuning or adversarial training, significantly improves the state of the art for semi-supervised domain adaptation. We provide a quantitative evaluation on two standard datasets, DomainNet and Office-Home, and performance analysis.
Optical Wavelength Guided Self-Supervised Feature Learning For Galaxy Cluster Richness Estimate
Dec 04, 2020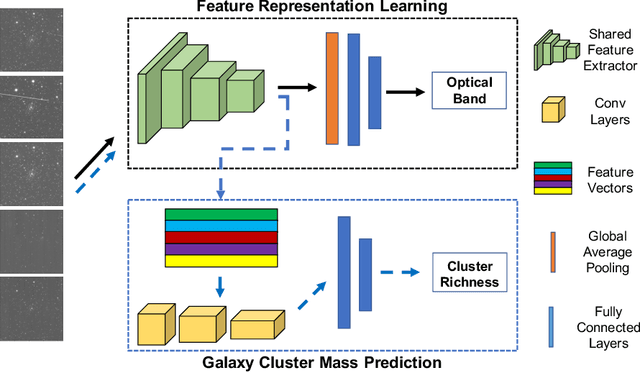
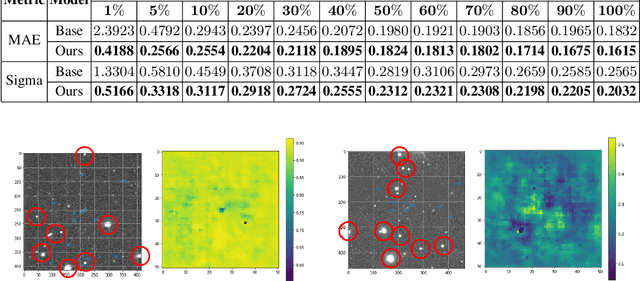
Most galaxies in the nearby Universe are gravitationally bound to a cluster or group of galaxies. Their optical contents, such as optical richness, are crucial for understanding the co-evolution of galaxies and large-scale structures in modern astronomy and cosmology. The determination of optical richness can be challenging. We propose a self-supervised approach for estimating optical richness from multi-band optical images. The method uses the data properties of the multi-band optical images for pre-training, which enables learning feature representations from a large but unlabeled dataset. We apply the proposed method to the Sloan Digital Sky Survey. The result shows our estimate of optical richness lowers the mean absolute error and intrinsic scatter by 11.84% and 20.78%, respectively, while reducing the need for labeled training data by up to 60%. We believe the proposed method will benefit astronomy and cosmology, where a large number of unlabeled multi-band images are available, but acquiring image labels is costly.
Dynamic Image for 3D MRI Image Alzheimer's Disease Classification
Nov 30, 2020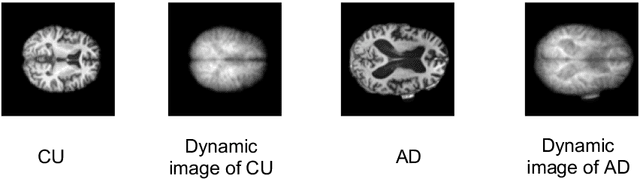
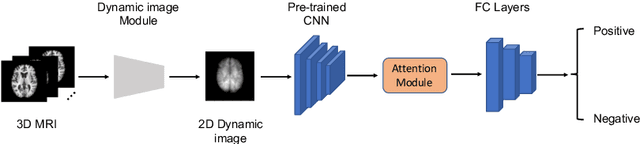
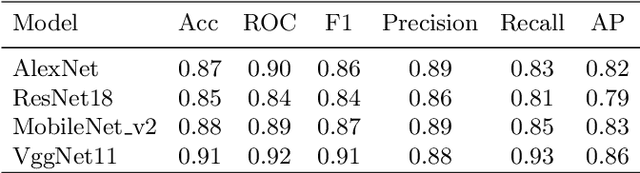
We propose to apply a 2D CNN architecture to 3D MRI image Alzheimer's disease classification. Training a 3D convolutional neural network (CNN) is time-consuming and computationally expensive. We make use of approximate rank pooling to transform the 3D MRI image volume into a 2D image to use as input to a 2D CNN. We show our proposed CNN model achieves $9.5\%$ better Alzheimer's disease classification accuracy than the baseline 3D models. We also show that our method allows for efficient training, requiring only 20% of the training time compared to 3D CNN models. The code is available online: https://github.com/UkyVision/alzheimer-project.
Weakly-Supervised Feature Learning via Text and Image Matching
Oct 06, 2020

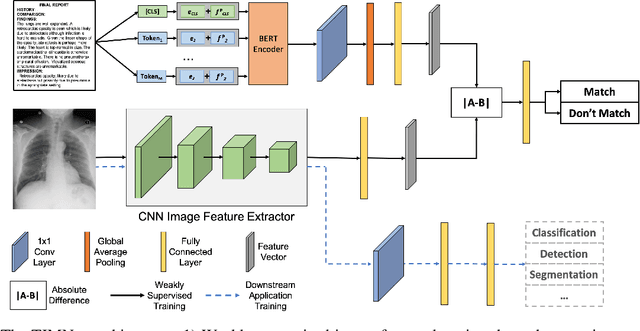
When training deep neural networks for medical image classification, obtaining a sufficient number of manually annotated images is often a significant challenge. We propose to use textual findings, which are routinely written by clinicians during manual image analysis, to help overcome this problem. The key idea is to use a contrastive loss to train image and text feature extractors to recognize if a given image-finding pair is a true match. The learned image feature extractor is then fine-tuned, in a transfer learning setting, for a supervised classification task. This approach makes it possible to train using large datasets because pairs of images and textual findings are widely available in medical records. We evaluate our method on three datasets and find consistent performance improvements. The biggest gains are realized when fewer manually labeled examples are available. In some cases, our method achieves the same performance as the baseline even when using 70\%--98\% fewer labeled examples.