 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Transformers for Unsupervised Object Discovery using Normalized Cut
Mar 24, 2022

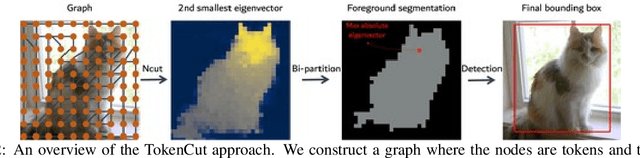
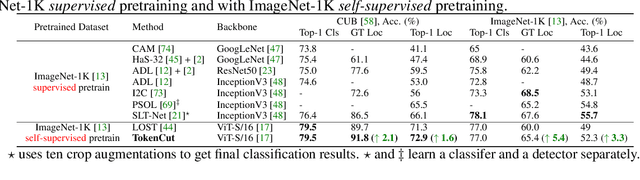
Transformers trained with self-supervised learning using self-distillation loss (DINO) have been shown to produce attention maps that highlight salient foreground objects. In this paper, we demonstrate a graph-based approach that uses the self-supervised transformer features to discover an object from an image. Visual tokens are viewed as nodes in a weighted graph with edges representing a connectivity score based on the similarity of tokens. Foreground objects can then be segmented using a normalized graph-cut to group self-similar regions. We solve the graph-cut problem using spectral clustering with generalized eigen-decomposition and show that the second smallest eigenvector provides a cutting solution since its absolute value indicates the likelihood that a token belongs to a foreground object. Despite its simplicity, this approach significantly boosts the performance of unsupervised object discovery: we improve over the recent state of the art LOST by a margin of 6.9%, 8.1%, and 8.1% respectively on the VOC07, VOC12, and COCO20K. The performance can be further improved by adding a second stage class-agnostic detector (CAD). Our proposed method can be easily extended to unsupervised saliency detection and weakly supervised object detection. For unsupervised saliency detection, we improve IoU for 4.9%, 5.2%, 12.9% on ECSSD, DUTS, DUT-OMRON respectively compared to previous state of the art. For weakly supervised object detection, we achieve competitive performance on CUB and ImageNet.
Multi-View Fuzzy Clustering with Minimax Optimization for Effective Clustering of Data from Multiple Sources
Aug 25, 2016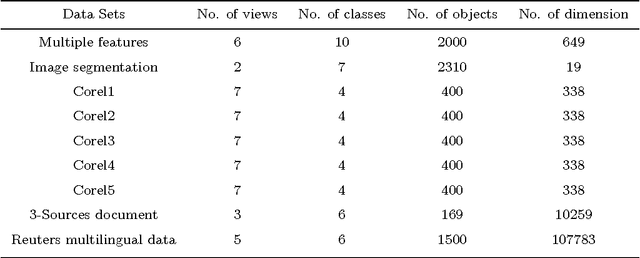

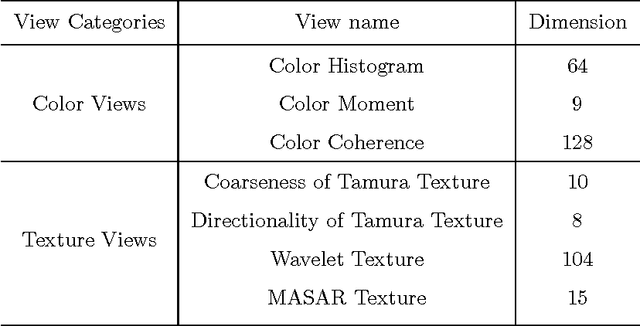
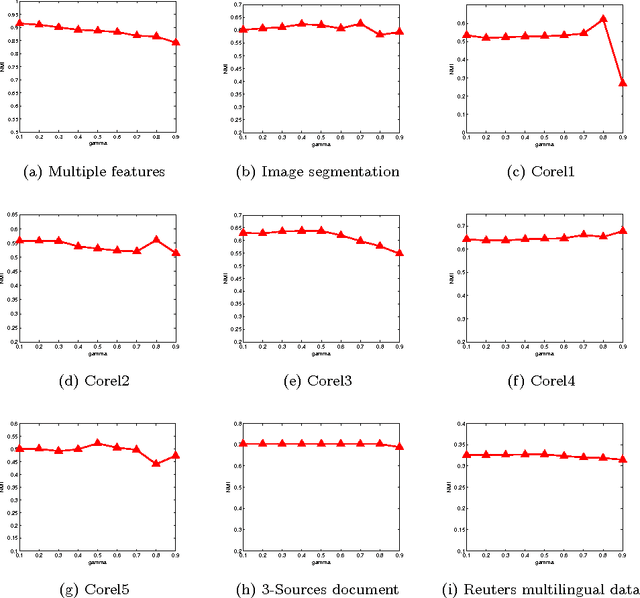
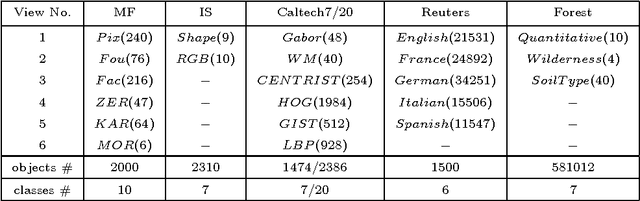
Multi-view data clustering refers to categorizing a data set by making good use of related information from multiple representations of the data. It becomes important nowadays because more and more data can be collected in a variety of ways, in different settings and from different sources, so each data set can be represented by different sets of features to form different views of it. Many approaches have been proposed to improve clustering performance by exploring and integrating heterogeneous information underlying different views. In this paper, we propose a new multi-view fuzzy clustering approach called MinimaxFCM by using minimax optimization based on well-known Fuzzy c means. In MinimaxFCM the consensus clustering results are generated based on minimax optimization in which the maximum disagreements of different weighted views are minimized. Moreover, the weight of each view can be learned automatically in the clustering process. In addition, there is only one parameter to be set besides the fuzzifier. The detailed problem formulation, updating rules derivation, and the in-depth analysis of the proposed MinimaxFCM are provided here. Experimental studies on nine multi-view data sets including real world image and document data sets have been conducted. We observed that MinimaxFCM outperforms related multi-view clustering approaches in terms of clustering accuracy, demonstrating the great potential of MinimaxFCM for multi-view data analysis.
Incremental Minimax Optimization based Fuzzy Clustering for Large Multi-view Data
Aug 25, 2016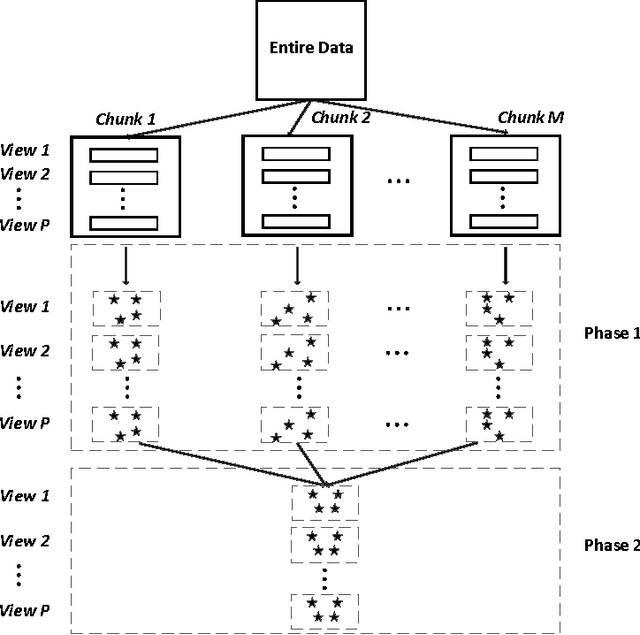
Incremental clustering approaches have been proposed for handling large data when given data set is too large to be stored. The key idea of these approaches is to find representatives to represent each cluster in each data chunk and final data analysis is carried out based on those identified representatives from all the chunks. However, most of the incremental approaches are used for single view data. As large multi-view data generated from multiple sources becomes prevalent nowadays, there is a need for incremental clustering approaches to handle both large and multi-view data. In this paper we propose a new incremental clustering approach called incremental minimax optimization based fuzzy clustering (IminimaxFCM) to handle large multi-view data. In IminimaxFCM, representatives with multiple views are identified to represent each cluster by integrating multiple complementary views using minimax optimization. The detailed problem formulation, updating rules derivation, and the in-depth analysis of the proposed IminimaxFCM are provided. Experimental studies on several real world multi-view data sets have been conducted. We observed that IminimaxFCM outperforms related incremental fuzzy clustering in terms of clustering accuracy, demonstrating the great potential of IminimaxFCM for large multi-view data analysis.