Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reproducible LLM Evaluation: Quantifying Uncertainty in LLM Benchmark Scores
Paper and Code
Oct 04, 2024


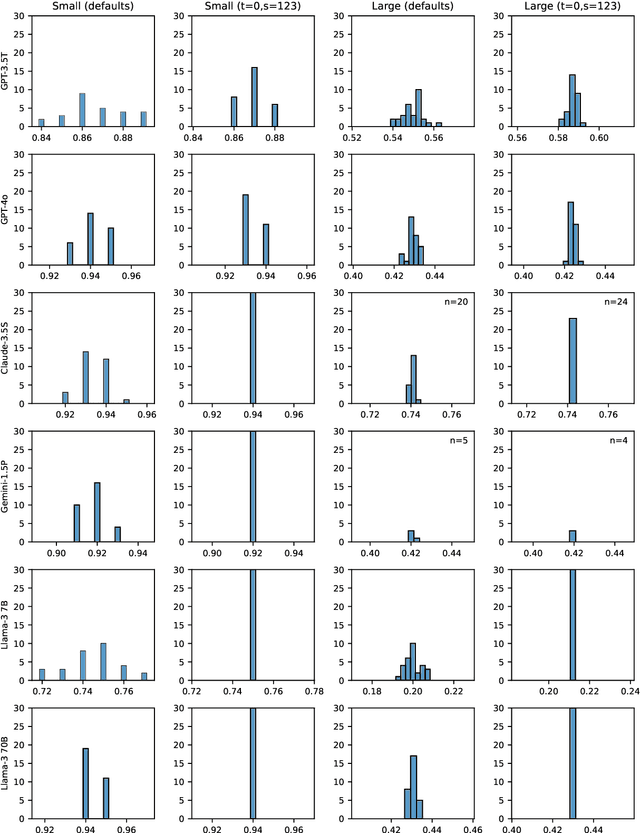
Large language models (LLMs) are stochastic, and not all models give deterministic answers, even when setting temperature to zero with a fixed random seed. However, few benchmark studies attempt to quantify uncertainty, partly due to the time and cost of repeated experiments. We use benchmarks designed for testing LLMs' capacity to reason about cardinal directions to explore the impact of experimental repeats on mean score and prediction interval. We suggest a simple method for cost-effectively quantifying the uncertainty of a benchmark score and make recommendations concerning reproducible LLM evaluation.
* 4 pages, 1 figure
View paper on