 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairDropGS: Paired Dropout-Induced Consistency Regularization for Sparse-View Gaussian Splatting
May 13, 2026Dropout-based sparse-view 3D Gaussian Splatting (3DGS) methods alleviate overfitting by randomly suppressing Gaussian primitives during training. Existing methods mainly focus on designing increasingly sophisticated dropout strategies, while they overlook the resulting inconsistencies among different dropped Gaussian subsets. This oversight often leads to unstable reconstruction and suboptimal Gaussian representation learning.In this paper, we revisit dropout-based sparse-view 3DGS from a consistency regularization perspective and propose PairDropGS, a Paired Dropout-induced Consistency Regularization framework for sparse-view Gaussian splatting. Specifically, PairDropGS first constructs a pair of the dropped Gaussian subsets from a shared Gaussian field and designs a low-frequency consistency regularization to constrain their low-frequency rendered structures. This design encourages the shared Gaussian field to preserve stable scene layout and coarse geometry under different random dropouts, while avoiding excessive constraints on ambiguous high-frequency details. Moreover, we introduce a progressive consistency scheduling strategy to gradually strengthen the consistency regularization during training for stability and robustness of reconstruction. Extensive experiments on widely-used sparse-view benchmarks demonstrate that PairDropGS achieves superior training stability, significantly outperforms existing dropout-based 3DGS methods in reconstruction quality, while exhibiting the simplicity and plug-and-play nature for improving dropout-based optimization.
Neural Video Compression with Domain Transfer
May 13, 2026Content-adaptive compression has always been a key direction in neural video coding (NVC), aiming to mitigate the domain gap between training and testing data. Such gaps often arise from distributional discrepancies between training and inference data, which may cause noticeable performance degradation when the testing content differs from the training distribution. To tackle this challenge, we propose DCVC-DT, a domain transfer enhanced neural video compression framework. Specifically, we design a lightweight online domain transfer (DT) mechanism that dynamically adapts the encoded latent representation during inference, effectively bridging the domain gap without modifying the encoder or decoder parameters. In addition, we develop a frame-level dynamic RD (Rate and Distortion) adjustment scheme that actively regulates the ratio of R and D in the loss function based on quality fluctuation, thereby improving rate-distortion performance. Extensive experiments demonstrate that DCVC-DT achieves up to 6.21% bitrate savings over the baseline DCVC-DC, while significantly enhancing generalization to unseen testing data and alleviating error propagation. Our code is available at https://github.com/SunnyMass/DCVC-DT.
STGV: Spatio-Temporal Hash Encoding for Gaussian-based Video Representation
Apr 14, 20262D Gaussian Splatting (2DGS) has recently become a promising paradigm for high-quality video representation. However, existing methods employ content-agnostic or spatio-temporal feature overlapping embeddings to predict canonical Gaussian primitive deformations, which entangles static and dynamic components in videos and prevents modeling their distinct properties effectively. These result in inaccurate predictions for spatio-temporal deformations and unsatisfactory representation quality. To address these problems, this paper proposes a Spatio-Temporal hash encoding framework for Gaussian-based Video representation (STGV). By decomposing video features into learnable 2D spatial and 3D temporal hash encodings, STGV effectively facilitates the learning of motion patterns for dynamic components while maintaining background details for static elements. In addition, we construct a more stable and consistent initial canonical Gaussian representation through a key frame canonical initialization strategy, preventing from feature overlapping and a structurally incoherent geometry representation. Experimental results demonstrate that our method attains better video representation quality (+0.98 PSNR) against other Gaussian-based methods and achieves competitive performance in downstream video tasks.
DOC-GS: Dual-Domain Observation and Calibration for Reliable Sparse-View Gaussian Splatting
Apr 08, 2026Sparse-view reconstruction with 3D Gaussian Splatting (3DGS) is fundamentally ill-posed due to insufficient geometric supervision, often leading to severe overfitting and the emergence of structural distortions and translucent haze-like artifacts. While existing approaches attempt to alleviate this issue via dropout-based regularization, they are largely heuristic and lack a unified understanding of artifact formation. In this paper, we revisit sparse-view 3DGS reconstruction from a new perspective and identify the core challenge as the unobservability of Gaussian primitive reliability. Unreliable Gaussians are insufficiently constrained during optimization and accumulate as haze-like degradations in rendered images. Motivated by this observation, we propose a unified Dual-domain Observation and Calibration (DOC-GS) framework that models and corrects Gaussian reliability through the synergy of optimization-domain inductive bias and observation-domain evidence. Specifically, in the optimization domain, we characterize Gaussian reliability by the degree to which each primitive is constrained during training, and instantiate this signal via a Continuous Depth-Guided Dropout (CDGD) strategy, where the dropout probability serves as an explicit proxy for primitive reliability. This imposes a smooth depth-aware inductive bias to suppress weakly constrained Gaussians and improve optimization stability. In the observation domain, we establish a connection between floater artifacts and atmospheric scattering, and leverage the Dark Channel Prior (DCP) as a structural consistency cue to identify and accumulate anomalous regions. Based on cross-view aggregated evidence, we further design a reliability-driven geometric pruning strategy to remove low-confidence Gaussians.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
LG-HCC: Local Geometry-Aware Hierarchical Context Compression for 3D Gaussian Splatting
Apr 01, 2026Although 3D Gaussian Splatting (3DGS) enables high-fidelity real-time rendering, its prohibitive storage overhead severely hinders practical deployment. Recent anchor-based 3DGS compression schemes reduce gaussian redundancy through some advanced context models. However, they overlook explicit geometric dependencies, leading to structural degradation and suboptimal ratedistortion performance. In this paper, we propose a Local Geometry-aware Hierarchical Context Compression framework for 3DGS(LG-HCC) that incorporates inter-anchor geometric correlations into anchor pruning and entropy coding for compact representation. Specifically, we introduce an Neighborhood-Aware Anchor Pruning (NAAP) strategy, which evaluates anchor importance via weighted neighborhood feature aggregation and then merges low-contribution anchors into salient neighbors, yielding a compact yet geometry-consistent anchor set. Moreover, we further develop a hierarchical entropy coding scheme, in which coarse-to-fine priors are exploited through a lightweight Geometry-Guided Convolution(GG-Conv) operator to enable spatially adaptive context modeling and rate-distortion optimization. Extensive experiments show that LG-HCC effectively alleviates structural preservation issues,achieving superior geometric integrity and rendering fidelity while reducing storage by up to 30.85x compared to the Scaffold-GS baseline on the Mip-NeRF360 dataset
Content Adaptive based Motion Alignment Framework for Learned Video Compression
Dec 15, 2025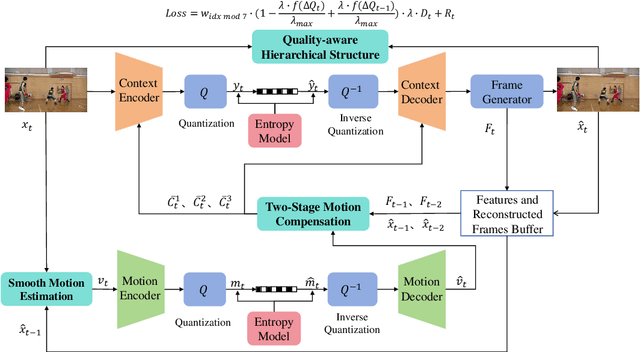

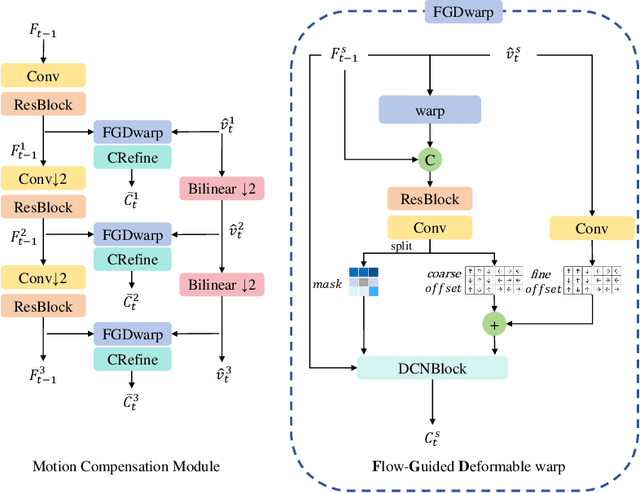
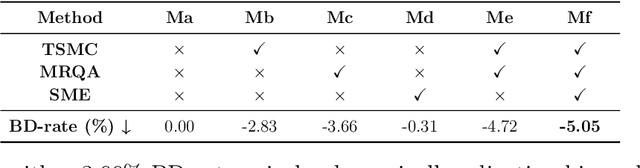
Recent advances in end-to-end video compression have shown promising results owing to their unified end-to-end learning optimization. However, such generalized frameworks often lack content-specific adaptation, leading to suboptimal compression performance. To address this, this paper proposes a content adaptive based motion alignment framework that improves performance by adapting encoding strategies to diverse content characteristics. Specifically, we first introduce a two-stage flow-guided deformable warping mechanism that refines motion compensation with coarse-to-fine offset prediction and mask modulation, enabling precise feature alignment. Second, we propose a multi-reference quality aware strategy that adjusts distortion weights based on reference quality, and applies it to hierarchical training to reduce error propagation. Third, we integrate a training-free module that downsamples frames by motion magnitude and resolution to obtain smooth motion estimation. Experimental results on standard test datasets demonstrate that our framework CAMA achieves significant improvements over state-of-the-art Neural Video Compression models, achieving a 24.95% BD-rate (PSNR) savings over our baseline model DCVC-TCM, while also outperforming reproduced DCVC-DC and traditional codec HM-16.25.
L-STEC: Learned Video Compression with Long-term Spatio-Temporal Enhanced Context
Dec 14, 2025Neural Video Compression has emerged in recent years, with condition-based frameworks outperforming traditional codecs. However, most existing methods rely solely on the previous frame's features to predict temporal context, leading to two critical issues. First, the short reference window misses long-term dependencies and fine texture details. Second, propagating only feature-level information accumulates errors over frames, causing prediction inaccuracies and loss of subtle textures. To address these, we propose the Long-term Spatio-Temporal Enhanced Context (L-STEC) method. We first extend the reference chain with LSTM to capture long-term dependencies. We then incorporate warped spatial context from the pixel domain, fusing spatio-temporal information through a multi-receptive field network to better preserve reference details. Experimental results show that L-STEC significantly improves compression by enriching contextual information, achieving 37.01% bitrate savings in PSNR and 31.65% in MS-SSIM compared to DCVC-TCM, outperforming both VTM-17.0 and DCVC-FM and establishing new state-of-the-art performance.
Feature-aligned Motion Transformation for Efficient Dynamic Point Cloud Compression
Sep 18, 2025Dynamic point clouds are widely used in applications such as immersive reality, robotics, and autonomous driving. Efficient compression largely depends on accurate motion estimation and compensation, yet the irregular structure and significant local variations of point clouds make this task highly challenging. Current methods often rely on explicit motion estimation, whose encoded vectors struggle to capture intricate dynamics and fail to fully exploit temporal correlations. To overcome these limitations, we introduce a Feature-aligned Motion Transformation (FMT) framework for dynamic point cloud compression. FMT replaces explicit motion vectors with a spatiotemporal alignment strategy that implicitly models continuous temporal variations, using aligned features as temporal context within a latent-space conditional encoding framework. Furthermore, we design a random access (RA) reference strategy that enables bidirectional motion referencing and layered encoding, thereby supporting frame-level parallel compression. Extensive experiments demonstrate that our method surpasses D-DPCC and AdaDPCC in both encoding and decoding efficiency, while also achieving BD-Rate reductions of 20% and 9.4%, respectively. These results highlight the effectiveness of FMT in jointly improving compression efficiency and processing performance.
Knowledge Graph-Infused Fine-Tuning for Structured Reasoning in Large Language Models
Aug 20, 2025This paper addresses the problems of missing reasoning chains and insufficient entity-level semantic understanding in large language models when dealing with tasks that require structured knowledge. It proposes a fine-tuning algorithm framework based on knowledge graph injection. The method builds on pretrained language models and introduces structured graph information for auxiliary learning. A graph neural network is used to encode entities and their relations, constructing a graph-based semantic representation. A fusion mechanism is then designed to jointly model the knowledge graph embeddings with the contextual representations from the language model. To enhance the robustness of knowledge integration, a gating mechanism is introduced to dynamically balance the contributions of linguistic semantics and structural knowledge. This effectively mitigates conflicts between different representational spaces. During training, a joint loss function is constructed to account for both task performance and structural alignment objectives. This helps improve the accuracy of entity prediction and semantic reasoning. The study also includes a series of systematic sensitivity experiments. It evaluates the effects of learning rate, graph coverage, and structural perturbations on model performance. The results further validate the effectiveness and stability of the proposed method across tasks such as entity recognition, question answering, and language generation. Experimental findings show that the proposed structure-aware fine-tuning framework significantly enhances the model's ability to represent complex semantic units. It demonstrates better semantic consistency and contextual logic modeling in scenarios involving structural reasoning and entity extraction.