 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGANet: A Robust Model for Quality Enhancement of Compressed Video
Paper and Code



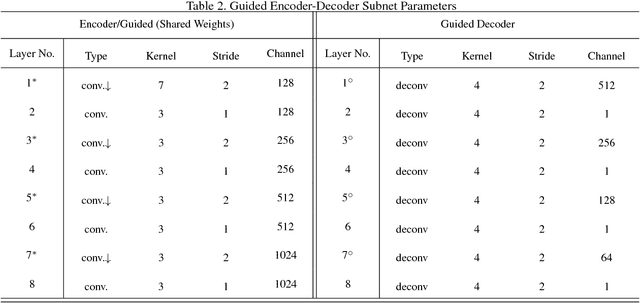
In video compression, most of the existing deep learning approaches concentrate on the visual quality of a single frame, while ignoring the useful priors as well as the temporal information of adjacent frames. In this paper, we propose a multi-frame guided attention network (MGANet) to enhance the quality of compressed videos. Our network is composed of a temporal encoder that discovers inter-frame relations, a guided encoder-decoder subnet that encodes and enhances the visual patterns of target-frame, and a multi-supervised reconstruction component that aggregates information to predict details. We design a bidirectional residual convolutional LSTM unit to implicitly discover frames variations over time with respect to the target frame. Meanwhile, the guided map is proposed to guide our network to concentrate more on the block boundary. Our approach takes advantage of intra-frame prior information and inter-frame information to improve the quality of compressed video. Experimental results show the robustness and superior performance of the proposed method.