 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Image Captioning with Conditional Generative Adversarial Nets
Paper and Code
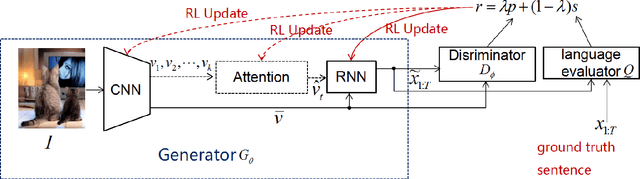
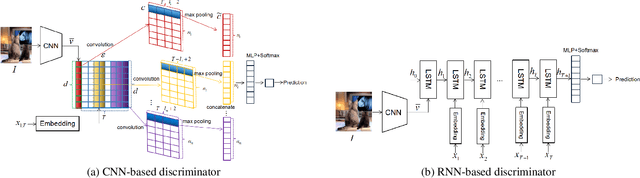
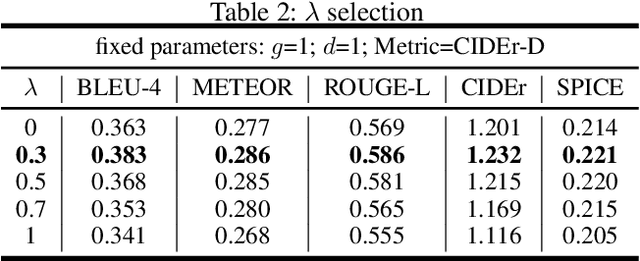
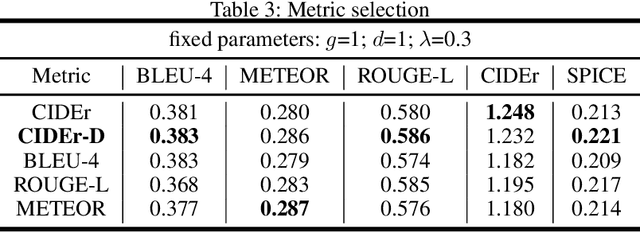
In this paper, we propose a novel conditional-generative-adversarial-nets-based image captioning framework as an extension of traditional reinforcement-learning (RL)-based encoder-decoder architecture. To deal with the inconsistent evaluation problem among different objective language metrics, we are motivated to design some "discriminator" networks to automatically and progressively determine whether generated caption is human described or machine generated. Two kinds of discriminator architectures (CNN and RNN-based structures) are introduced since each has its own advantages. The proposed algorithm is generic so that it can enhance any existing RL-based image captioning framework and we show that the conventional RL training method is just a special case of our approach. Empirically, we show consistent im- provements over all language evaluation metrics for different state-of-the-art image captioning models. In addition, the well-trained discriminators can also be viewed as objective image captioning evaluators