 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards A Category-extended Object Detector without Relabeling or Conflicts
Paper and Code
Dec 28, 2020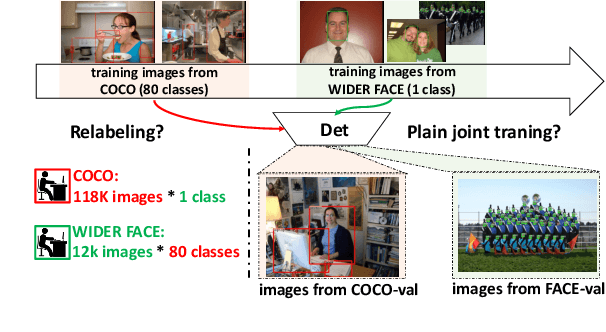

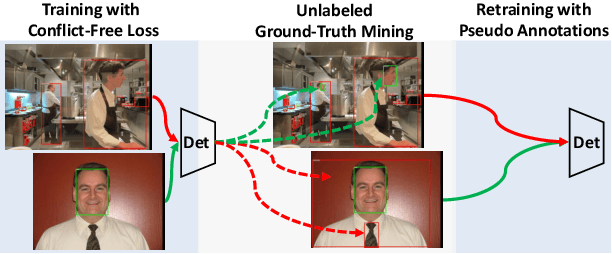
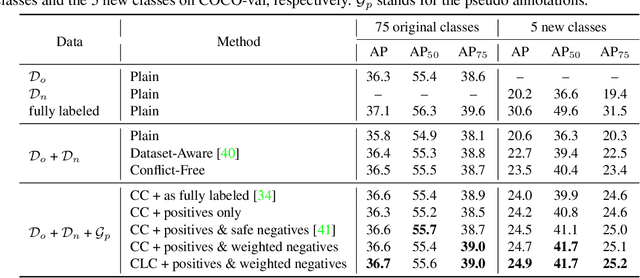
Object detectors are typically learned based on fully-annotated training data with fixed pre-defined categories. However, not all possible categories of interest can be known beforehand, as classes are often required to be increased progressively in many realistic applications. In such scenario, only the original training set annotated with the old classes and some new training data labeled with the new classes are available. In this paper, we aim at leaning a strong unified detector that can handle all categories based on the limited datasets without extra manual labor. Vanilla joint training without considering label ambiguity leads to heavy biases and poor performance due to the incomplete annotations. To avoid such situation, we propose a practical framework which focuses on three aspects: better base model, better unlabeled ground-truth mining strategy and better retraining method with pseudo annotations. First, a conflict-free loss is proposed to obtain a usable base detector. Second, we employ Monte Carlo Dropout to calculate the localization confidence, combined with the classification confidence, to mine more accurate bounding boxes. Third, we explore several strategies for making better use of pseudo annotations during retraining to achieve more powerful detectors. Extensive experiments conducted on multiple datasets demonstrate the effectiveness of our framework for category-extended object detectors.