 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuRAL: A Multi-Resident Ambient Sensor Dataset Annotated with Natural Language for Activities of Daily Living
Apr 29, 2025

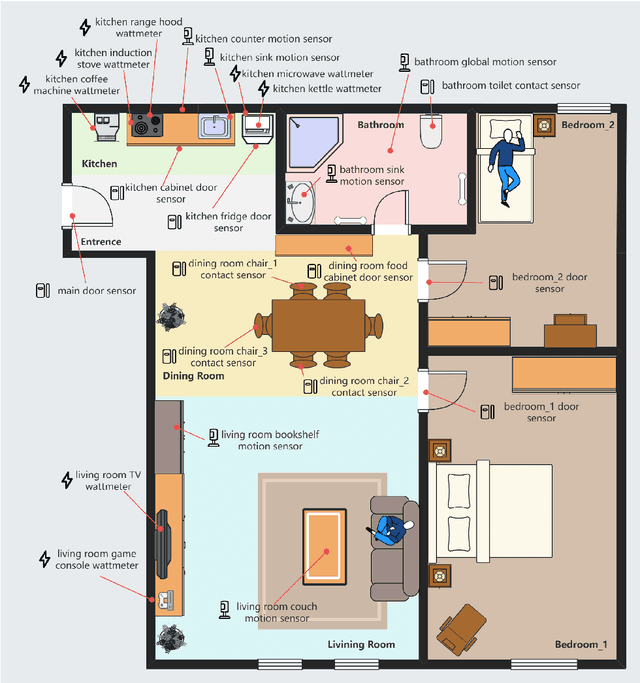
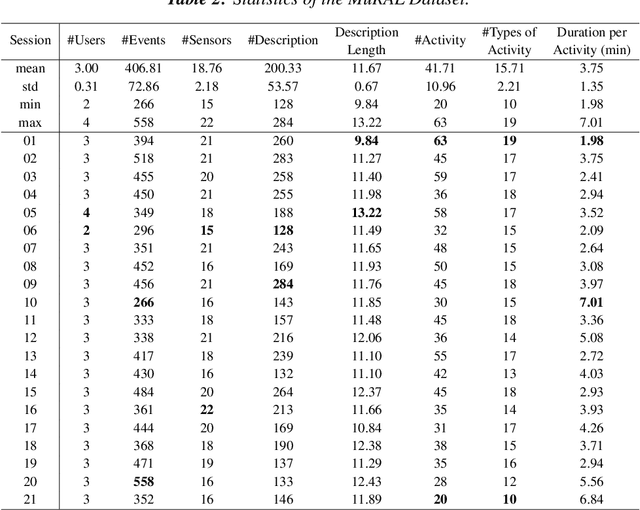
Recent advances in Large Language Models (LLMs) have shown promising potential for human activity recognition (HAR) using ambient sensors, especially through natural language reasoning and zero-shot learning. However, existing datasets such as CASAS, ARAS, and MARBLE were not originally designed with LLMs in mind and therefore lack the contextual richness, complexity, and annotation granularity required to fully exploit LLM capabilities. In this paper, we introduce MuRAL, the first Multi-Resident Ambient sensor dataset with natural Language, comprising over 21 hours of multi-user sensor data collected from 21 sessions in a smart-home environment. MuRAL is annotated with fine-grained natural language descriptions, resident identities, and high-level activity labels, all situated in dynamic, realistic multi-resident settings. We benchmark MuRAL using state-of-the-art LLMs for three core tasks: subject assignment, action description, and activity classification. Our results demonstrate that while LLMs can provide rich semantic interpretations of ambient data, current models still face challenges in handling multi-user ambiguity and under-specified sensor contexts. We release MuRAL to support future research on LLM-powered, explainable, and socially aware activity understanding in smart environments. For access to the dataset, please reach out to us via the provided contact information. A direct link for dataset retrieval will be made available at this location in due course.
Exploring VQ-VAE with Prosody Parameters for Speaker Anonymization
Sep 24, 2024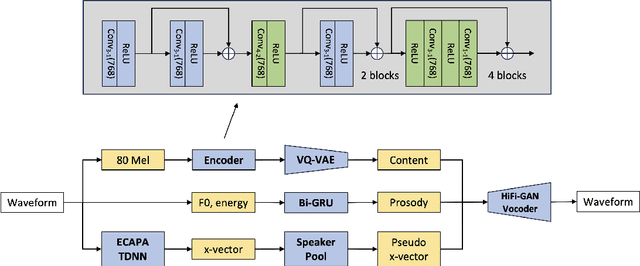

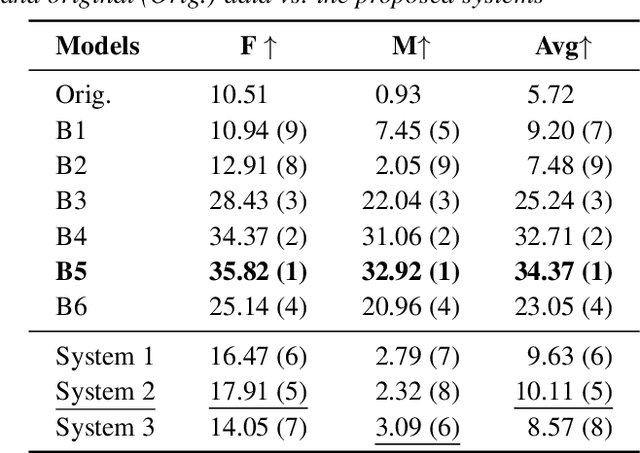
Human speech conveys prosody, linguistic content, and speaker identity. This article investigates a novel speaker anonymization approach using an end-to-end network based on a Vector-Quantized Variational Auto-Encoder (VQ-VAE) to deal with these speech components. This approach is designed to disentangle these components to specifically target and modify the speaker identity while preserving the linguistic and emotionalcontent. To do so, three separate branches compute embeddings for content, prosody, and speaker identity respectively. During synthesis, taking these embeddings, the decoder of the proposed architecture is conditioned on both speaker and prosody information, allowing for capturing more nuanced emotional states and precise adjustments to speaker identification. Findings indicate that this method outperforms most baseline techniques in preserving emotional information. However, it exhibits more limited performance on other voice privacy tasks, emphasizing the need for further improvements.
Generative Resident Separation and Multi-label Classification for Multi-person Activity Recognition
Apr 10, 2024This paper presents two models to address the problem of multi-person activity recognition using ambient sensors in a home. The first model, Seq2Res, uses a sequence generation approach to separate sensor events from different residents. The second model, BiGRU+Q2L, uses a Query2Label multi-label classifier to predict multiple activities simultaneously. Performances of these models are compared to a state-of-the-art model in different experimental scenarios, using a state-of-the-art dataset of two residents in a home instrumented with ambient sensors. These results lead to a discussion on the advantages and drawbacks of resident separation and multi-label classification for multi-person activity recognition.
Multimodal Group Emotion Recognition In-the-wild Using Privacy-Compliant Features
Dec 06, 2023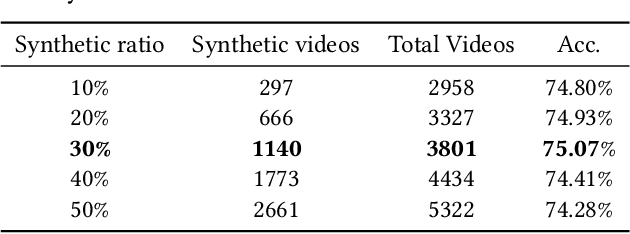
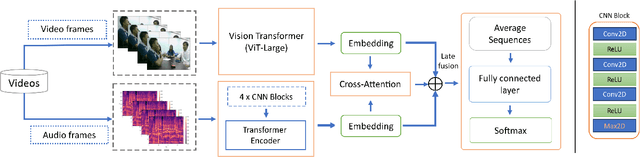
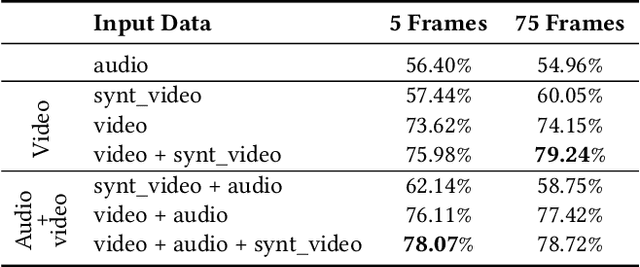

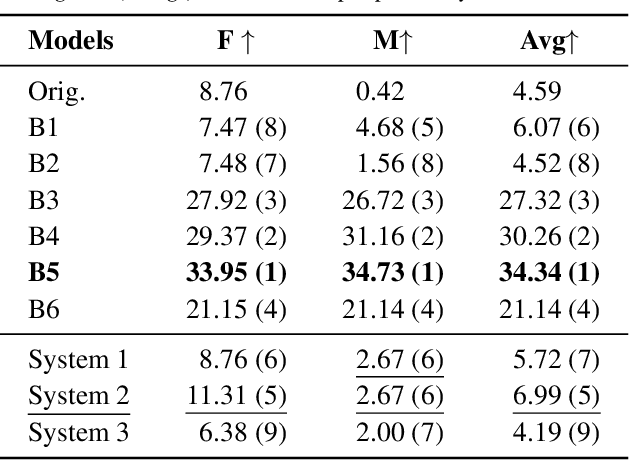
This paper explores privacy-compliant group-level emotion recognition ''in-the-wild'' within the EmotiW Challenge 2023. Group-level emotion recognition can be useful in many fields including social robotics, conversational agents, e-coaching and learning analytics. This research imposes itself using only global features avoiding individual ones, i.e. all features that can be used to identify or track people in videos (facial landmarks, body poses, audio diarization, etc.). The proposed multimodal model is composed of a video and an audio branches with a cross-attention between modalities. The video branch is based on a fine-tuned ViT architecture. The audio branch extracts Mel-spectrograms and feed them through CNN blocks into a transformer encoder. Our training paradigm includes a generated synthetic dataset to increase the sensitivity of our model on facial expression within the image in a data-driven way. The extensive experiments show the significance of our methodology. Our privacy-compliant proposal performs fairly on the EmotiW challenge, with 79.24% and 75.13% of accuracy respectively on validation and test set for the best models. Noticeably, our findings highlight that it is possible to reach this accuracy level with privacy-compliant features using only 5 frames uniformly distributed on the video.
A Comprehensive Multi-scale Approach for Speech and Dynamics Synchrony in Talking Head Generation
Jul 04, 2023



Animating still face images with deep generative models using a speech input signal is an active research topic and has seen important recent progress. However, much of the effort has been put into lip syncing and rendering quality while the generation of natural head motion, let alone the audio-visual correlation between head motion and speech, has often been neglected. In this work, we propose a multi-scale audio-visual synchrony loss and a multi-scale autoregressive GAN to better handle short and long-term correlation between speech and the dynamics of the head and lips. In particular, we train a stack of syncer models on multimodal input pyramids and use these models as guidance in a multi-scale generator network to produce audio-aligned motion unfolding over diverse time scales. Our generator operates in the facial landmark domain, which is a standard low-dimensional head representation. The experiments show significant improvements over the state of the art in head motion dynamics quality and in multi-scale audio-visual synchrony both in the landmark domain and in the image domain.
Preliminary Study on SSCF-derived Polar Coordinate for ASR
Nov 30, 2022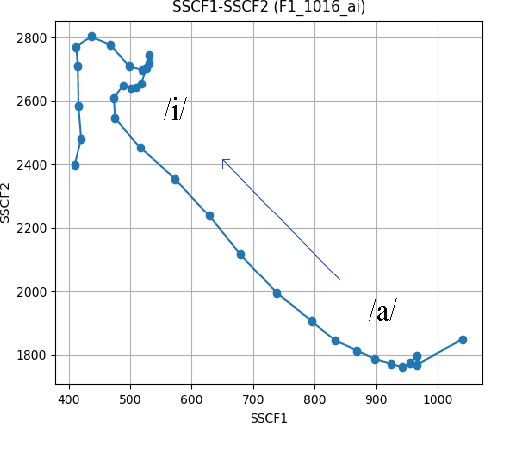

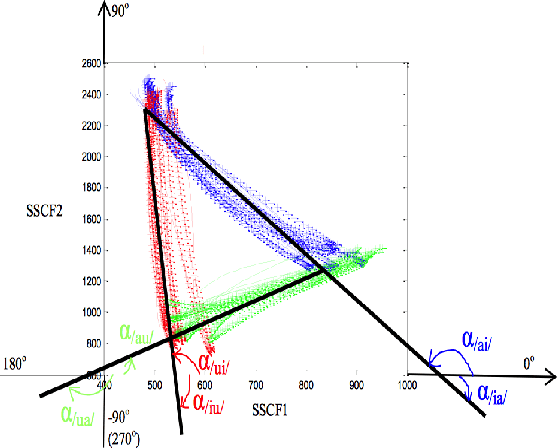

The transition angles are defined to describe the vowel-to-vowel transitions in the acoustic space of the Spectral Subband Centroids, and the findings show that they are similar among speakers and speaking rates. In this paper, we propose to investigate the usage of polar coordinates in favor of angles to describe a speech signal by characterizing its acoustic trajectory and using them in Automatic Speech Recognition. According to the experimental results evaluated on the BRAF100 dataset, the polar coordinates achieved significantly higher accuracy than the angles in the mixed and cross-gender speech recognitions, demonstrating that these representations are superior at defining the acoustic trajectory of the speech signal. Furthermore, the accuracy was significantly improved when they were utilized with their first and second-order derivatives ($\Delta$, $\Delta$$\Delta$), especially in cross-female recognition. However, the results showed they were not much more gender-independent than the conventional Mel-frequency Cepstral Coefficients (MFCCs).
Autoregressive GAN for Semantic Unconditional Head Motion Generation
Nov 02, 2022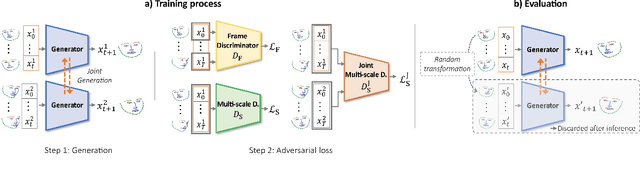



We address the task of unconditional head motion generation to animate still human faces in a low-dimensional semantic space.Deviating from talking head generation conditioned on audio that seldom puts emphasis on realistic head motions, we devise a GAN-based architecture that allows obtaining rich head motion sequences while avoiding known caveats associated with GANs.Namely, the autoregressive generation of incremental outputs ensures smooth trajectories, while a multi-scale discriminator on input pairs drives generation toward better handling of high and low frequency signals and less mode collapse.We demonstrate experimentally the relevance of the proposed architecture and compare with models that showed state-of-the-art performances on similar tasks.
Self-Supervised Transformers for Unsupervised Object Discovery using Normalized Cut
Mar 24, 2022

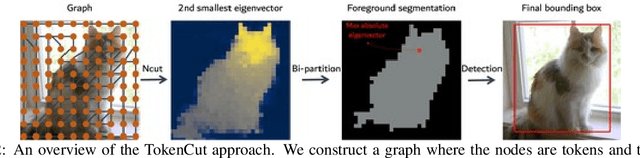
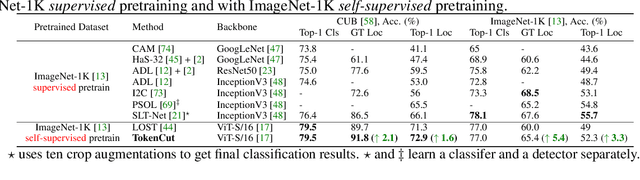
Transformers trained with self-supervised learning using self-distillation loss (DINO) have been shown to produce attention maps that highlight salient foreground objects. In this paper, we demonstrate a graph-based approach that uses the self-supervised transformer features to discover an object from an image. Visual tokens are viewed as nodes in a weighted graph with edges representing a connectivity score based on the similarity of tokens. Foreground objects can then be segmented using a normalized graph-cut to group self-similar regions. We solve the graph-cut problem using spectral clustering with generalized eigen-decomposition and show that the second smallest eigenvector provides a cutting solution since its absolute value indicates the likelihood that a token belongs to a foreground object. Despite its simplicity, this approach significantly boosts the performance of unsupervised object discovery: we improve over the recent state of the art LOST by a margin of 6.9%, 8.1%, and 8.1% respectively on the VOC07, VOC12, and COCO20K. The performance can be further improved by adding a second stage class-agnostic detector (CAD). Our proposed method can be easily extended to unsupervised saliency detection and weakly supervised object detection. For unsupervised saliency detection, we improve IoU for 4.9%, 5.2%, 12.9% on ECSSD, DUTS, DUT-OMRON respectively compared to previous state of the art. For weakly supervised object detection, we achieve competitive performance on CUB and ImageNet.
Navigation In Urban Environments Amongst Pedestrians Using Multi-Objective Deep Reinforcement Learning
Oct 11, 2021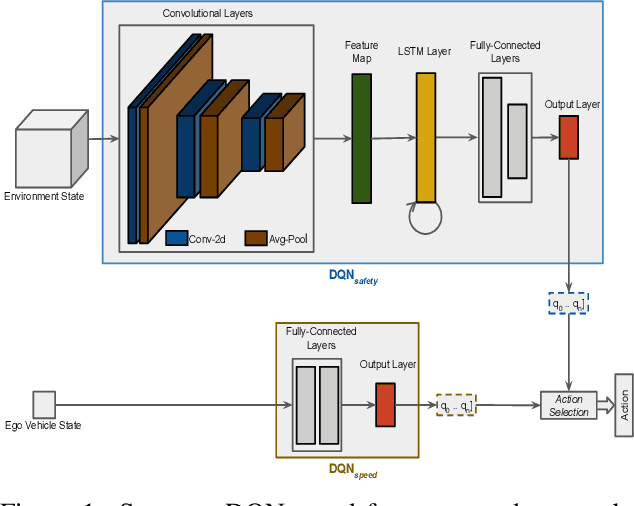
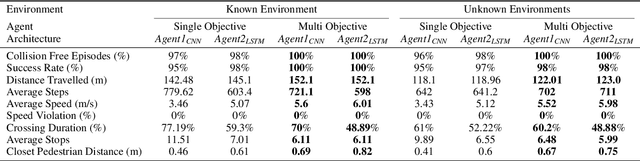
Urban autonomous driving in the presence of pedestrians as vulnerable road users is still a challenging and less examined research problem. This work formulates navigation in urban environments as a multi objective reinforcement learning problem. A deep learning variant of thresholded lexicographic Q-learning is presented for autonomous navigation amongst pedestrians. The multi objective DQN agent is trained on a custom urban environment developed in CARLA simulator. The proposed method is evaluated by comparing it with a single objective DQN variant on known and unknown environments. Evaluation results show that the proposed method outperforms the single objective DQN variant with respect to all aspects.
SocialInteractionGAN: Multi-person Interaction Sequence Generation
Mar 10, 2021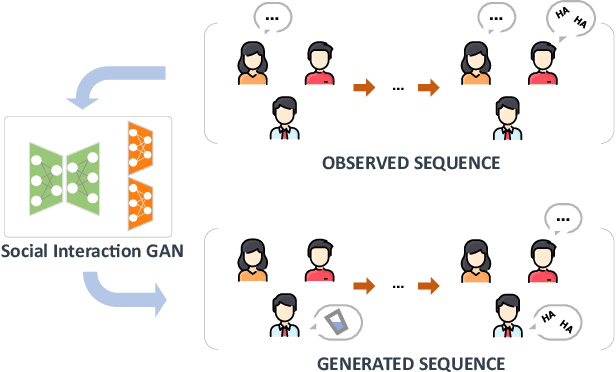
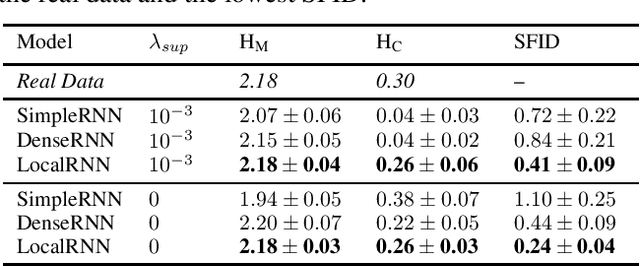
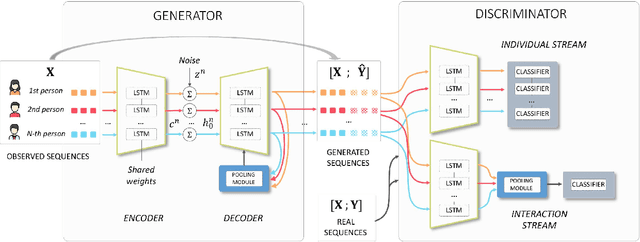
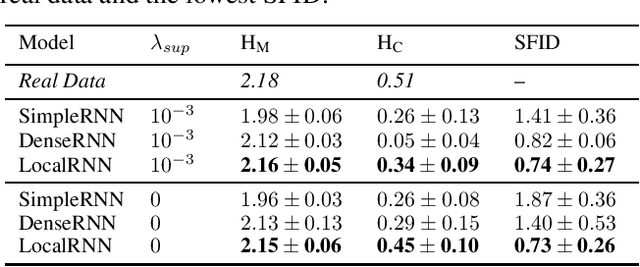
Prediction of human actions in social interactions has important applications in the design of social robots or artificial avatars. In this paper, we model human interaction generation as a discrete multi-sequence generation problem and present SocialInteractionGAN, a novel adversarial architecture for conditional interaction generation. Our model builds on a recurrent encoder-decoder generator network and a dual-stream discriminator. This architecture allows the discriminator to jointly assess the realism of interactions and that of individual action sequences. Within each stream a recurrent network operating on short subsequences endows the output signal with local assessments, better guiding the forthcoming generation. Crucially, contextual information on interacting participants is shared among agents and reinjected in both the generation and the discriminator evaluation processes. We show that the proposed SocialInteractionGAN succeeds in producing high realism action sequences of interacting people, comparing favorably to a diversity of recurrent and convolutional discriminator baselines. Evaluations are conducted using modified Inception Score and Fr{\'e}chet Inception Distance metrics, that we specifically design for discrete sequential generated data. The distribution of generated sequences is shown to approach closely that of real data. In particular our model properly learns the dynamics of interaction sequences, while exploiting the full range of actions.