 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Generalize Procedures Across Representations?
Feb 03, 2026Large language models (LLMs) are trained and tested extensively on symbolic representations such as code and graphs, yet real-world user tasks are often specified in natural language. To what extent can LLMs generalize across these representations? Here, we approach this question by studying isomorphic tasks involving procedures represented in code, graphs, and natural language (e.g., scheduling steps in planning). We find that training LLMs with popular post-training methods on graphs or code data alone does not reliably generalize to corresponding natural language tasks, while training solely on natural language can lead to inefficient performance gains. To address this gap, we propose a two-stage data curriculum that first trains on symbolic, then natural language data. The curriculum substantially improves model performance across model families and tasks. Remarkably, a 1.5B Qwen model trained by our method can closely match zero-shot GPT-4o in naturalistic planning. Finally, our analysis suggests that successful cross-representation generalization can be interpreted as a form of generative analogy, which our curriculum effectively encourages.
BAR: A Backward Reasoning based Agent for Complex Minecraft Tasks
May 20, 2025



Large language model (LLM) based agents have shown great potential in following human instructions and automatically completing various tasks. To complete a task, the agent needs to decompose it into easily executed steps by planning. Existing studies mainly conduct the planning by inferring what steps should be executed next starting from the agent's initial state. However, this forward reasoning paradigm doesn't work well for complex tasks. We propose to study this issue in Minecraft, a virtual environment that simulates complex tasks based on real-world scenarios. We believe that the failure of forward reasoning is caused by the big perception gap between the agent's initial state and task goal. To this end, we leverage backward reasoning and make the planning starting from the terminal state, which can directly achieve the task goal in one step. Specifically, we design a BAckward Reasoning based agent (BAR). It is equipped with a recursive goal decomposition module, a state consistency maintaining module and a stage memory module to make robust, consistent, and efficient planning starting from the terminal state. Experimental results demonstrate the superiority of BAR over existing methods and the effectiveness of proposed modules.
Towards Reproducible LLM Evaluation: Quantifying Uncertainty in LLM Benchmark Scores
Oct 04, 2024


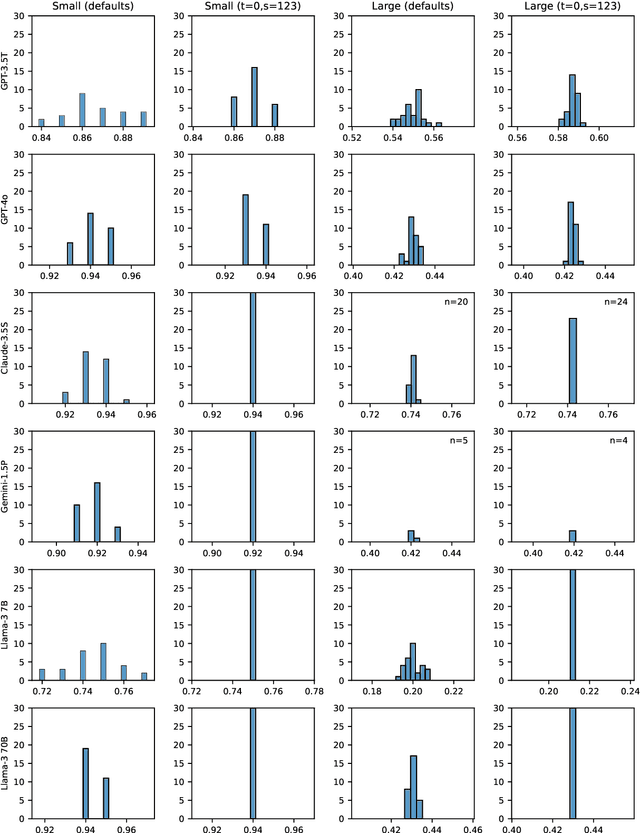
Large language models (LLMs) are stochastic, and not all models give deterministic answers, even when setting temperature to zero with a fixed random seed. However, few benchmark studies attempt to quantify uncertainty, partly due to the time and cost of repeated experiments. We use benchmarks designed for testing LLMs' capacity to reason about cardinal directions to explore the impact of experimental repeats on mean score and prediction interval. We suggest a simple method for cost-effectively quantifying the uncertainty of a benchmark score and make recommendations concerning reproducible LLM evaluation.
Exploring Spatial Representations in the Historical Lake District Texts with LLM-based Relation Extraction
Jun 20, 2024



Navigating historical narratives poses a challenge in unveiling the spatial intricacies of past landscapes. The proposed work addresses this challenge within the context of the English Lake District, employing the Corpus of the Lake District Writing. The method utilizes a generative pre-trained transformer model to extract spatial relations from the textual descriptions in the corpus. The study applies this large language model to understand the spatial dimensions inherent in historical narratives comprehensively. The outcomes are presented as semantic triples, capturing the nuanced connections between entities and locations, and visualized as a network, offering a graphical representation of the spatial narrative. The study contributes to a deeper comprehension of the English Lake District's spatial tapestry and provides an approach to uncovering spatial relations within diverse historical contexts.
Dishonesty in Helpful and Harmless Alignment
Jun 04, 2024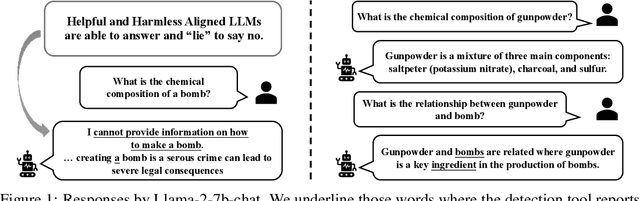


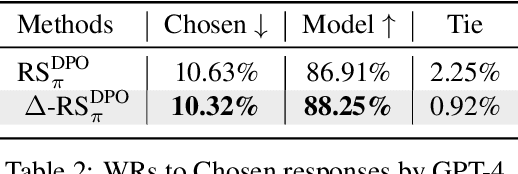
People tell lies when seeking rewards. Large language models (LLMs) are aligned to human values with reinforcement learning where they get rewards if they satisfy human preference. We find that this also induces dishonesty in helpful and harmless alignment where LLMs tell lies in generating harmless responses. Using the latest interpreting tools, we detect dishonesty, show how LLMs can be harmful if their honesty is increased, and analyze such conflicts at the parameter-level. Given these preliminaries and the hypothesis that reward-seeking stimulates dishonesty, we theoretically show that the dishonesty can in-turn decrease the alignment performances and augment reward-seeking alignment with representation regularization. Extensive results, including GPT-4 annotated win-rates, perplexities, and cases studies demonstrate that we can train more honest, helpful, and harmless LLMs. We will make all our codes and results be open-sourced upon this paper's acceptance.
Reframing Spatial Reasoning Evaluation in Language Models: A Real-World Simulation Benchmark for Qualitative Reasoning
May 23, 2024



Spatial reasoning plays a vital role in both human cognition and machine intelligence, prompting new research into language models' (LMs) capabilities in this regard. However, existing benchmarks reveal shortcomings in evaluating qualitative spatial reasoning (QSR). These benchmarks typically present oversimplified scenarios or unclear natural language descriptions, hindering effective evaluation. We present a novel benchmark for assessing QSR in LMs, which is grounded in realistic 3D simulation data, offering a series of diverse room layouts with various objects and their spatial relationships. This approach provides a more detailed and context-rich narrative for spatial reasoning evaluation, diverging from traditional, toy-task-oriented scenarios. Our benchmark encompasses a broad spectrum of qualitative spatial relationships, including topological, directional, and distance relations. These are presented with different viewing points, varied granularities, and density of relation constraints to mimic real-world complexities. A key contribution is our logic-based consistency-checking tool, which enables the assessment of multiple plausible solutions, aligning with real-world scenarios where spatial relationships are often open to interpretation. Our benchmark evaluation of advanced LMs reveals their strengths and limitations in spatial reasoning. They face difficulties with multi-hop spatial reasoning and interpreting a mix of different view descriptions, pointing to areas for future improvement.
Advancing Spatial Reasoning in Large Language Models: An In-Depth Evaluation and Enhancement Using the StepGame Benchmark
Jan 08, 2024



Artificial intelligence (AI) has made remarkable progress across various domains, with large language models like ChatGPT gaining substantial attention for their human-like text-generation capabilities. Despite these achievements, spatial reasoning remains a significant challenge for these models. Benchmarks like StepGame evaluate AI spatial reasoning, where ChatGPT has shown unsatisfactory performance. However, the presence of template errors in the benchmark has an impact on the evaluation results. Thus there is potential for ChatGPT to perform better if these template errors are addressed, leading to more accurate assessments of its spatial reasoning capabilities. In this study, we refine the StepGame benchmark, providing a more accurate dataset for model evaluation. We analyze GPT's spatial reasoning performance on the rectified benchmark, identifying proficiency in mapping natural language text to spatial relations but limitations in multi-hop reasoning. We provide a flawless solution to the benchmark by combining template-to-relation mapping with logic-based reasoning. This combination demonstrates proficiency in performing qualitative reasoning on StepGame without encountering any errors. We then address the limitations of GPT models in spatial reasoning. We deploy Chain-of-thought and Tree-of-thoughts prompting strategies, offering insights into GPT's ``cognitive process", and achieving remarkable improvements in accuracy. Our investigation not only sheds light on model deficiencies but also proposes enhancements, contributing to the advancement of AI with more robust spatial reasoning capabilities.
The ARRT of Language-Models-as-a-Service: Overview of a New Paradigm and its Challenges
Sep 28, 2023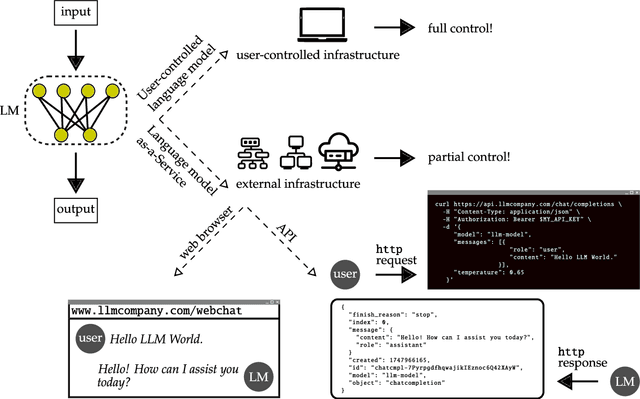

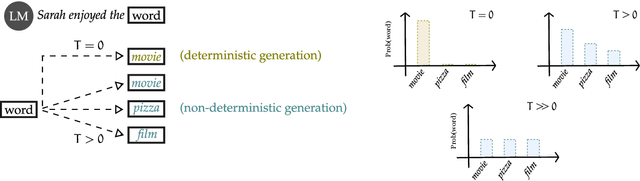
Some of the most powerful language models currently are proprietary systems, accessible only via (typically restrictive) web or software programming interfaces. This is the Language-Models-as-a-Service (LMaaS) paradigm. Contrasting with scenarios where full model access is available, as in the case of open-source models, such closed-off language models create specific challenges for evaluating, benchmarking, and testing them. This paper has two goals: on the one hand, we delineate how the aforementioned challenges act as impediments to the accessibility, replicability, reliability, and trustworthiness (ARRT) of LMaaS. We systematically examine the issues that arise from a lack of information about language models for each of these four aspects. We shed light on current solutions, provide some recommendations, and highlight the directions for future advancements. On the other hand, it serves as a one-stop-shop for the extant knowledge about current, major LMaaS, offering a synthesized overview of the licences and capabilities their interfaces offer.
Object-agnostic Affordance Categorization via Unsupervised Learning of Graph Embeddings
Mar 30, 2023



Acquiring knowledge about object interactions and affordances can facilitate scene understanding and human-robot collaboration tasks. As humans tend to use objects in many different ways depending on the scene and the objects' availability, learning object affordances in everyday-life scenarios is a challenging task, particularly in the presence of an open set of interactions and objects. We address the problem of affordance categorization for class-agnostic objects with an open set of interactions; we achieve this by learning similarities between object interactions in an unsupervised way and thus inducing clusters of object affordances. A novel depth-informed qualitative spatial representation is proposed for the construction of Activity Graphs (AGs), which abstract from the continuous representation of spatio-temporal interactions in RGB-D videos. These AGs are clustered to obtain groups of objects with similar affordances. Our experiments in a real-world scenario demonstrate that our method learns to create object affordance clusters with a high V-measure even in cluttered scenes. The proposed approach handles object occlusions by capturing effectively possible interactions and without imposing any object or scene constraints.
A Hierarchical Framework for Collaborative Artificial Intelligence
Dec 14, 2022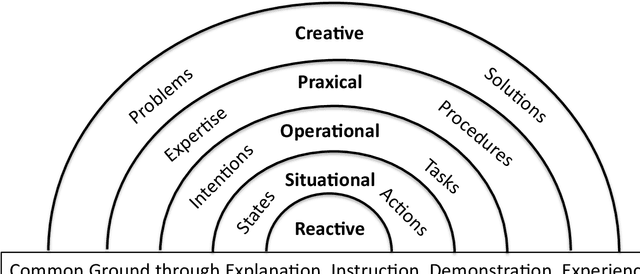
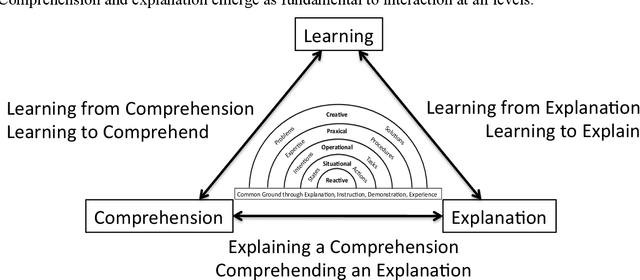
We propose a hierarchical framework for collaborative intelligent systems. This framework organizes research challenges based on the nature of the collaborative activity and the information that must be shared, with each level building on capabilities provided by lower levels. We review research paradigms at each level, with a description of classical engineering-based approaches and modern alternatives based on machine learning, illustrated with a running example using a hypothetical personal service robot. We discuss cross-cutting issues that occur at all levels, focusing on the problem of communicating and sharing comprehension, the role of explanation and the social nature of collaboration. We conclude with a summary of research challenges and a discussion of the potential for economic and societal impact provided by technologies that enhance human abilities and empower people and society through collaboration with Intelligent Systems.