 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccommodating Missing Modalities in Time-Continuous Multimodal Emotion Recognition
Nov 16, 2023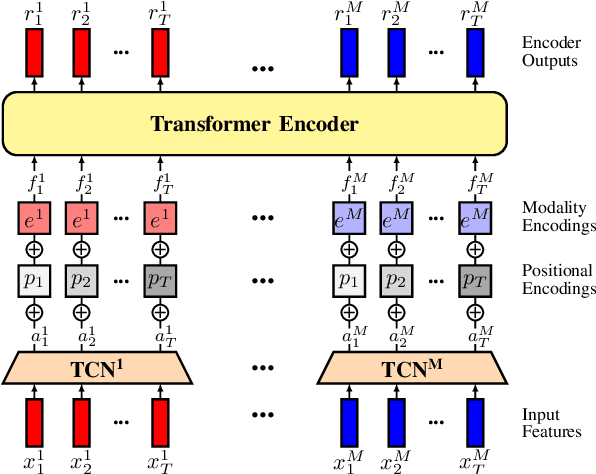
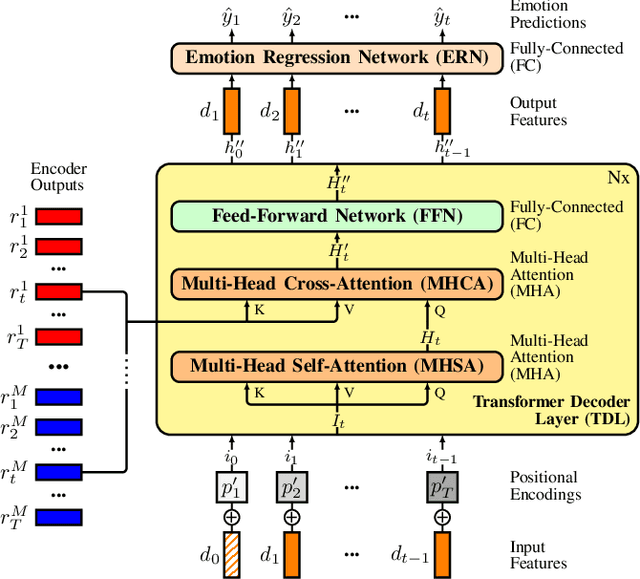
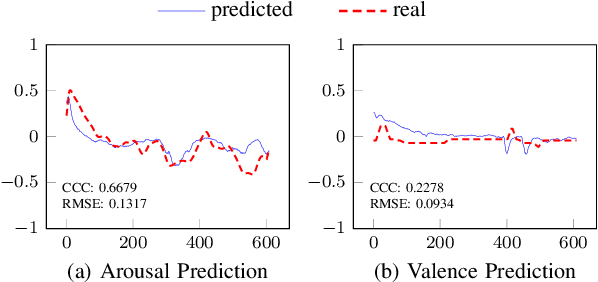

Decades of research indicate that emotion recognition is more effective when drawing information from multiple modalities. But what if some modalities are sometimes missing? To address this problem, we propose a novel Transformer-based architecture for recognizing valence and arousal in a time-continuous manner even with missing input modalities. We use a coupling of cross-attention and self-attention mechanisms to emphasize relationships between modalities during time and enhance the learning process on weak salient inputs. Experimental results on the Ulm-TSST dataset show that our model exhibits an improvement of the concordance correlation coefficient evaluation of 37% when predicting arousal values and 30% when predicting valence values, compared to a late-fusion baseline approach.
A Hierarchical Framework for Collaborative Artificial Intelligence
Dec 14, 2022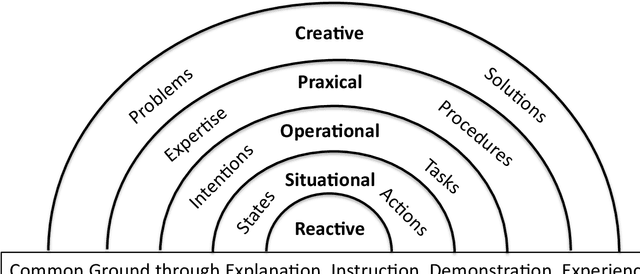
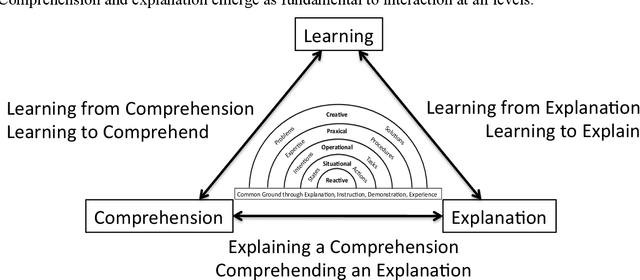
We propose a hierarchical framework for collaborative intelligent systems. This framework organizes research challenges based on the nature of the collaborative activity and the information that must be shared, with each level building on capabilities provided by lower levels. We review research paradigms at each level, with a description of classical engineering-based approaches and modern alternatives based on machine learning, illustrated with a running example using a hypothetical personal service robot. We discuss cross-cutting issues that occur at all levels, focusing on the problem of communicating and sharing comprehension, the role of explanation and the social nature of collaboration. We conclude with a summary of research challenges and a discussion of the potential for economic and societal impact provided by technologies that enhance human abilities and empower people and society through collaboration with Intelligent Systems.
Transformer-Based Self-Supervised Learning for Emotion Recognition
Apr 08, 2022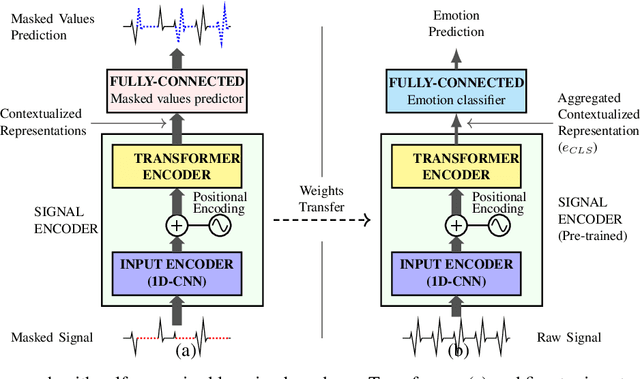
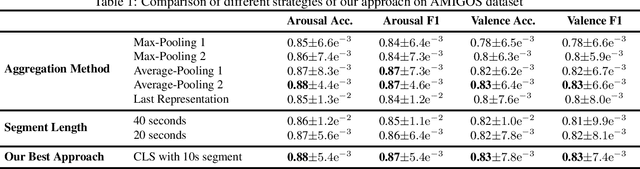
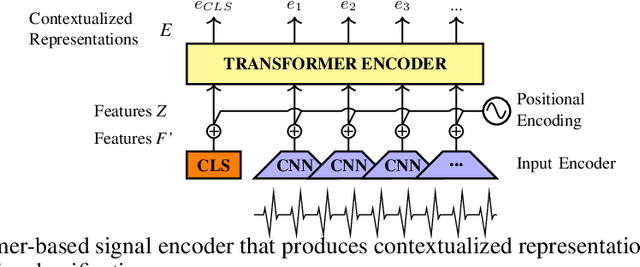

In order to exploit representations of time-series signals, such as physiological signals, it is essential that these representations capture relevant information from the whole signal. In this work, we propose to use a Transformer-based model to process electrocardiograms (ECG) for emotion recognition. Attention mechanisms of the Transformer can be used to build contextualized representations for a signal, giving more importance to relevant parts. These representations may then be processed with a fully-connected network to predict emotions. To overcome the relatively small size of datasets with emotional labels, we employ self-supervised learning. We gathered several ECG datasets with no labels of emotion to pre-train our model, which we then fine-tuned for emotion recognition on the AMIGOS dataset. We show that our approach reaches state-of-the-art performances for emotion recognition using ECG signals on AMIGOS. More generally, our experiments show that transformers and pre-training are promising strategies for emotion recognition with physiological signals.
Recognizing Manipulation Actions from State-Transformations
Jun 12, 2019
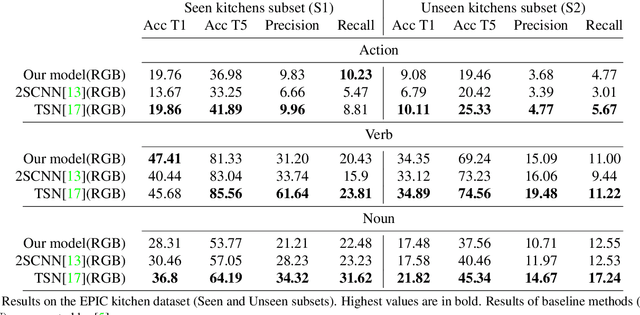
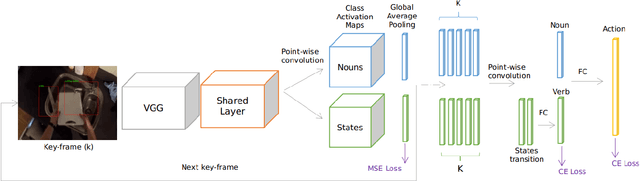
Manipulation actions transform objects from an initial state into a final state. In this paper, we report on the use of object state transitions as a mean for recognizing manipulation actions. Our method is inspired by the intuition that object states are visually more apparent than actions from a still frame and thus provide information that is complementary to spatio-temporal action recognition. We start by defining a state transition matrix that maps action labels into a pre-state and a post-state. From each keyframe, we learn appearance models of objects and their states. Manipulation actions can then be recognized from the state transition matrix. We report results on the EPIC kitchen action recognition challenge.
Multimodal Observation and Interpretation of Subjects Engaged in Problem Solving
Oct 12, 2017


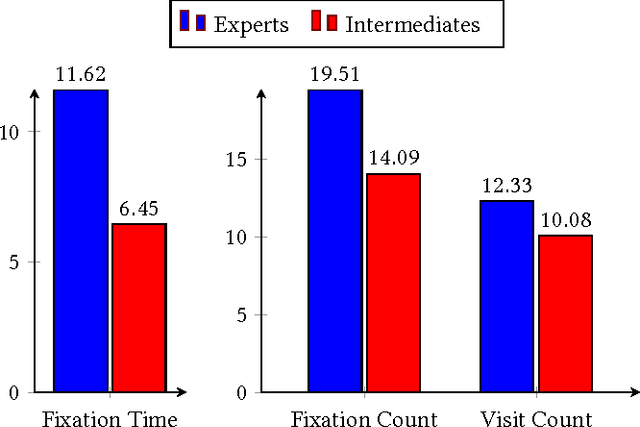
In this paper we present the first results of a pilot experiment in the capture and interpretation of multimodal signals of human experts engaged in solving challenging chess problems. Our goal is to investigate the extent to which observations of eye-gaze, posture, emotion and other physiological signals can be used to model the cognitive state of subjects, and to explore the integration of multiple sensor modalities to improve the reliability of detection of human displays of awareness and emotion. We observed chess players engaged in problems of increasing difficulty while recording their behavior. Such recordings can be used to estimate a participant's awareness of the current situation and to predict ability to respond effectively to challenging situations. Results show that a multimodal approach is more accurate than a unimodal one. By combining body posture, visual attention and emotion, the multimodal approach can reach up to 93% of accuracy when determining player's chess expertise while unimodal approach reaches 86%. Finally this experiment validates the use of our equipment as a general and reproducible tool for the study of participants engaged in screen-based interaction and/or problem solving.