 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Cross-Modal Compression for Generative Face Video Coding
Dec 17, 2025Generative face video coding (GFVC) is vital for modern applications like video conferencing, yet existing methods primarily focus on video motion while neglecting the significant bitrate contribution of audio. Despite the well-established correlation between audio and lip movements, this cross-modal coherence has not been systematically exploited for compression. To address this, we propose an Audio-Visual Cross-Modal Compression (AVCC) framework that jointly compresses audio and video streams. Our framework extracts motion information from video and tokenizes audio features, then aligns them through a unified audio-video diffusion process. This allows synchronized reconstruction of both modalities from a shared representation. In extremely low-rate scenarios, AVCC can even reconstruct one modality from the other. Experiments show that AVCC significantly outperforms the Versatile Video Coding (VVC) standard and state-of-the-art GFVC schemes in rate-distortion performance, paving the way for more efficient multimodal communication systems.
OmniGuard: Hybrid Manipulation Localization via Augmented Versatile Deep Image Watermarking
Dec 02, 2024



With the rapid growth of generative AI and its widespread application in image editing, new risks have emerged regarding the authenticity and integrity of digital content. Existing versatile watermarking approaches suffer from trade-offs between tamper localization precision and visual quality. Constrained by the limited flexibility of previous framework, their localized watermark must remain fixed across all images. Under AIGC-editing, their copyright extraction accuracy is also unsatisfactory. To address these challenges, we propose OmniGuard, a novel augmented versatile watermarking approach that integrates proactive embedding with passive, blind extraction for robust copyright protection and tamper localization. OmniGuard employs a hybrid forensic framework that enables flexible localization watermark selection and introduces a degradation-aware tamper extraction network for precise localization under challenging conditions. Additionally, a lightweight AIGC-editing simulation layer is designed to enhance robustness across global and local editing. Extensive experiments show that OmniGuard achieves superior fidelity, robustness, and flexibility. Compared to the recent state-of-the-art approach EditGuard, our method outperforms it by 4.25dB in PSNR of the container image, 20.7% in F1-Score under noisy conditions, and 14.8% in average bit accuracy.
Diffusion-Based Hierarchical Image Steganography
May 19, 2024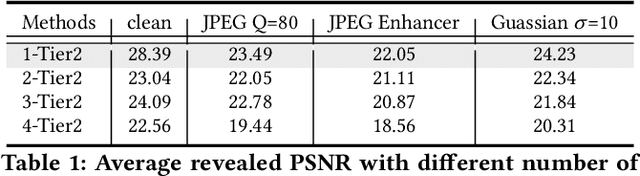
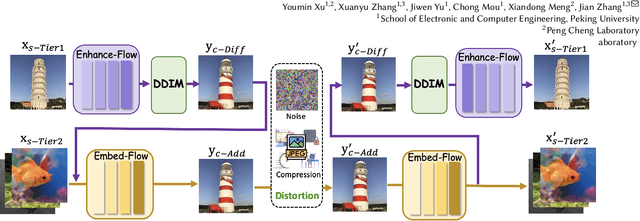


This paper introduces Hierarchical Image Steganography, a novel method that enhances the security and capacity of embedding multiple images into a single container using diffusion models. HIS assigns varying levels of robustness to images based on their importance, ensuring enhanced protection against manipulation. It adaptively exploits the robustness of the Diffusion Model alongside the reversibility of the Flow Model. The integration of Embed-Flow and Enhance-Flow improves embedding efficiency and image recovery quality, respectively, setting HIS apart from conventional multi-image steganography techniques. This innovative structure can autonomously generate a container image, thereby securely and efficiently concealing multiple images and text. Rigorous subjective and objective evaluations underscore our advantage in analytical resistance, robustness, and capacity, illustrating its expansive applicability in content safeguarding and privacy fortification.
V2A-Mark: Versatile Deep Visual-Audio Watermarking for Manipulation Localization and Copyright Protection
Apr 25, 2024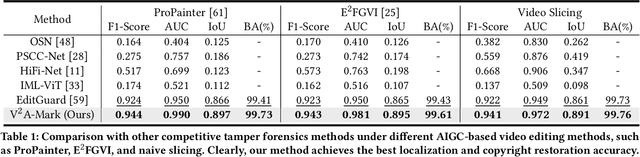
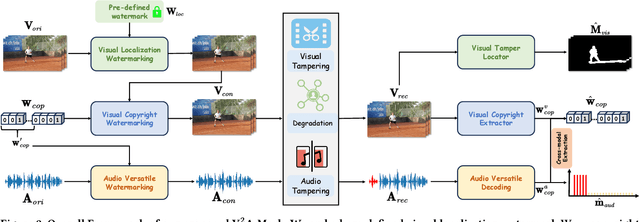
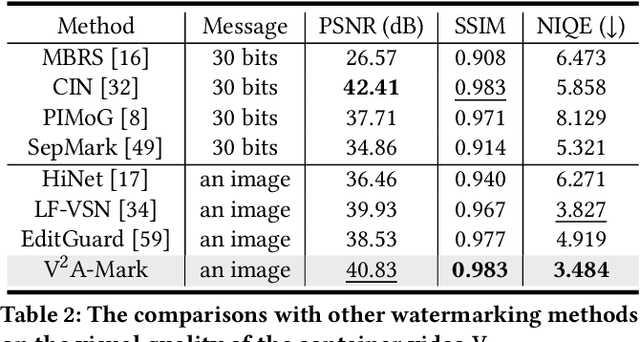
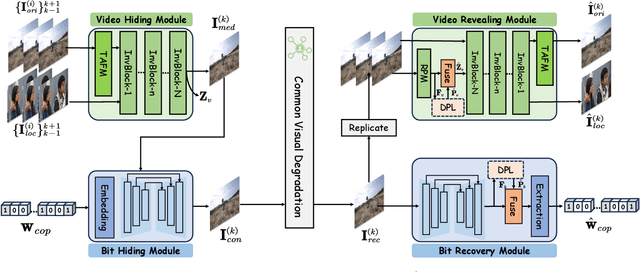
AI-generated video has revolutionized short video production, filmmaking, and personalized media, making video local editing an essential tool. However, this progress also blurs the line between reality and fiction, posing challenges in multimedia forensics. To solve this urgent issue, V2A-Mark is proposed to address the limitations of current video tampering forensics, such as poor generalizability, singular function, and single modality focus. Combining the fragility of video-into-video steganography with deep robust watermarking, our method can embed invisible visual-audio localization watermarks and copyright watermarks into the original video frames and audio, enabling precise manipulation localization and copyright protection. We also design a temporal alignment and fusion module and degradation prompt learning to enhance the localization accuracy and decoding robustness. Meanwhile, we introduce a sample-level audio localization method and a cross-modal copyright extraction mechanism to couple the information of audio and video frames. The effectiveness of V2A-Mark has been verified on a visual-audio tampering dataset, emphasizing its superiority in localization precision and copyright accuracy, crucial for the sustainable development of video editing in the AIGC video era.
EditGuard: Versatile Image Watermarking for Tamper Localization and Copyright Protection
Dec 12, 2023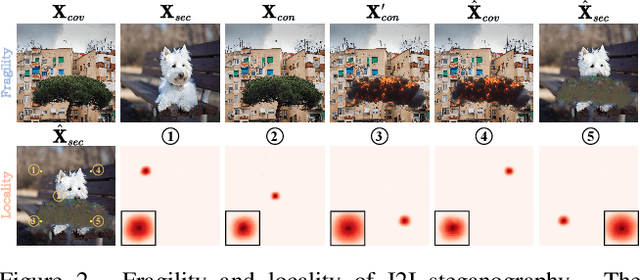
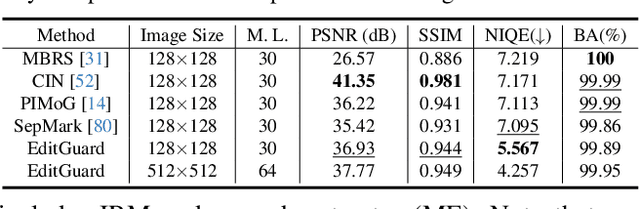
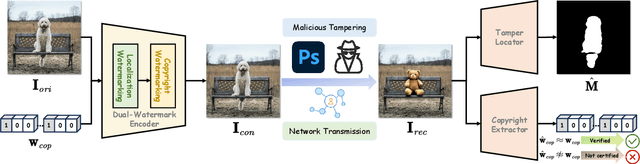
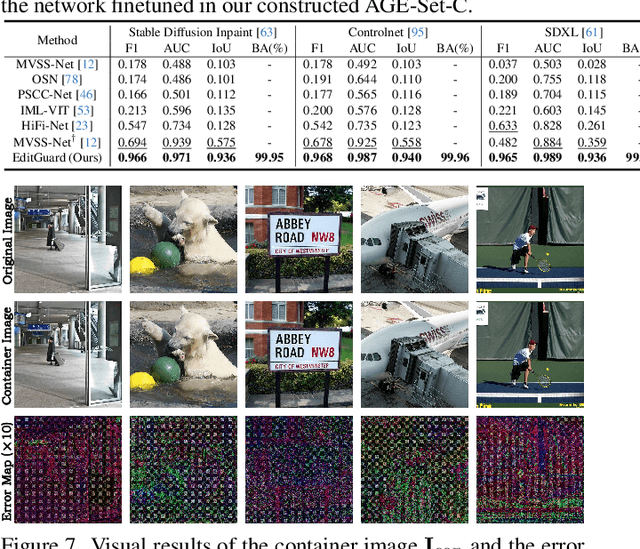
In the era where AI-generated content (AIGC) models can produce stunning and lifelike images, the lingering shadow of unauthorized reproductions and malicious tampering poses imminent threats to copyright integrity and information security. Current image watermarking methods, while widely accepted for safeguarding visual content, can only protect copyright and ensure traceability. They fall short in localizing increasingly realistic image tampering, potentially leading to trust crises, privacy violations, and legal disputes. To solve this challenge, we propose an innovative proactive forensics framework EditGuard, to unify copyright protection and tamper-agnostic localization, especially for AIGC-based editing methods. It can offer a meticulous embedding of imperceptible watermarks and precise decoding of tampered areas and copyright information. Leveraging our observed fragility and locality of image-into-image steganography, the realization of EditGuard can be converted into a united image-bit steganography issue, thus completely decoupling the training process from the tampering types. Extensive experiments demonstrate that our EditGuard balances the tamper localization accuracy, copyright recovery precision, and generalizability to various AIGC-based tampering methods, especially for image forgery that is difficult for the naked eye to detect. The project page is available at https://xuanyuzhang21.github.io/project/editguard/.
CRoSS: Diffusion Model Makes Controllable, Robust and Secure Image Steganography
May 26, 2023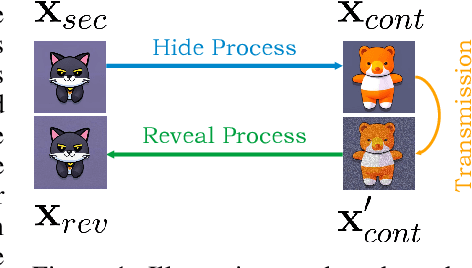
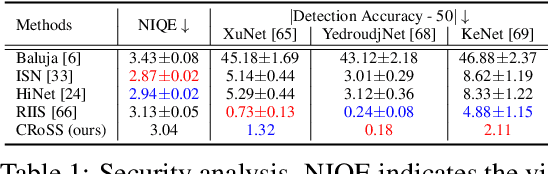


Current image steganography techniques are mainly focused on cover-based methods, which commonly have the risk of leaking secret images and poor robustness against degraded container images. Inspired by recent developments in diffusion models, we discovered that two properties of diffusion models, the ability to achieve translation between two images without training, and robustness to noisy data, can be used to improve security and natural robustness in image steganography tasks. For the choice of diffusion model, we selected Stable Diffusion, a type of conditional diffusion model, and fully utilized the latest tools from open-source communities, such as LoRAs and ControlNets, to improve the controllability and diversity of container images. In summary, we propose a novel image steganography framework, named Controllable, Robust and Secure Image Steganography (CRoSS), which has significant advantages in controllability, robustness, and security compared to cover-based image steganography methods. These benefits are obtained without additional training. To our knowledge, this is the first work to introduce diffusion models to the field of image steganography. In the experimental section, we conducted detailed experiments to demonstrate the advantages of our proposed CRoSS framework in controllability, robustness, and security.
Large-capacity and Flexible Video Steganography via Invertible Neural Network
Apr 24, 2023



Video steganography is the art of unobtrusively concealing secret data in a cover video and then recovering the secret data through a decoding protocol at the receiver end. Although several attempts have been made, most of them are limited to low-capacity and fixed steganography. To rectify these weaknesses, we propose a Large-capacity and Flexible Video Steganography Network (LF-VSN) in this paper. For large-capacity, we present a reversible pipeline to perform multiple videos hiding and recovering through a single invertible neural network (INN). Our method can hide/recover 7 secret videos in/from 1 cover video with promising performance. For flexibility, we propose a key-controllable scheme, enabling different receivers to recover particular secret videos from the same cover video through specific keys. Moreover, we further improve the flexibility by proposing a scalable strategy in multiple videos hiding, which can hide variable numbers of secret videos in a cover video with a single model and a single training session. Extensive experiments demonstrate that with the significant improvement of the video steganography performance, our proposed LF-VSN has high security, large hiding capacity, and flexibility. The source code is available at https://github.com/MC-E/LF-VSN.