 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Object Heights From LiDAR & Aerial Imagery
Aug 02, 2024This work shows a procedural method for extracting object heights from LiDAR and aerial imagery. We discuss how to get heights and the future of LiDAR and imagery processing. SOTA object segmentation allows us to take get object heights with no deep learning background. Engineers will be keeping track of world data across generations and reprocessing them. They will be using older procedural methods like this paper and newer ones discussed here. SOTA methods are going beyond analysis and into generative AI. We cover both a procedural methodology and the newer ones performed with language models. These include point cloud, imagery and text encoding allowing for spatially aware AI.
Transforming Computer Security and Public Trust Through the Exploration of Fine-Tuning Large Language Models
Jun 02, 2024Large language models (LLMs) have revolutionized how we interact with machines. However, this technological advancement has been paralleled by the emergence of "Mallas," malicious services operating underground that exploit LLMs for nefarious purposes. Such services create malware, phishing attacks, and deceptive websites, escalating the cyber security threats landscape. This paper delves into the proliferation of Mallas by examining the use of various pre-trained language models and their efficiency and vulnerabilities when misused. Building on a dataset from the Common Vulnerabilities and Exposures (CVE) program, it explores fine-tuning methodologies to generate code and explanatory text related to identified vulnerabilities. This research aims to shed light on the operational strategies and exploitation techniques of Mallas, leading to the development of more secure and trustworthy AI applications. The paper concludes by emphasizing the need for further research, enhanced safeguards, and ethical guidelines to mitigate the risks associated with the malicious application of LLMs.
Mutation-Based Adversarial Attacks on Neural Text Detectors
Feb 11, 2023


Neural text detectors aim to decide the characteristics that distinguish neural (machine-generated) from human texts. To challenge such detectors, adversarial attacks can alter the statistical characteristics of the generated text, making the detection task more and more difficult. Inspired by the advances of mutation analysis in software development and testing, in this paper, we propose character- and word-based mutation operators for generating adversarial samples to attack state-of-the-art natural text detectors. This falls under white-box adversarial attacks. In such attacks, attackers have access to the original text and create mutation instances based on this original text. The ultimate goal is to confuse machine learning models and classifiers and decrease their prediction accuracy.
A Mutation-based Text Generation for Adversarial Machine Learning Applications
Dec 21, 2022Many natural language related applications involve text generation, created by humans or machines. While in many of those applications machines support humans, yet in few others, (e.g. adversarial machine learning, social bots and trolls) machines try to impersonate humans. In this scope, we proposed and evaluated several mutation-based text generation approaches. Unlike machine-based generated text, mutation-based generated text needs human text samples as inputs. We showed examples of mutation operators but this work can be extended in many aspects such as proposing new text-based mutation operators based on the nature of the application.
Synthetic Text Detection: Systemic Literature Review
Oct 01, 2022
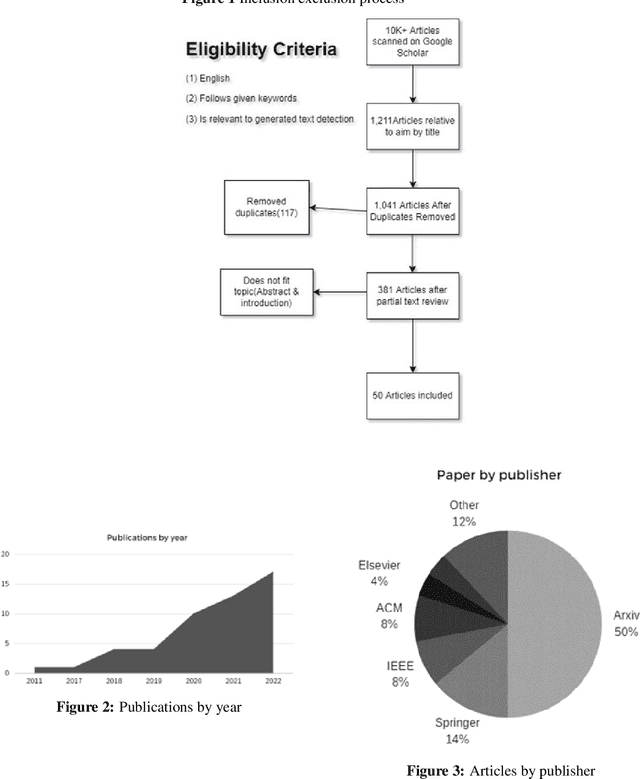

Within the text analysis and processing fields, generated text attacks have been made easier to create than ever before. To combat these attacks open sourcing models and datasets have become a major trend to create automated detection algorithms in defense of authenticity. For this purpose, synthetic text detection has become an increasingly viable topic of research. This review is written for the purpose of creating a snapshot of the state of current literature and easing the barrier to entry for future authors. Towards that goal, we identified few research trends and challenges in this field.