 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework to Super-Resolve Face Images of Varied Low Resolutions
Jun 06, 2023The existing face image super-resolution (FSR) algorithms usually train a specific model for a specific low input resolution for optimal results. By contrast, we explore in this work a unified framework that is trained once and then used to super-resolve input face images of varied low resolutions. For that purpose, we propose a novel neural network architecture that is composed of three anchor auto-encoders, one feature weight regressor and a final image decoder. The three anchor auto-encoders are meant for optimal FSR for three pre-defined low input resolutions, or named anchor resolutions, respectively. An input face image of an arbitrary low resolution is firstly up-scaled to the target resolution by bi-cubic interpolation and then fed to the three auto-encoders in parallel. The three encoded anchor features are then fused with weights determined by the feature weight regressor. At last, the fused feature is sent to the final image decoder to derive the super-resolution result. As shown by experiments, the proposed algorithm achieves robust and state-of-the-art performance over a wide range of low input resolutions by a single framework. Code and models will be made available after the publication of this work.
Super Diffusion for Salient Object Detection
Nov 22, 2018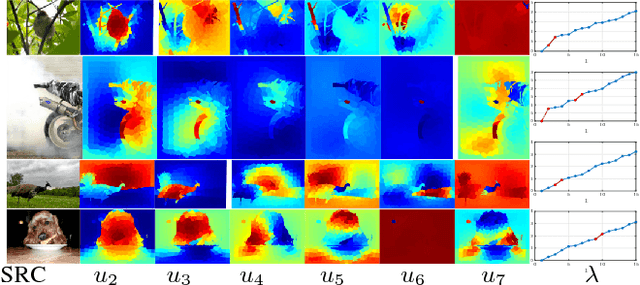
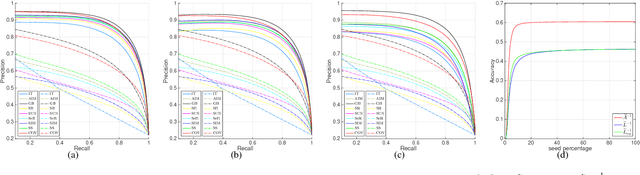
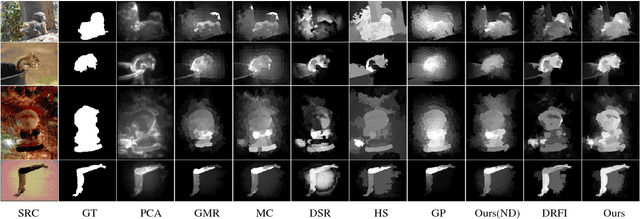
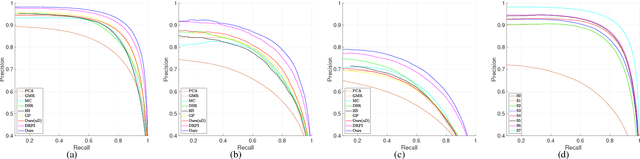
One major branch of saliency object detection methods is diffusion-based which construct a graph model on a given image and diffuse seed saliency values to the whole graph by a diffusion matrix. While their performance is sensitive to specific feature spaces and scales used for the diffusion matrix definition, little work has been published to systematically promote the robustness and accuracy of salient object detection under the generic mechanism of diffusion. In this work, we firstly present a novel view of the working mechanism of the diffusion process based on mathematical analysis, which reveals that the diffusion process is actually computing the similarity of nodes with respect to the seeds based on diffusion maps. Following this analysis, we propose super diffusion, a novel inclusive learning-based framework for salient object detection, which makes the optimum and robust performance by integrating a large pool of feature spaces, scales and even features originally computed for non-diffusion-based salient object detection. A closed-form solution of the optimal parameters for the integration is determined through supervised learning. At the local level, we propose to promote each individual diffusion before the integration. Our mathematical analysis reveals the close relationship between saliency diffusion and spectral clustering. Based on this, we propose to re-synthesize each individual diffusion matrix from the most discriminative eigenvectors and the constant eigenvector (for saliency normalization). The proposed framework is implemented and experimented on prevalently used benchmark datasets, consistently leading to state-of-the-art performance.