 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Feature Learning via Text and Image Matching
Paper and Code


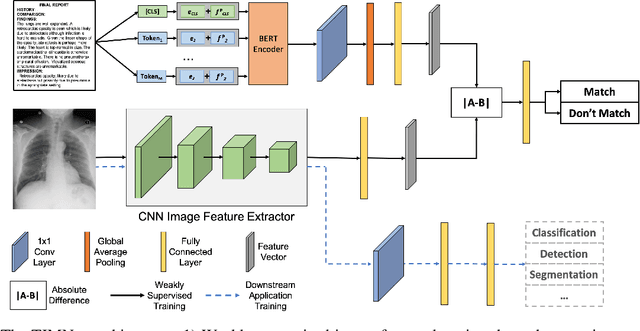
When training deep neural networks for medical image classification, obtaining a sufficient number of manually annotated images is often a significant challenge. We propose to use textual findings, which are routinely written by clinicians during manual image analysis, to help overcome this problem. The key idea is to use a contrastive loss to train image and text feature extractors to recognize if a given image-finding pair is a true match. The learned image feature extractor is then fine-tuned, in a transfer learning setting, for a supervised classification task. This approach makes it possible to train using large datasets because pairs of images and textual findings are widely available in medical records. We evaluate our method on three datasets and find consistent performance improvements. The biggest gains are realized when fewer manually labeled examples are available. In some cases, our method achieves the same performance as the baseline even when using 70\%--98\% fewer labeled examples.