 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifNet: Semantic Segmentation by Diffusion Networks
Oct 26, 2018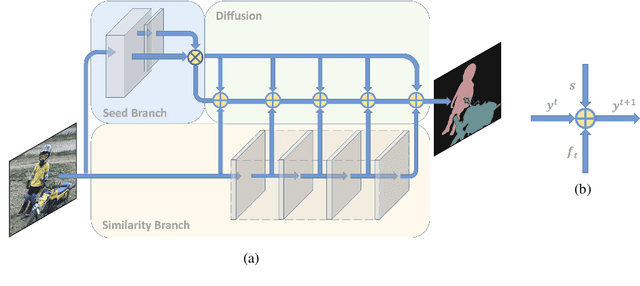
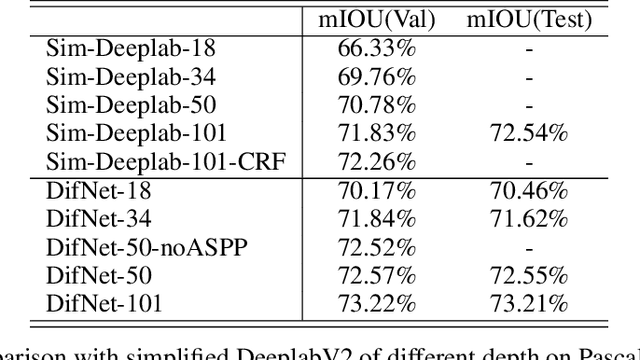
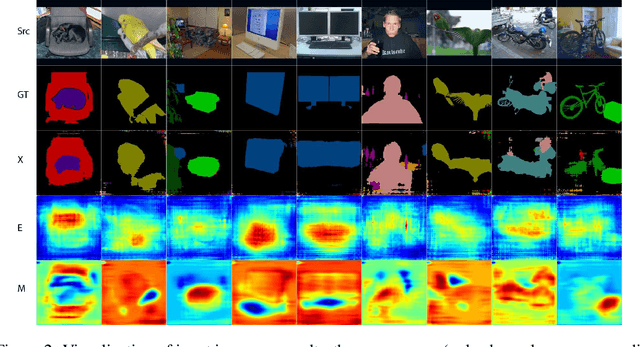
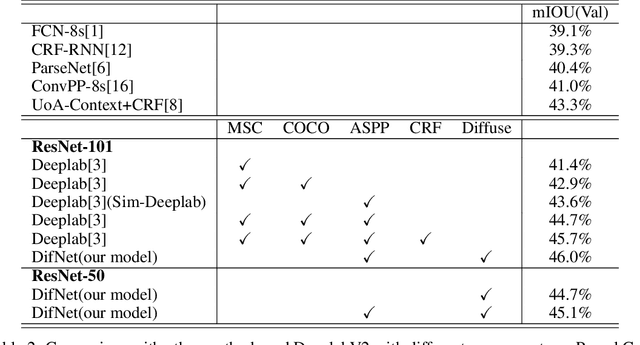
Deep Neural Networks (DNNs) have recently shown state of the art performance on semantic segmentation tasks, however, they still suffer from problems of poor boundary localization and spatial fragmented predictions. The difficulties lie in the requirement of making dense predictions from a long path model all at once since details are hard to keep when data goes through deeper layers. Instead, in this work, we decompose this difficult task into two relative simple sub-tasks: seed detection which is required to predict initial predictions without the need of wholeness and preciseness, and similarity estimation which measures the possibility of any two nodes belong to the same class without the need of knowing which class they are. We use one branch network for one sub-task each, and apply a cascade of random walks base on hierarchical semantics to approximate a complex diffusion process which propagates seed information to the whole image according to the estimated similarities. The proposed DifNet consistently produces improvements over the baseline models with the same depth and with the equivalent number of parameters, and also achieves promising performance on Pascal VOC and Pascal Context dataset. OurDifNet is trained end-to-end without complex loss functions.
Neuron-level Selective Context Aggregation for Scene Segmentation
Nov 22, 2017

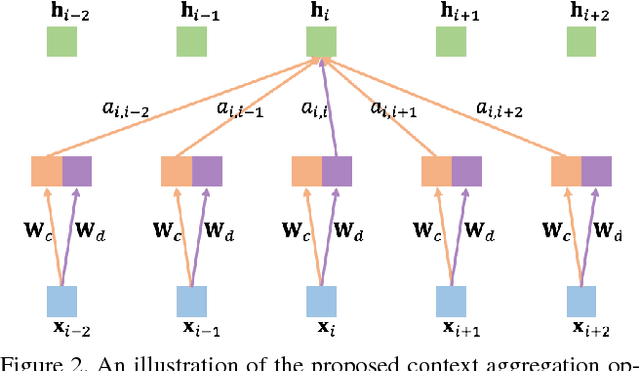
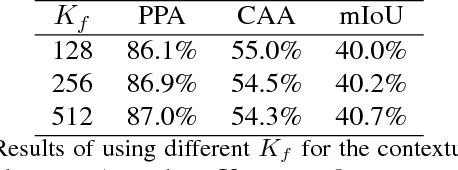
Contextual information provides important cues for disambiguating visually similar pixels in scene segmentation. In this paper, we introduce a neuron-level Selective Context Aggregation (SCA) module for scene segmentation, comprised of a contextual dependency predictor and a context aggregation operator. The dependency predictor is implicitly trained to infer contextual dependencies between different image regions. The context aggregation operator augments local representations with global context, which is aggregated selectively at each neuron according to its on-the-fly predicted dependencies. The proposed mechanism enables data-driven inference of contextual dependencies, and facilitates context-aware feature learning. The proposed method improves strong baselines built upon VGG16 on challenging scene segmentation datasets, which demonstrates its effectiveness in modeling context information.