 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Transformers for Unsupervised Object Discovery using Normalized Cut
Mar 24, 2022

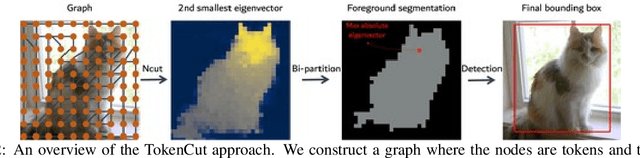
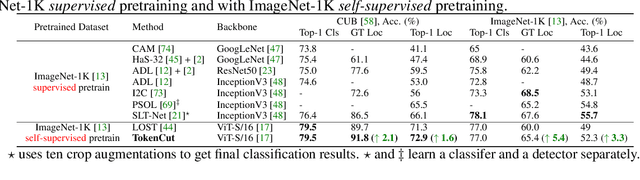
Transformers trained with self-supervised learning using self-distillation loss (DINO) have been shown to produce attention maps that highlight salient foreground objects. In this paper, we demonstrate a graph-based approach that uses the self-supervised transformer features to discover an object from an image. Visual tokens are viewed as nodes in a weighted graph with edges representing a connectivity score based on the similarity of tokens. Foreground objects can then be segmented using a normalized graph-cut to group self-similar regions. We solve the graph-cut problem using spectral clustering with generalized eigen-decomposition and show that the second smallest eigenvector provides a cutting solution since its absolute value indicates the likelihood that a token belongs to a foreground object. Despite its simplicity, this approach significantly boosts the performance of unsupervised object discovery: we improve over the recent state of the art LOST by a margin of 6.9%, 8.1%, and 8.1% respectively on the VOC07, VOC12, and COCO20K. The performance can be further improved by adding a second stage class-agnostic detector (CAD). Our proposed method can be easily extended to unsupervised saliency detection and weakly supervised object detection. For unsupervised saliency detection, we improve IoU for 4.9%, 5.2%, 12.9% on ECSSD, DUTS, DUT-OMRON respectively compared to previous state of the art. For weakly supervised object detection, we achieve competitive performance on CUB and ImageNet.
Composing Complex and Hybrid AI Solutions
Feb 25, 2022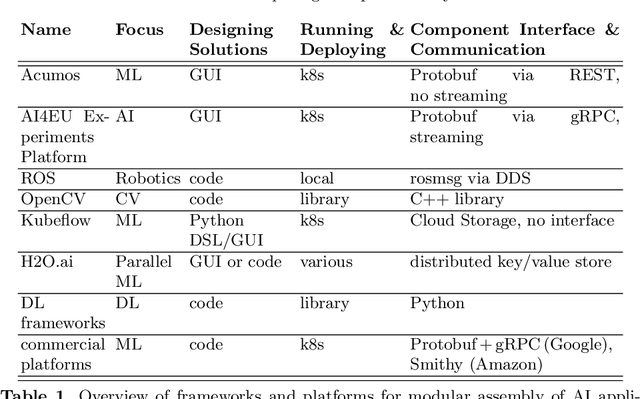
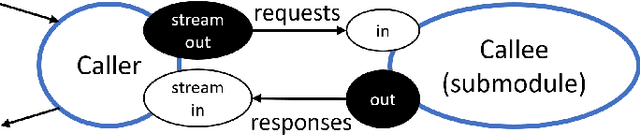

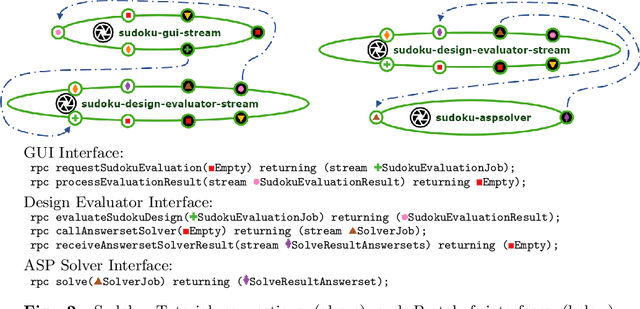
Progress in several areas of computer science has been enabled by comfortable and efficient means of experimentation, clear interfaces, and interchangable components, for example using OpenCV for computer vision or ROS for robotics. We describe an extension of the Acumos system towards enabling the above features for general AI applications. Originally, Acumos was created for telecommunication purposes, mainly for creating linear pipelines of machine learning components. Our extensions include support for more generic components with gRPC/Protobuf interfaces, automatic orchestration of graphically assembled solutions including control loops, sub-component topologies, and event-based communication,and provisions for assembling solutions which contain user interfaces and shared storage areas. We provide examples of deployable solutions and their interfaces. The framework is deployed at http://aiexp.ai4europe.eu/ and its source code is managed as an open source Eclipse project.
Deep learning investigation for chess player attention prediction using eye-tracking and game data
Apr 17, 2019

This article reports on an investigation of the use of convolutional neural networks to predict the visual attention of chess players. The visual attention model described in this article has been created to generate saliency maps that capture hierarchical and spatial features of chessboard, in order to predict the probability fixation for individual pixels Using a skip-layer architecture of an autoencoder, with a unified decoder, we are able to use multiscale features to predict saliency of part of the board at different scales, showing multiple relations between pieces. We have used scan path and fixation data from players engaged in solving chess problems, to compute 6600 saliency maps associated to the corresponding chess piece configurations. This corpus is completed with synthetically generated data from actual games gathered from an online chess platform. Experiments realized using both scan-paths from chess players and the CAT2000 saliency dataset of natural images, highlights several results. Deep features, pretrained on natural images, were found to be helpful in training visual attention prediction for chess. The proposed neural network architecture is able to generate meaningful saliency maps on unseen chess configurations with good scores on standard metrics. This work provides a baseline for future work on visual attention prediction in similar contexts.
Rendu basé image avec contraintes sur les gradients
Dec 29, 2018



Multi-view image-based rendering consists in generating a novel view of a scene from a set of source views. In general, this works by first doing a coarse 3D reconstruction of the scene, and then using this reconstruction to establish correspondences between source and target views, followed by blending the warped views to get the final image. Unfortunately, discontinuities in the blending weights, due to scene geometry or camera placement, result in artifacts in the target view. In this paper, we show how to avoid these artifacts by imposing additional constraints on the image gradients of the novel view. We propose a variational framework in which an energy functional is derived and optimized by iteratively solving a linear system. We demonstrate this method on several structured and unstructured multi-view datasets, and show that it numerically outperforms state-of-the-art methods, and eliminates artifacts that result from visibility discontinuities
The Role of Emotion in Problem Solving: First Results from Observing Chess
Oct 17, 2018
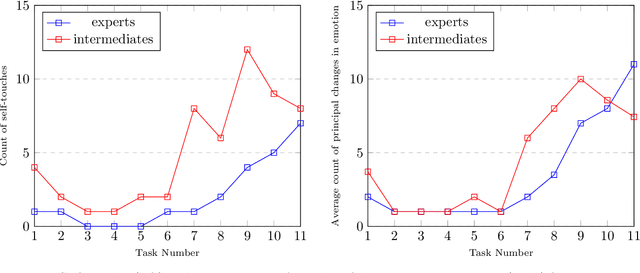
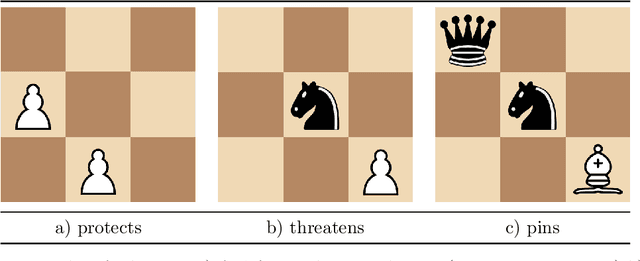
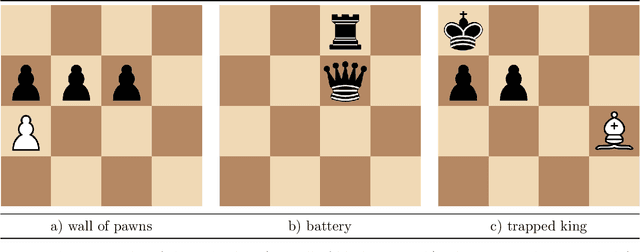
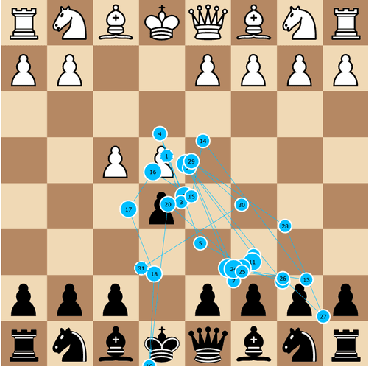
In this paper we present results from recent experiments that suggest that chess players associate emotions to game situations and reactively use these associations to guide search for planning and problem solving. We describe the design of an instrument for capturing and interpreting multimodal signals of humans engaged in solving challenging problems. We review results from a pilot experiment with human experts engaged in solving challenging problems in Chess that revealed an unexpected observation of rapid changes in emotion as players attempt to solve challenging problems. We propose a cognitive model that describes the process by which subjects select chess chunks for use in interpretation of the game situation and describe initial results from a second experiment designed to test this model.
Symmetry Aware Evaluation of 3D Object Detection and Pose Estimation in Scenes of Many Parts in Bulk
Jun 21, 2018



While 3D object detection and pose estimation has been studied for a long time, its evaluation is not yet completely satisfactory. Indeed, existing datasets typically consist in numerous acquisitions of only a few scenes because of the tediousness of pose annotation, and existing evaluation protocols cannot handle properly objects with symmetries. This work aims at addressing those two points. We first present automatic techniques to produce fully annotated RGBD data of many object instances in arbitrary poses, with which we produce a dataset of thousands of independent scenes of bulk parts composed of both real and synthetic images. We then propose a consistent evaluation methodology suitable for any rigid object, regardless of its symmetries. We illustrate it with two reference object detection and pose estimation methods on different objects, and show that incorporating symmetry considerations into pose estimation methods themselves can lead to significant performance gains. The proposed dataset is available at http://rbregier.github.io/dataset2017.
Histogram of Oriented Depth Gradients for Action Recognition
Jan 29, 2018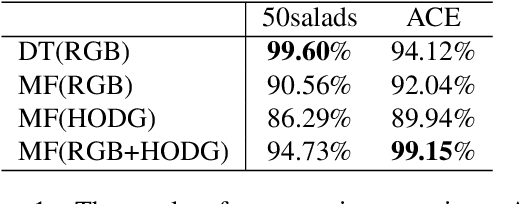
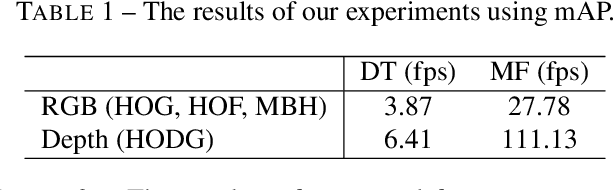
In this paper, we report on experiments with the use of local measures for depth motion for visual action recognition from MPEG encoded RGBD video sequences. We show that such measures can be combined with local space-time video descriptors for appearance to provide a computationally efficient method for recognition of actions. Fisher vectors are used for encoding and concatenating a depth descriptor with existing RGB local descriptors. We then employ a linear SVM for recognizing manipulation actions using such vectors. We evaluate the effectiveness of such measures by comparison to the state-of-the-art using two recent datasets for action recognition in kitchen environments.
Defining the Pose of any 3D Rigid Object and an Associated Distance
Nov 29, 2017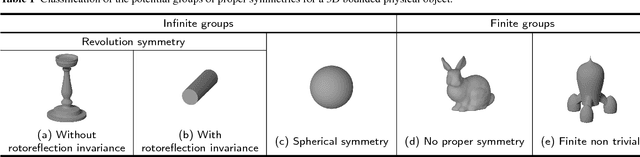
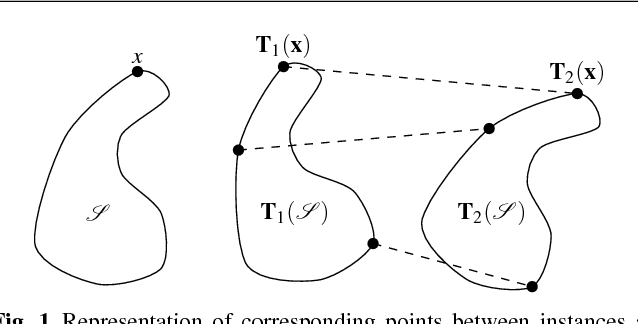

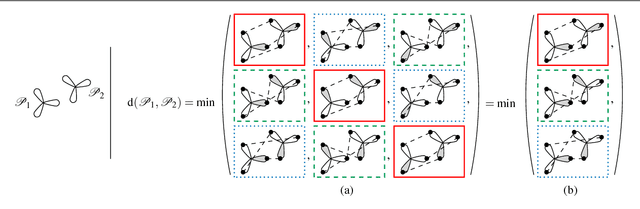
The pose of a rigid object is usually regarded as a rigid transformation, described by a translation and a rotation. However, equating the pose space with the space of rigid transformations is in general abusive, as it does not account for objects with proper symmetries -- which are common among man-made objects.In this article, we define pose as a distinguishable static state of an object, and equate a pose with a set of rigid transformations. Based solely on geometric considerations, we propose a frame-invariant metric on the space of possible poses, valid for any physical rigid object, and requiring no arbitrary tuning. This distance can be evaluated efficiently using a representation of poses within an Euclidean space of at most 12 dimensions depending on the object's symmetries. This makes it possible to efficiently perform neighborhood queries such as radius searches or k-nearest neighbor searches within a large set of poses using off-the-shelf methods. Pose averaging considering this metric can similarly be performed easily, using a projection function from the Euclidean space onto the pose space. The practical value of those theoretical developments is illustrated with an application of pose estimation of instances of a 3D rigid object given an input depth map, via a Mean Shift procedure.