Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Goes Where: Predicting Object Distributions from Above
Paper and Code
Aug 02, 2018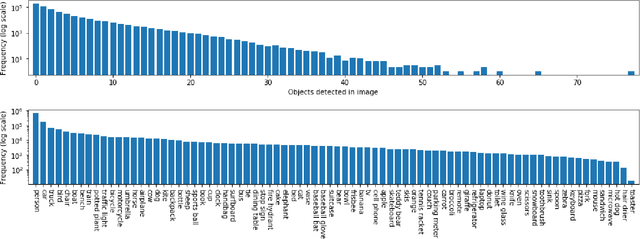

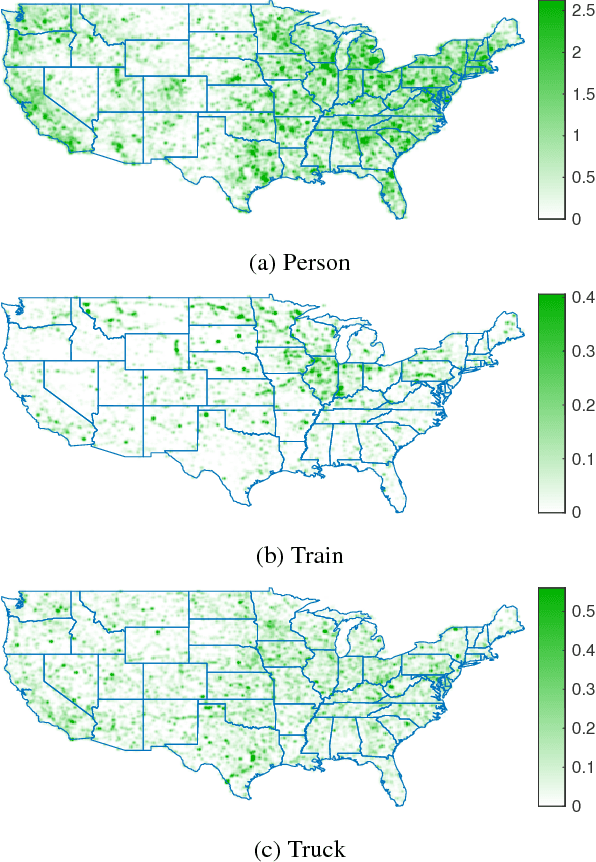
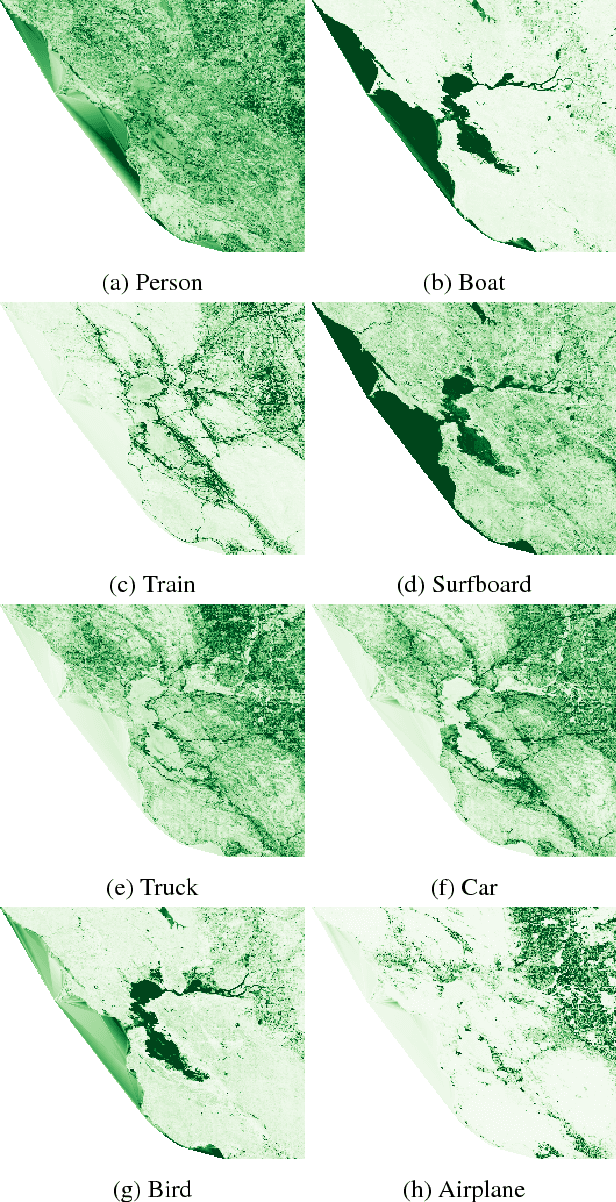
In this work, we propose a cross-view learning approach, in which images captured from a ground-level view are used as weakly supervised annotations for interpreting overhead imagery. The outcome is a convolutional neural network for overhead imagery that is capable of predicting the type and count of objects that are likely to be seen from a ground-level perspective. We demonstrate our approach on a large dataset of geotagged ground-level and overhead imagery and find that our network captures semantically meaningful features, despite being trained without manual annotations.
* 4 pages, 5 figures, IGARSS 2018
View paper on