 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolysemous Language Gaussian Splatting via Matching-based Mask Lifting
Sep 26, 2025Lifting 2D open-vocabulary understanding into 3D Gaussian Splatting (3DGS) scenes is a critical challenge. However, mainstream methods suffer from three key flaws: (i) their reliance on costly per-scene retraining prevents plug-and-play application; (ii) their restrictive monosemous design fails to represent complex, multi-concept semantics; and (iii) their vulnerability to cross-view semantic inconsistencies corrupts the final semantic representation. To overcome these limitations, we introduce MUSplat, a training-free framework that abandons feature optimization entirely. Leveraging a pre-trained 2D segmentation model, our pipeline generates and lifts multi-granularity 2D masks into 3D, where we estimate a foreground probability for each Gaussian point to form initial object groups. We then optimize the ambiguous boundaries of these initial groups using semantic entropy and geometric opacity. Subsequently, by interpreting the object's appearance across its most representative viewpoints, a Vision-Language Model (VLM) distills robust textual features that reconciles visual inconsistencies, enabling open-vocabulary querying via semantic matching. By eliminating the costly per-scene training process, MUSplat reduces scene adaptation time from hours to mere minutes. On benchmark tasks for open-vocabulary 3D object selection and semantic segmentation, MUSplat outperforms established training-based frameworks while simultaneously addressing their monosemous limitations.
EPContrast: Effective Point-level Contrastive Learning for Large-scale Point Cloud Understanding
Oct 22, 2024
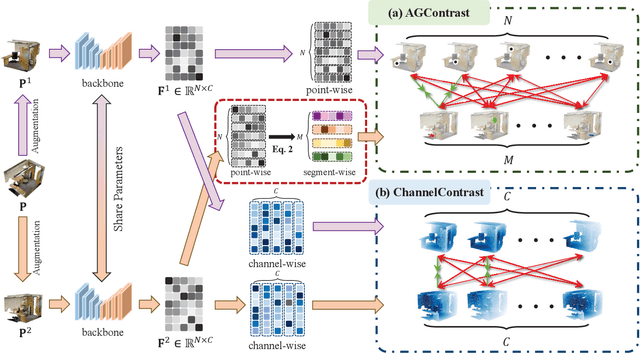


The acquisition of inductive bias through point-level contrastive learning holds paramount significance in point cloud pre-training. However, the square growth in computational requirements with the scale of the point cloud poses a substantial impediment to the practical deployment and execution. To address this challenge, this paper proposes an Effective Point-level Contrastive Learning method for large-scale point cloud understanding dubbed \textbf{EPContrast}, which consists of AGContrast and ChannelContrast. In practice, AGContrast constructs positive and negative pairs based on asymmetric granularity embedding, while ChannelContrast imposes contrastive supervision between channel feature maps. EPContrast offers point-level contrastive loss while concurrently mitigating the computational resource burden. The efficacy of EPContrast is substantiated through comprehensive validation on S3DIS and ScanNetV2, encompassing tasks such as semantic segmentation, instance segmentation, and object detection. In addition, rich ablation experiments demonstrate remarkable bias induction capabilities under label-efficient and one-epoch training settings.
Distribution Guidance Network for Weakly Supervised Point Cloud Semantic Segmentation
Oct 10, 2024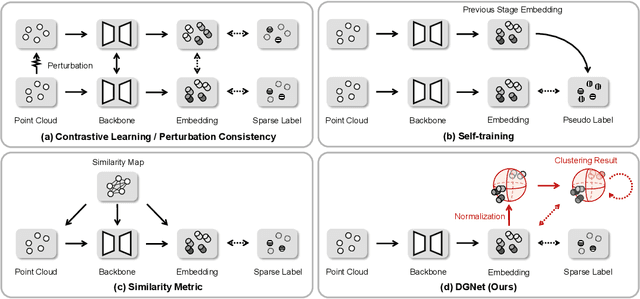
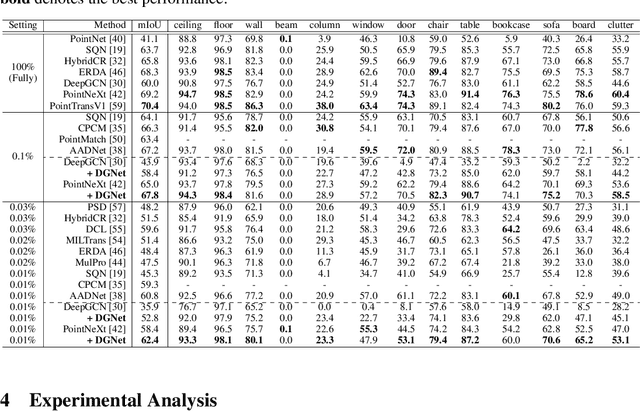
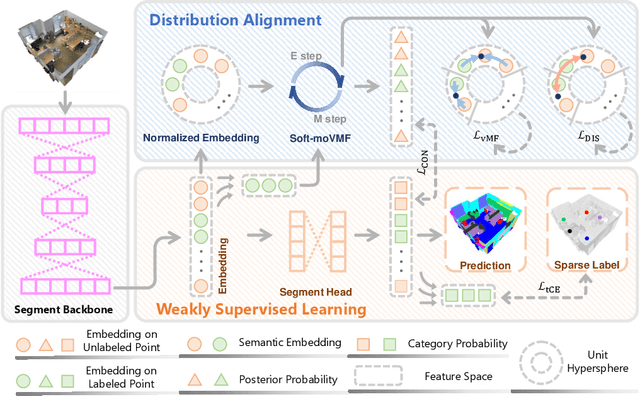

Despite alleviating the dependence on dense annotations inherent to fully supervised methods, weakly supervised point cloud semantic segmentation suffers from inadequate supervision signals. In response to this challenge, we introduce a novel perspective that imparts auxiliary constraints by regulating the feature space under weak supervision. Our initial investigation identifies which distributions accurately characterize the feature space, subsequently leveraging this priori to guide the alignment of the weakly supervised embeddings. Specifically, we analyze the superiority of the mixture of von Mises-Fisher distributions (moVMF) among several common distribution candidates. Accordingly, we develop a Distribution Guidance Network (DGNet), which comprises a weakly supervised learning branch and a distribution alignment branch. Leveraging reliable clustering initialization derived from the weakly supervised learning branch, the distribution alignment branch alternately updates the parameters of the moVMF and the network, ensuring alignment with the moVMF-defined latent space. Extensive experiments validate the rationality and effectiveness of our distribution choice and network design. Consequently, DGNet achieves state-of-the-art performance under multiple datasets and various weakly supervised settings.
Perspective+ Unet: Enhancing Segmentation with Bi-Path Fusion and Efficient Non-Local Attention for Superior Receptive Fields
Jun 20, 2024



Precise segmentation of medical images is fundamental for extracting critical clinical information, which plays a pivotal role in enhancing the accuracy of diagnoses, formulating effective treatment plans, and improving patient outcomes. Although Convolutional Neural Networks (CNNs) and non-local attention methods have achieved notable success in medical image segmentation, they either struggle to capture long-range spatial dependencies due to their reliance on local features, or face significant computational and feature integration challenges when attempting to address this issue with global attention mechanisms. To overcome existing limitations in medical image segmentation, we propose a novel architecture, Perspective+ Unet. This framework is characterized by three major innovations: (i) It introduces a dual-pathway strategy at the encoder stage that combines the outcomes of traditional and dilated convolutions. This not only maintains the local receptive field but also significantly expands it, enabling better comprehension of the global structure of images while retaining detail sensitivity. (ii) The framework incorporates an efficient non-local transformer block, named ENLTB, which utilizes kernel function approximation for effective long-range dependency capture with linear computational and spatial complexity. (iii) A Spatial Cross-Scale Integrator strategy is employed to merge global dependencies and local contextual cues across model stages, meticulously refining features from various levels to harmonize global and local information. Experimental results on the ACDC and Synapse datasets demonstrate the effectiveness of our proposed Perspective+ Unet. The code is available in the supplementary material.
Adaptive Annotation Distribution for Weakly Supervised Point Cloud Semantic Segmentation
Dec 11, 2023Weakly supervised point cloud semantic segmentation has attracted a lot of attention due to its ability to alleviate the heavy reliance on fine-grained annotations of point clouds. However, in practice, sparse annotation usually exhibits a distinct non-uniform distribution in point cloud, which poses challenges for weak supervision. To address these issues, we propose an adaptive annotation distribution method for weakly supervised point cloud semantic segmentation. Specifically, we introduce the probability density function into the gradient sampling approximation analysis and investigate the impact of sparse annotations distributions. Based on our analysis, we propose a label-aware point cloud downsampling strategy to increase the proportion of annotations involved in the training stage. Furthermore, we design the multiplicative dynamic entropy as the gradient calibration function to mitigate the gradient bias caused by non-uniformly distributed sparse annotations and explicitly reduce the epistemic uncertainty. Without any prior restrictions and additional information, our proposed method achieves comprehensive performance improvements at multiple label rates with different annotation distributions on S3DIS, ScanNetV2 and SemanticKITTI.
Scribble-Supervised Semantic Segmentation by Uncertainty Reduction on Neural Representation and Self-Supervision on Neural Eigenspace
Feb 19, 2021

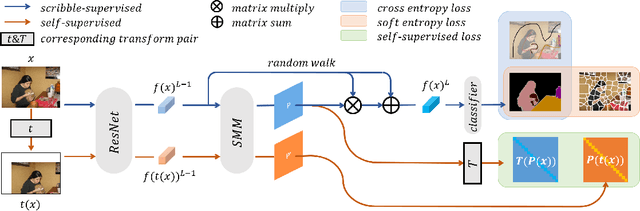
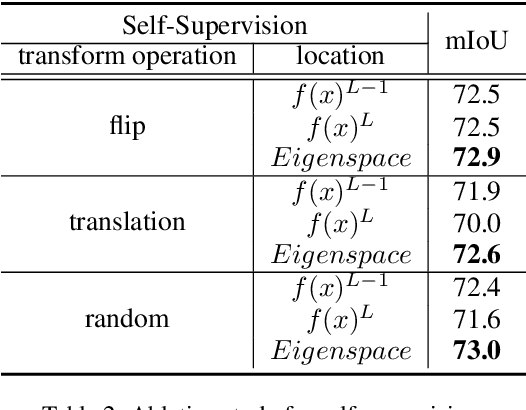
Scribble-supervised semantic segmentation has gained much attention recently for its promising performance without high-quality annotations. Due to the lack of supervision, confident and consistent predictions are usually hard to obtain. Typically, people handle these problems to either adopt an auxiliary task with the well-labeled dataset or incorporate the graphical model with additional requirements on scribble annotations. Instead, this work aims to achieve semantic segmentation by scribble annotations directly without extra information and other limitations. Specifically, we propose holistic operations, including minimizing entropy and a network embedded random walk on neural representation to reduce uncertainty. Given the probabilistic transition matrix of a random walk, we further train the network with self-supervision on its neural eigenspace to impose consistency on predictions between related images. Comprehensive experiments and ablation studies verify the proposed approach, which demonstrates superiority over others; it is even comparable to some full-label supervised ones and works well when scribbles are randomly shrunk or dropped.
Scribble-Supervised Semantic Segmentation by Random Walk on Neural Representation and Self-Supervision on Neural Eigenspace
Nov 12, 2020

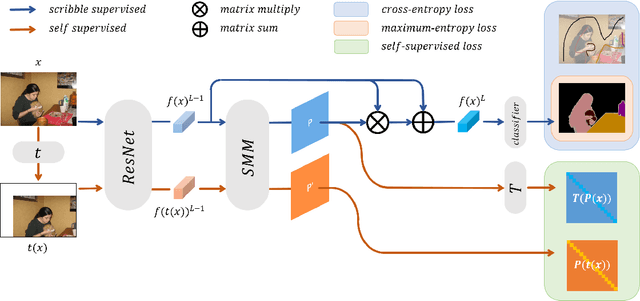
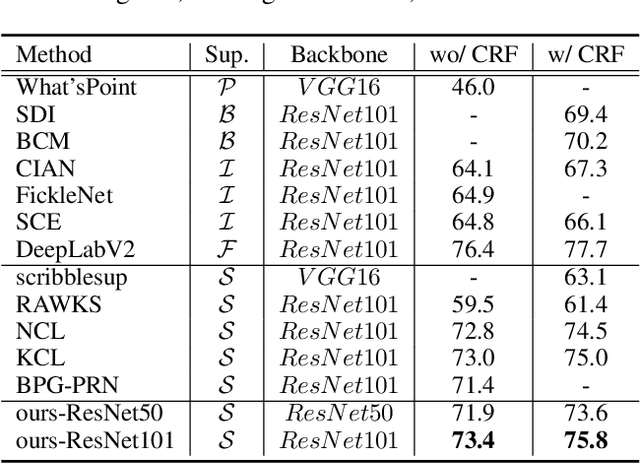
Scribble-supervised semantic segmentation has gained much attention recently for its promising performance without high-quality annotations. Many approaches have been proposed. Typically, they handle this problem to either introduce a well-labeled dataset from another related task, turn to iterative refinement and post-processing with the graphical model, or manipulate the scribble label. This work aims to achieve semantic segmentation supervised by scribble label directly without auxiliary information and other intermediate manipulation. Specifically, we impose diffusion on neural representation by random walk and consistency on neural eigenspace by self-supervision, which forces the neural network to produce dense and consistent predictions over the whole dataset. The random walk embedded in the network will compute a probabilistic transition matrix, with which the neural representation diffused to be uniform. Moreover, given the probabilistic transition matrix, we apply the self-supervision on its eigenspace for consistency in the image's main parts. In addition to comparing the common scribble dataset, we also conduct experiments on the modified datasets that randomly shrink and even drop the scribbles on image objects. The results demonstrate the superiority of the proposed method and are even comparable to some full-label supervised ones. The code and datasets are available at https://github.com/panzhiyi/RW-SS.
Bi-Directional Attention for Joint Instance and Semantic Segmentation in Point Clouds
Mar 11, 2020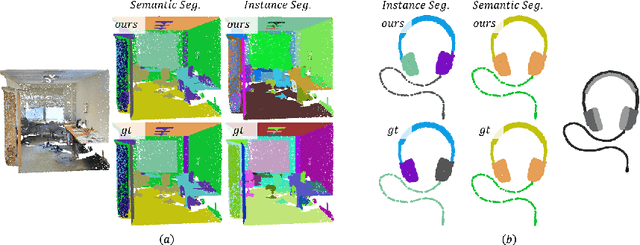

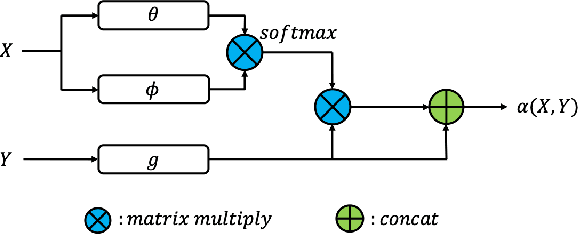
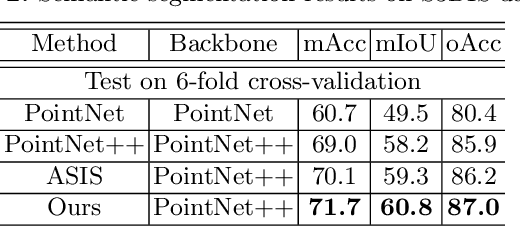
Instance segmentation in point clouds is one of the most fine-grained ways to understand the 3D scene. Due to its close relationship to semantic segmentation, many works approach these two tasks simultaneously and leverage the benefits of multi-task learning. However, most of them only considered simple strategies such as element-wise feature fusion, which may not lead to mutual promotion. In this work, we build a Bi-Directional Attention module on backbone neural networks for 3D point cloud perception, which uses similarity matrix measured from features for one task to help aggregate non-local information for the other task, avoiding the potential feature exclusion and task conflict. From comprehensive experiments and ablation studies on the S3DIS dataset and the PartNet dataset, the superiority of our method is verified. Moreover, the mechanism of how bi-directional attention module helps joint instance and semantic segmentation is also analyzed.
Super Diffusion for Salient Object Detection
Nov 22, 2018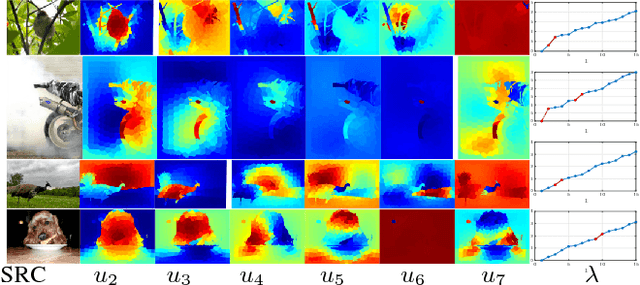
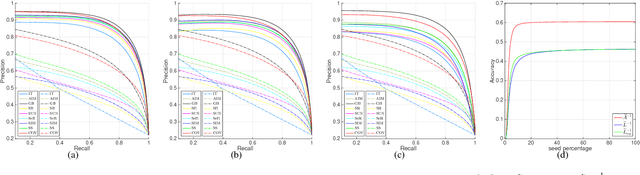
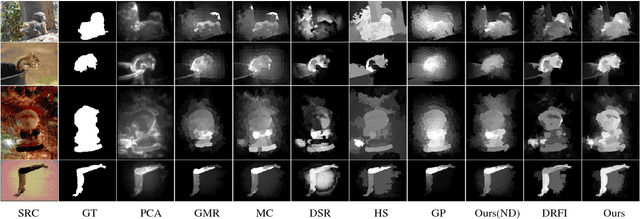
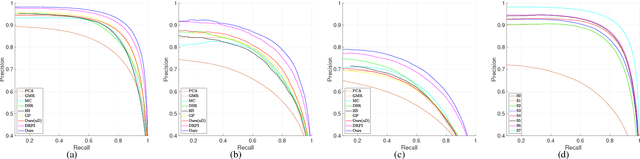
One major branch of saliency object detection methods is diffusion-based which construct a graph model on a given image and diffuse seed saliency values to the whole graph by a diffusion matrix. While their performance is sensitive to specific feature spaces and scales used for the diffusion matrix definition, little work has been published to systematically promote the robustness and accuracy of salient object detection under the generic mechanism of diffusion. In this work, we firstly present a novel view of the working mechanism of the diffusion process based on mathematical analysis, which reveals that the diffusion process is actually computing the similarity of nodes with respect to the seeds based on diffusion maps. Following this analysis, we propose super diffusion, a novel inclusive learning-based framework for salient object detection, which makes the optimum and robust performance by integrating a large pool of feature spaces, scales and even features originally computed for non-diffusion-based salient object detection. A closed-form solution of the optimal parameters for the integration is determined through supervised learning. At the local level, we propose to promote each individual diffusion before the integration. Our mathematical analysis reveals the close relationship between saliency diffusion and spectral clustering. Based on this, we propose to re-synthesize each individual diffusion matrix from the most discriminative eigenvectors and the constant eigenvector (for saliency normalization). The proposed framework is implemented and experimented on prevalently used benchmark datasets, consistently leading to state-of-the-art performance.