 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLAMA Model Security Against OWASP Top 10 For LLM Applications
Jan 27, 2026As large language models (LLMs) move from research prototypes to enterprise systems, their security vulnerabilities pose serious risks to data privacy and system integrity. This study benchmarks various Llama model variants against the OWASP Top 10 for LLM Applications framework, evaluating threat detection accuracy, response safety, and computational overhead. Using the FABRIC testbed with NVIDIA A30 GPUs, we tested five standard Llama models and five Llama Guard variants on 100 adversarial prompts covering ten vulnerability categories. Our results reveal significant differences in security performance: the compact Llama-Guard-3-1B model achieved the highest detection rate of 76% with minimal latency (0.165s per test), whereas base models such as Llama-3.1-8B failed to detect threats (0% accuracy) despite longer inference times (0.754s). We observe an inverse relationship between model size and security effectiveness, suggesting that smaller, specialized models often outperform larger general-purpose ones in security tasks. Additionally, we provide an open-source benchmark dataset including adversarial prompts, threat labels, and attack metadata to support reproducible research in AI security, [1].
Security Hardening Using FABRIC: Implementing a Unified Compliance Aggregator for Linux Servers
Jan 01, 2026This paper presents a unified framework for evaluating Linux security hardening on the FABRIC testbed through aggregation of heterogeneous security auditing tools. We deploy three Ubuntu 22.04 nodes configured at baseline, partial, and full hardening levels, and evaluate them using Lynis, OpenSCAP, and AIDE across 108 audit runs. To address the lack of a consistent interpretation across tools, we implement a Unified Compliance Aggregator (UCA) that parses tool outputs, normalizes scores to a common 0--100 scale, and combines them into a weighted metric augmented by a customizable rule engine for organization-specific security policies. Experimental results show that full hardening increases OpenSCAP compliance from 39.7 to 71.8, while custom rule compliance improves from 39.3\% to 83.6\%. The results demonstrate that UCA provides a clearer and more reproducible assessment of security posture than individual tools alone, enabling systematic evaluation of hardening effectiveness in programmable testbed environments.
An empirical analysis of zero-day vulnerabilities disclosed by the zero day initiative
Dec 16, 2025Zero-day vulnerabilities represent some of the most critical threats in cybersecurity, as they correspond to previously unknown flaws in software or hardware that are actively exploited before vendors can develop and deploy patches. During this exposure window, affected systems remain defenseless, making zero-day attacks particularly damaging and difficult to mitigate. This study analyzes the Zero Day Initiative (ZDI) vulnerability disclosures reported between January and April 2024, Cole [2025] comprising a total of 415 vulnerabilities. The dataset includes vulnerability identifiers, Common Vulnerability Scoring System (CVSS) v3.0 scores, publication dates, and short textual descriptions. The primary objectives of this work are to identify trends in zero-day vulnerability disclosures, examine severity distributions across vendors, and investigate which vulnerability characteristics are most indicative of high severity. In addition, this study explores predictive modeling approaches for severity classification, comparing classical machine learning techniques with deep learning models using both structured metadata and unstructured textual descriptions. The findings aim to support improved patch prioritization strategies, more effective vulnerability management, and enhanced organizational preparedness against emerging zero-day threats.
Intrusion Detection in Internet of Vehicles Using Machine Learning
Dec 16, 2025


The Internet of Vehicles (IoV) has evolved modern transportation through enhanced connectivity and intelligent systems. However, this increased connectivity introduces critical vulnerabilities, making vehicles susceptible to cyber-attacks such Denial-ofService (DoS) and message spoofing. This project aims to develop a machine learning-based intrusion detection system to classify malicious Controller Area network (CAN) bus traffic using the CiCIoV2024 benchmark dataset. We analyzed various attack patterns including DoS and spoofing attacks targeting critical vehicle parameters such as Spoofing-GAS - gas pedal position, Spoofing-RPM, Spoofing-Speed, and Spoofing-Steering\_Wheel. Our initial findings confirm a multi-class classification problem with a clear structural difference between attack types and benign data, providing a strong foundation for machine learning models.
Transforming Computer Security and Public Trust Through the Exploration of Fine-Tuning Large Language Models
Jun 02, 2024Large language models (LLMs) have revolutionized how we interact with machines. However, this technological advancement has been paralleled by the emergence of "Mallas," malicious services operating underground that exploit LLMs for nefarious purposes. Such services create malware, phishing attacks, and deceptive websites, escalating the cyber security threats landscape. This paper delves into the proliferation of Mallas by examining the use of various pre-trained language models and their efficiency and vulnerabilities when misused. Building on a dataset from the Common Vulnerabilities and Exposures (CVE) program, it explores fine-tuning methodologies to generate code and explanatory text related to identified vulnerabilities. This research aims to shed light on the operational strategies and exploitation techniques of Mallas, leading to the development of more secure and trustworthy AI applications. The paper concludes by emphasizing the need for further research, enhanced safeguards, and ethical guidelines to mitigate the risks associated with the malicious application of LLMs.
Predicting Question Quality on StackOverflow with Neural Networks
Apr 20, 2024



The wealth of information available through the Internet and social media is unprecedented. Within computing fields, websites such as Stack Overflow are considered important sources for users seeking solutions to their computing and programming issues. However, like other social media platforms, Stack Overflow contains a mixture of relevant and irrelevant information. In this paper, we evaluated neural network models to predict the quality of questions on Stack Overflow, as an example of Question Answering (QA) communities. Our results demonstrate the effectiveness of neural network models compared to baseline machine learning models, achieving an accuracy of 80%. Furthermore, our findings indicate that the number of layers in the neural network model can significantly impact its performance.
Mutation-Based Adversarial Attacks on Neural Text Detectors
Feb 11, 2023


Neural text detectors aim to decide the characteristics that distinguish neural (machine-generated) from human texts. To challenge such detectors, adversarial attacks can alter the statistical characteristics of the generated text, making the detection task more and more difficult. Inspired by the advances of mutation analysis in software development and testing, in this paper, we propose character- and word-based mutation operators for generating adversarial samples to attack state-of-the-art natural text detectors. This falls under white-box adversarial attacks. In such attacks, attackers have access to the original text and create mutation instances based on this original text. The ultimate goal is to confuse machine learning models and classifiers and decrease their prediction accuracy.
A Mutation-based Text Generation for Adversarial Machine Learning Applications
Dec 21, 2022Many natural language related applications involve text generation, created by humans or machines. While in many of those applications machines support humans, yet in few others, (e.g. adversarial machine learning, social bots and trolls) machines try to impersonate humans. In this scope, we proposed and evaluated several mutation-based text generation approaches. Unlike machine-based generated text, mutation-based generated text needs human text samples as inputs. We showed examples of mutation operators but this work can be extended in many aspects such as proposing new text-based mutation operators based on the nature of the application.
Synthetic Text Detection: Systemic Literature Review
Oct 01, 2022
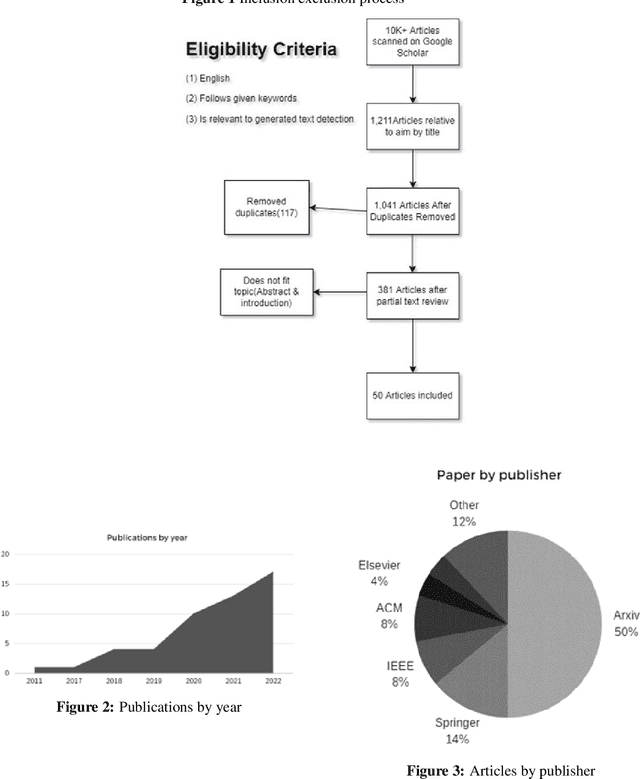

Within the text analysis and processing fields, generated text attacks have been made easier to create than ever before. To combat these attacks open sourcing models and datasets have become a major trend to create automated detection algorithms in defense of authenticity. For this purpose, synthetic text detection has become an increasingly viable topic of research. This review is written for the purpose of creating a snapshot of the state of current literature and easing the barrier to entry for future authors. Towards that goal, we identified few research trends and challenges in this field.
Benchmark Assessment for DeepSpeed Optimization Library
Feb 12, 2022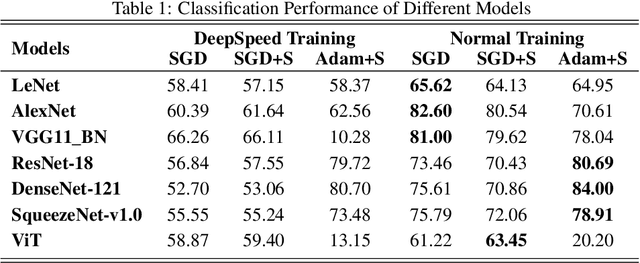
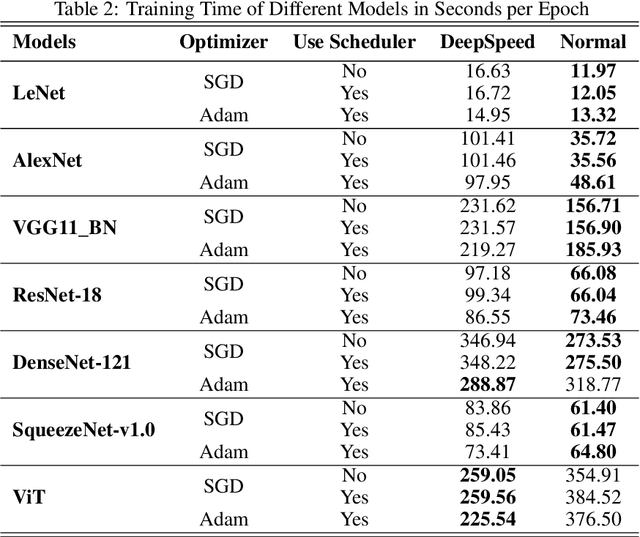
Deep Learning (DL) models are widely used in machine learning due to their performance and ability to deal with large datasets while producing high accuracy and performance metrics. The size of such datasets and the complexity of DL models cause such models to be complex, consuming large amount of resources and time to train. Many recent libraries and applications are introduced to deal with DL complexity and efficiency issues. In this paper, we evaluated one example, Microsoft DeepSpeed library through classification tasks. DeepSpeed public sources reported classification performance metrics on the LeNet architecture. We extended this through evaluating the library on several modern neural network architectures, including convolutional neural networks (CNNs) and Vision Transformer (ViT). Results indicated that DeepSpeed, while can make improvements in some of those cases, it has no or negative impact on others.