 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards A Category-extended Object Detector without Relabeling or Conflicts
Dec 28, 2020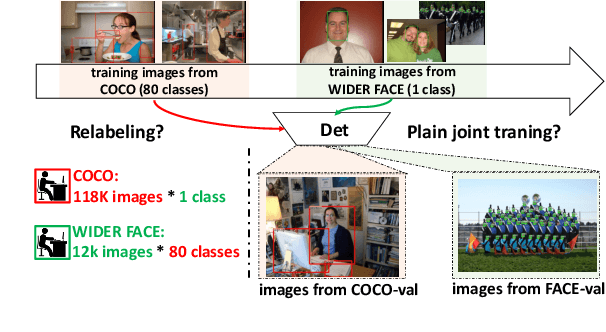

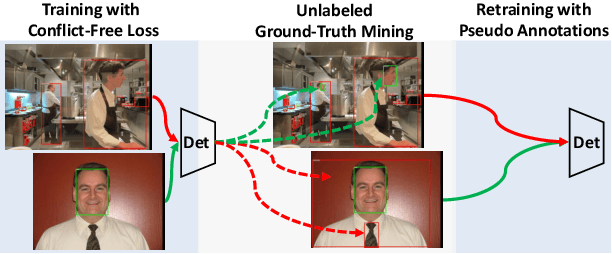
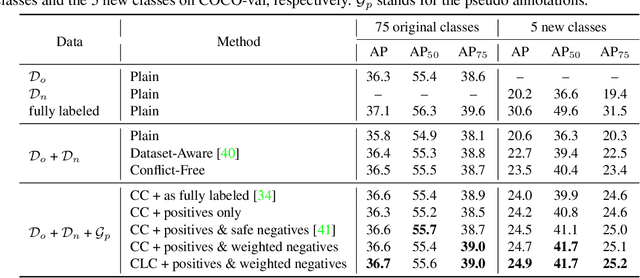
Object detectors are typically learned based on fully-annotated training data with fixed pre-defined categories. However, not all possible categories of interest can be known beforehand, as classes are often required to be increased progressively in many realistic applications. In such scenario, only the original training set annotated with the old classes and some new training data labeled with the new classes are available. In this paper, we aim at leaning a strong unified detector that can handle all categories based on the limited datasets without extra manual labor. Vanilla joint training without considering label ambiguity leads to heavy biases and poor performance due to the incomplete annotations. To avoid such situation, we propose a practical framework which focuses on three aspects: better base model, better unlabeled ground-truth mining strategy and better retraining method with pseudo annotations. First, a conflict-free loss is proposed to obtain a usable base detector. Second, we employ Monte Carlo Dropout to calculate the localization confidence, combined with the classification confidence, to mine more accurate bounding boxes. Third, we explore several strategies for making better use of pseudo annotations during retraining to achieve more powerful detectors. Extensive experiments conducted on multiple datasets demonstrate the effectiveness of our framework for category-extended object detectors.
RefineDetLite: A Lightweight One-stage Object Detection Framework for CPU-only Devices
Nov 20, 2019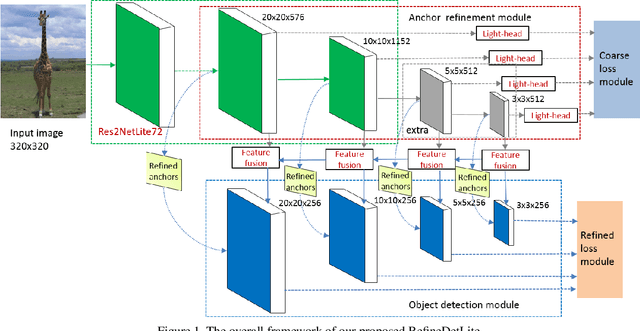
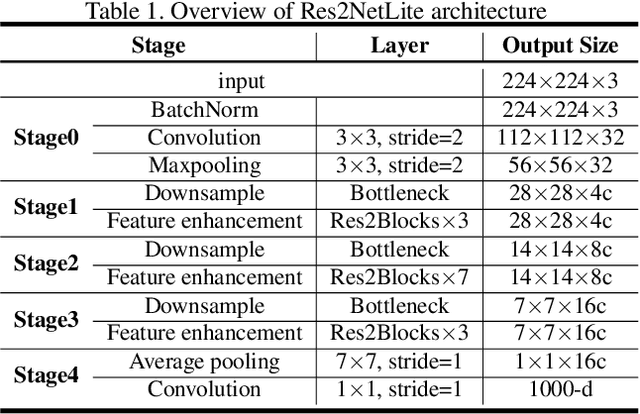
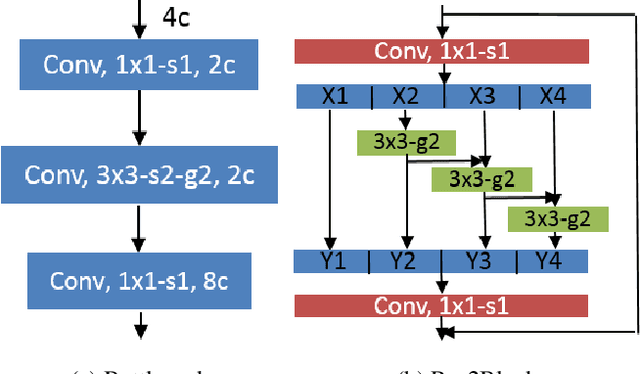
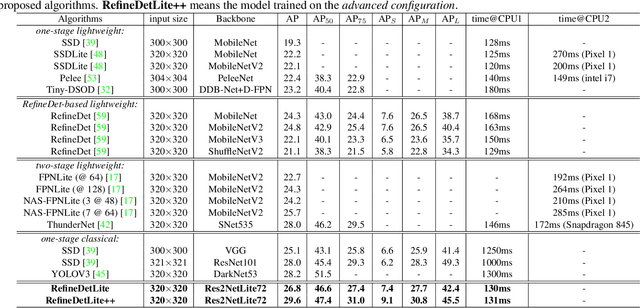
Previous state-of-the-art real-time object detectors have been reported on GPUs which are extremely expensive for processing massive data and in resource-restricted scenarios. Therefore, high efficiency object detectors on CPU-only devices are urgently-needed in industry. The floating-point operations (FLOPs) of networks are not strictly proportional to the running speed on CPU devices, which inspires the design of an exactly "fast" and "accurate" object detector. After investigating the concern gaps between classification networks and detection backbones, and following the design principles of efficient networks, we propose a lightweight residual-like backbone with large receptive fields and wide dimensions for low-level features, which are crucial for detection tasks. Correspondingly, we also design a light-head detection part to match the backbone capability. Furthermore, by analyzing the drawbacks of current one-stage detector training strategies, we also propose three orthogonal training strategies---IOU-guided loss, classes-aware weighting method and balanced multi-task training approach. Without bells and whistles, our proposed RefineDetLite achieves 26.8 mAP on the MSCOCO benchmark at a speed of 130 ms/pic on a single-thread CPU. The detection accuracy can be further increased to 29.6 mAP by integrating all the proposed training strategies, without apparent speed drop.
Improving Image Captioning with Conditional Generative Adversarial Nets
Sep 06, 2018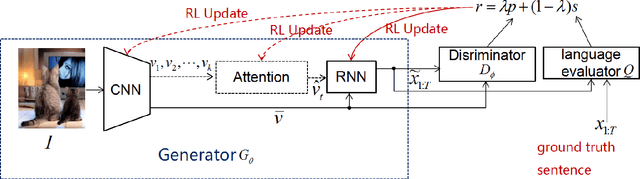
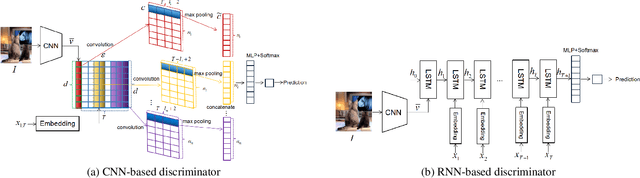
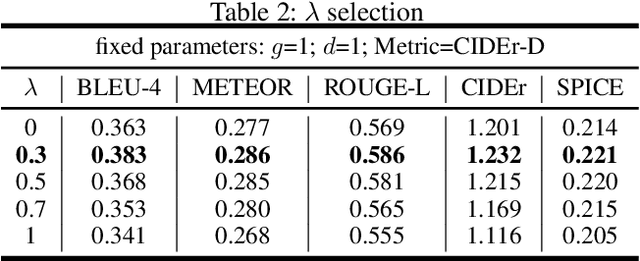
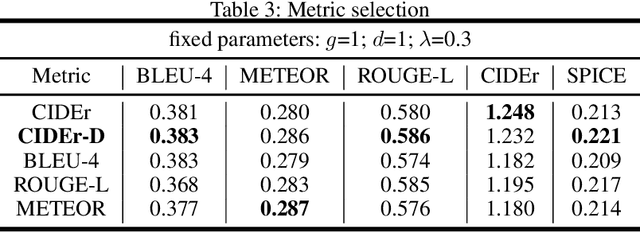
In this paper, we propose a novel conditional-generative-adversarial-nets-based image captioning framework as an extension of traditional reinforcement-learning (RL)-based encoder-decoder architecture. To deal with the inconsistent evaluation problem among different objective language metrics, we are motivated to design some "discriminator" networks to automatically and progressively determine whether generated caption is human described or machine generated. Two kinds of discriminator architectures (CNN and RNN-based structures) are introduced since each has its own advantages. The proposed algorithm is generic so that it can enhance any existing RL-based image captioning framework and we show that the conventional RL training method is just a special case of our approach. Empirically, we show consistent im- provements over all language evaluation metrics for different state-of-the-art image captioning models. In addition, the well-trained discriminators can also be viewed as objective image captioning evaluators