 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLG-HCC: Local Geometry-Aware Hierarchical Context Compression for 3D Gaussian Splatting
Apr 01, 2026Although 3D Gaussian Splatting (3DGS) enables high-fidelity real-time rendering, its prohibitive storage overhead severely hinders practical deployment. Recent anchor-based 3DGS compression schemes reduce gaussian redundancy through some advanced context models. However, they overlook explicit geometric dependencies, leading to structural degradation and suboptimal ratedistortion performance. In this paper, we propose a Local Geometry-aware Hierarchical Context Compression framework for 3DGS(LG-HCC) that incorporates inter-anchor geometric correlations into anchor pruning and entropy coding for compact representation. Specifically, we introduce an Neighborhood-Aware Anchor Pruning (NAAP) strategy, which evaluates anchor importance via weighted neighborhood feature aggregation and then merges low-contribution anchors into salient neighbors, yielding a compact yet geometry-consistent anchor set. Moreover, we further develop a hierarchical entropy coding scheme, in which coarse-to-fine priors are exploited through a lightweight Geometry-Guided Convolution(GG-Conv) operator to enable spatially adaptive context modeling and rate-distortion optimization. Extensive experiments show that LG-HCC effectively alleviates structural preservation issues,achieving superior geometric integrity and rendering fidelity while reducing storage by up to 30.85x compared to the Scaffold-GS baseline on the Mip-NeRF360 dataset
Feature-aligned Motion Transformation for Efficient Dynamic Point Cloud Compression
Sep 18, 2025Dynamic point clouds are widely used in applications such as immersive reality, robotics, and autonomous driving. Efficient compression largely depends on accurate motion estimation and compensation, yet the irregular structure and significant local variations of point clouds make this task highly challenging. Current methods often rely on explicit motion estimation, whose encoded vectors struggle to capture intricate dynamics and fail to fully exploit temporal correlations. To overcome these limitations, we introduce a Feature-aligned Motion Transformation (FMT) framework for dynamic point cloud compression. FMT replaces explicit motion vectors with a spatiotemporal alignment strategy that implicitly models continuous temporal variations, using aligned features as temporal context within a latent-space conditional encoding framework. Furthermore, we design a random access (RA) reference strategy that enables bidirectional motion referencing and layered encoding, thereby supporting frame-level parallel compression. Extensive experiments demonstrate that our method surpasses D-DPCC and AdaDPCC in both encoding and decoding efficiency, while also achieving BD-Rate reductions of 20% and 9.4%, respectively. These results highlight the effectiveness of FMT in jointly improving compression efficiency and processing performance.
SPAC-Net: Rethinking Point Cloud Completion with Structural Prior
Nov 22, 2024



Point cloud completion aims to infer a complete shape from its partial observation. Many approaches utilize a pure encoderdecoder paradigm in which complete shape can be directly predicted by shape priors learned from partial scans, however, these methods suffer from the loss of details inevitably due to the feature abstraction issues. In this paper, we propose a novel framework,termed SPAC-Net, that aims to rethink the completion task under the guidance of a new structural prior, we call it interface. Specifically, our method first investigates Marginal Detector (MAD) module to localize the interface, defined as the intersection between the known observation and the missing parts. Based on the interface, our method predicts the coarse shape by learning the displacement from the points in interface move to their corresponding position in missing parts. Furthermore, we devise an additional Structure Supplement(SSP) module before the upsampling stage to enhance the structural details of the coarse shape, enabling the upsampling module to focus more on the upsampling task. Extensive experiments have been conducted on several challenging benchmarks, and the results demonstrate that our method outperforms existing state-of-the-art approaches.
Upsampling Autoencoder for Self-Supervised Point Cloud Learning
Mar 21, 2022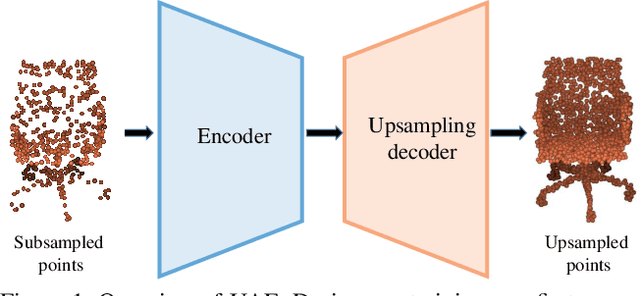
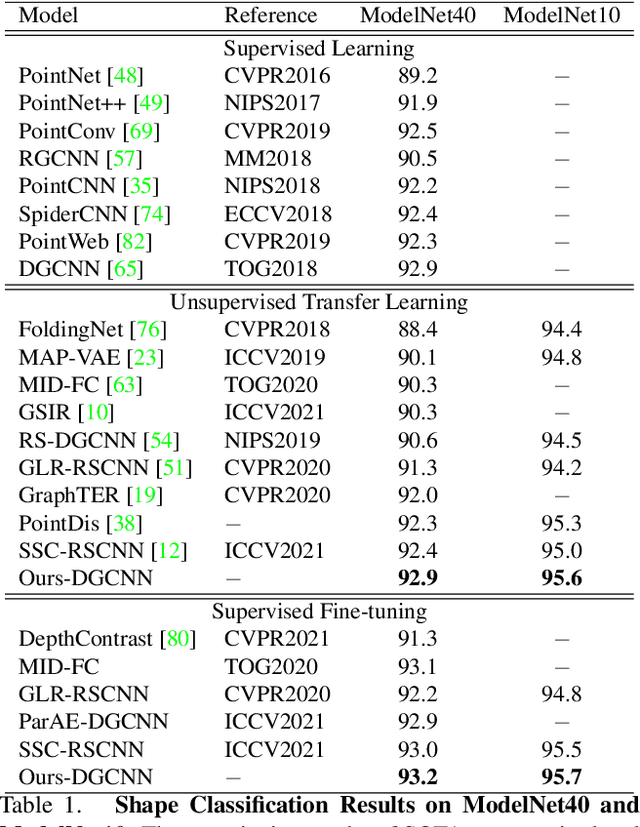
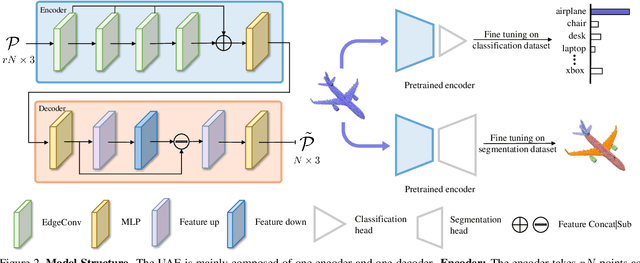
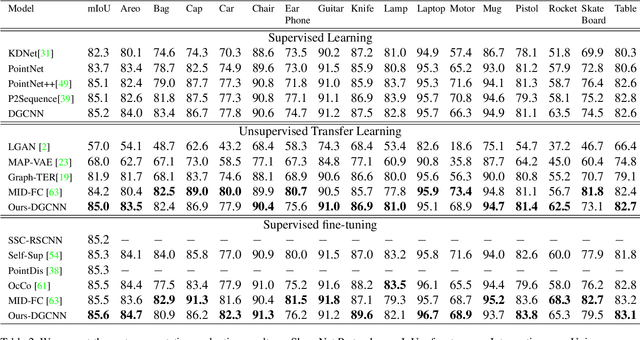
In computer-aided design (CAD) community, the point cloud data is pervasively applied in reverse engineering, where the point cloud analysis plays an important role. While a large number of supervised learning methods have been proposed to handle the unordered point clouds and demonstrated their remarkable success, their performance and applicability are limited to the costly data annotation. In this work, we propose a novel self-supervised pretraining model for point cloud learning without human annotations, which relies solely on upsampling operation to perform feature learning of point cloud in an effective manner. The key premise of our approach is that upsampling operation encourages the network to capture both high-level semantic information and low-level geometric information of the point cloud, thus the downstream tasks such as classification and segmentation will benefit from the pre-trained model. Specifically, our method first conducts the random subsampling from the input point cloud at a low proportion e.g., 12.5%. Then, we feed them into an encoder-decoder architecture, where an encoder is devised to operate only on the subsampled points, along with a upsampling decoder is adopted to reconstruct the original point cloud based on the learned features. Finally, we design a novel joint loss function which enforces the upsampled points to be similar with the original point cloud and uniformly distributed on the underlying shape surface. By adopting the pre-trained encoder weights as initialisation of models for downstream tasks, we find that our UAE outperforms previous state-of-the-art methods in shape classification, part segmentation and point cloud upsampling tasks. Code will be made publicly available upon acceptance.
Enhancing Quality for VVC Compressed Videos by Jointly Exploiting Spatial Details and Temporal Structure
Jan 28, 2019



In this paper, we propose a quality enhancement network for Versatile Video Coding (VVC) compressed videos by jointly exploiting spatial details and temporal structure (SDTS). The network consists of a temporal structure prediction subnet and a spatial detail enhancement subnet. The former subnet is used to estimate and compensate the temporal motion across frames, and the spatial detail subnet is used to reduce the compression artifacts and enhance the reconstruction quality of the VVC compressed video. Experimental results demonstrate the effectiveness of our SDTS-based approach. It offers over 7.82$\%$ BD-rate saving on the common test video sequences and achieves the state-of-the-art performance.
MGANet: A Robust Model for Quality Enhancement of Compressed Video
Nov 26, 2018


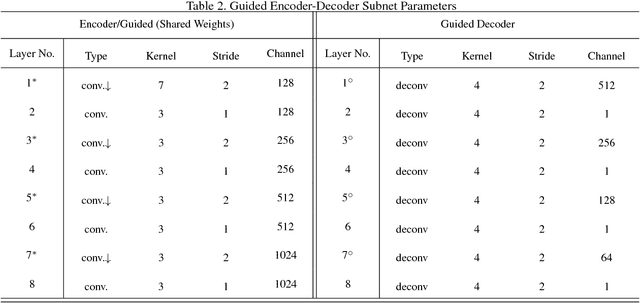
In video compression, most of the existing deep learning approaches concentrate on the visual quality of a single frame, while ignoring the useful priors as well as the temporal information of adjacent frames. In this paper, we propose a multi-frame guided attention network (MGANet) to enhance the quality of compressed videos. Our network is composed of a temporal encoder that discovers inter-frame relations, a guided encoder-decoder subnet that encodes and enhances the visual patterns of target-frame, and a multi-supervised reconstruction component that aggregates information to predict details. We design a bidirectional residual convolutional LSTM unit to implicitly discover frames variations over time with respect to the target frame. Meanwhile, the guided map is proposed to guide our network to concentrate more on the block boundary. Our approach takes advantage of intra-frame prior information and inter-frame information to improve the quality of compressed video. Experimental results show the robustness and superior performance of the proposed method.