 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffEditor: Boosting Accuracy and Flexibility on Diffusion-based Image Editing
Feb 04, 2024



Large-scale Text-to-Image (T2I) diffusion models have revolutionized image generation over the last few years. Although owning diverse and high-quality generation capabilities, translating these abilities to fine-grained image editing remains challenging. In this paper, we propose DiffEditor to rectify two weaknesses in existing diffusion-based image editing: (1) in complex scenarios, editing results often lack editing accuracy and exhibit unexpected artifacts; (2) lack of flexibility to harmonize editing operations, e.g., imagine new content. In our solution, we introduce image prompts in fine-grained image editing, cooperating with the text prompt to better describe the editing content. To increase the flexibility while maintaining content consistency, we locally combine stochastic differential equation (SDE) into the ordinary differential equation (ODE) sampling. In addition, we incorporate regional score-based gradient guidance and a time travel strategy into the diffusion sampling, further improving the editing quality. Extensive experiments demonstrate that our method can efficiently achieve state-of-the-art performance on various fine-grained image editing tasks, including editing within a single image (e.g., object moving, resizing, and content dragging) and across images (e.g., appearance replacing and object pasting). Our source code is released at https://github.com/MC-E/DragonDiffusion.
Deep Physics-Guided Unrolling Generalization for Compressed Sensing
Jul 18, 2023By absorbing the merits of both the model- and data-driven methods, deep physics-engaged learning scheme achieves high-accuracy and interpretable image reconstruction. It has attracted growing attention and become the mainstream for inverse imaging tasks. Focusing on the image compressed sensing (CS) problem, we find the intrinsic defect of this emerging paradigm, widely implemented by deep algorithm-unrolled networks, in which more plain iterations involving real physics will bring enormous computation cost and long inference time, hindering their practical application. A novel deep $\textbf{P}$hysics-guided un$\textbf{R}$olled recovery $\textbf{L}$earning ($\textbf{PRL}$) framework is proposed by generalizing the traditional iterative recovery model from image domain (ID) to the high-dimensional feature domain (FD). A compact multiscale unrolling architecture is then developed to enhance the network capacity and keep real-time inference speeds. Taking two different perspectives of optimization and range-nullspace decomposition, instead of building an algorithm-specific unrolled network, we provide two implementations: $\textbf{PRL-PGD}$ and $\textbf{PRL-RND}$. Experiments exhibit the significant performance and efficiency leading of PRL networks over other state-of-the-art methods with a large potential for further improvement and real application to other inverse imaging problems or optimization models.
DragonDiffusion: Enabling Drag-style Manipulation on Diffusion Models
Jul 05, 2023Despite the ability of existing large-scale text-to-image (T2I) models to generate high-quality images from detailed textual descriptions, they often lack the ability to precisely edit the generated or real images. In this paper, we propose a novel image editing method, DragonDiffusion, enabling Drag-style manipulation on Diffusion models. Specifically, we construct classifier guidance based on the strong correspondence of intermediate features in the diffusion model. It can transform the editing signals into gradients via feature correspondence loss to modify the intermediate representation of the diffusion model. Based on this guidance strategy, we also build a multi-scale guidance to consider both semantic and geometric alignment. Moreover, a cross-branch self-attention is added to maintain the consistency between the original image and the editing result. Our method, through an efficient design, achieves various editing modes for the generated or real images, such as object moving, object resizing, object appearance replacement, and content dragging. It is worth noting that all editing and content preservation signals come from the image itself, and the model does not require fine-tuning or additional modules. Our source code will be available at https://github.com/MC-E/DragonDiffusion.
Dynamic Path-Controllable Deep Unfolding Network for Compressive Sensing
Jun 28, 2023



Deep unfolding network (DUN) that unfolds the optimization algorithm into a deep neural network has achieved great success in compressive sensing (CS) due to its good interpretability and high performance. Each stage in DUN corresponds to one iteration in optimization. At the test time, all the sampling images generally need to be processed by all stages, which comes at a price of computation burden and is also unnecessary for the images whose contents are easier to restore. In this paper, we focus on CS reconstruction and propose a novel Dynamic Path-Controllable Deep Unfolding Network (DPC-DUN). DPC-DUN with our designed path-controllable selector can dynamically select a rapid and appropriate route for each image and is slimmable by regulating different performance-complexity tradeoffs. Extensive experiments show that our DPC-DUN is highly flexible and can provide excellent performance and dynamic adjustment to get a suitable tradeoff, thus addressing the main requirements to become appealing in practice. Codes are available at https://github.com/songjiechong/DPC-DUN.
Optimization-Inspired Cross-Attention Transformer for Compressive Sensing
Apr 27, 2023



By integrating certain optimization solvers with deep neural networks, deep unfolding network (DUN) with good interpretability and high performance has attracted growing attention in compressive sensing (CS). However, existing DUNs often improve the visual quality at the price of a large number of parameters and have the problem of feature information loss during iteration. In this paper, we propose an Optimization-inspired Cross-attention Transformer (OCT) module as an iterative process, leading to a lightweight OCT-based Unfolding Framework (OCTUF) for image CS. Specifically, we design a novel Dual Cross Attention (Dual-CA) sub-module, which consists of an Inertia-Supplied Cross Attention (ISCA) block and a Projection-Guided Cross Attention (PGCA) block. ISCA block introduces multi-channel inertia forces and increases the memory effect by a cross attention mechanism between adjacent iterations. And, PGCA block achieves an enhanced information interaction, which introduces the inertia force into the gradient descent step through a cross attention block. Extensive CS experiments manifest that our OCTUF achieves superior performance compared to state-of-the-art methods while training lower complexity. Codes are available at https://github.com/songjiechong/OCTUF.
Large-capacity and Flexible Video Steganography via Invertible Neural Network
Apr 24, 2023



Video steganography is the art of unobtrusively concealing secret data in a cover video and then recovering the secret data through a decoding protocol at the receiver end. Although several attempts have been made, most of them are limited to low-capacity and fixed steganography. To rectify these weaknesses, we propose a Large-capacity and Flexible Video Steganography Network (LF-VSN) in this paper. For large-capacity, we present a reversible pipeline to perform multiple videos hiding and recovering through a single invertible neural network (INN). Our method can hide/recover 7 secret videos in/from 1 cover video with promising performance. For flexibility, we propose a key-controllable scheme, enabling different receivers to recover particular secret videos from the same cover video through specific keys. Moreover, we further improve the flexibility by proposing a scalable strategy in multiple videos hiding, which can hide variable numbers of secret videos in a cover video with a single model and a single training session. Extensive experiments demonstrate that with the significant improvement of the video steganography performance, our proposed LF-VSN has high security, large hiding capacity, and flexibility. The source code is available at https://github.com/MC-E/LF-VSN.
Memory-Augmented Deep Unfolding Network for Compressive Sensing
Oct 25, 2021

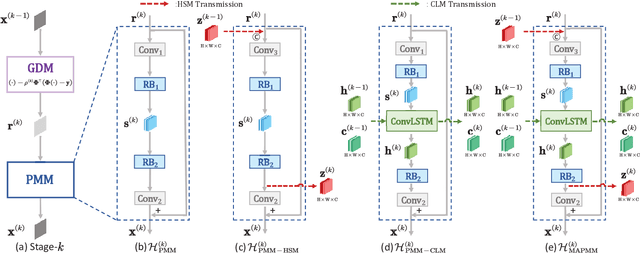
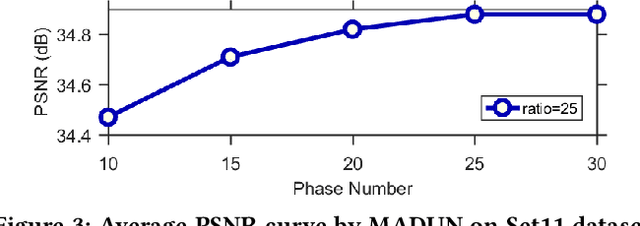
Mapping a truncated optimization method into a deep neural network, deep unfolding network (DUN) has attracted growing attention in compressive sensing (CS) due to its good interpretability and high performance. Each stage in DUNs corresponds to one iteration in optimization. By understanding DUNs from the perspective of the human brain's memory processing, we find there exists two issues in existing DUNs. One is the information between every two adjacent stages, which can be regarded as short-term memory, is usually lost seriously. The other is no explicit mechanism to ensure that the previous stages affect the current stage, which means memory is easily forgotten. To solve these issues, in this paper, a novel DUN with persistent memory for CS is proposed, dubbed Memory-Augmented Deep Unfolding Network (MADUN). We design a memory-augmented proximal mapping module (MAPMM) by combining two types of memory augmentation mechanisms, namely High-throughput Short-term Memory (HSM) and Cross-stage Long-term Memory (CLM). HSM is exploited to allow DUNs to transmit multi-channel short-term memory, which greatly reduces information loss between adjacent stages. CLM is utilized to develop the dependency of deep information across cascading stages, which greatly enhances network representation capability. Extensive CS experiments on natural and MR images show that with the strong ability to maintain and balance information our MADUN outperforms existing state-of-the-art methods by a large margin. The source code is available at https://github.com/jianzhangcs/MADUN/.