 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing Complex and Hybrid AI Solutions
Feb 25, 2022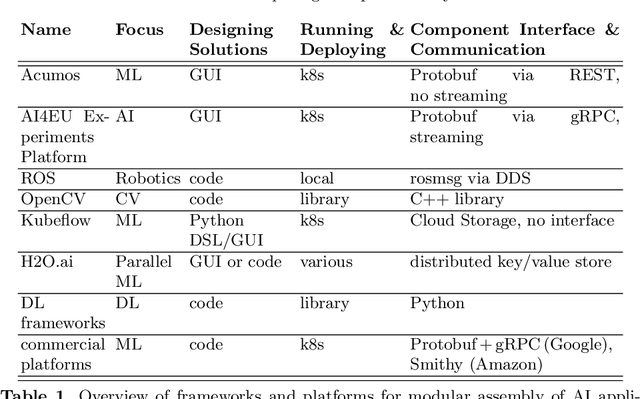
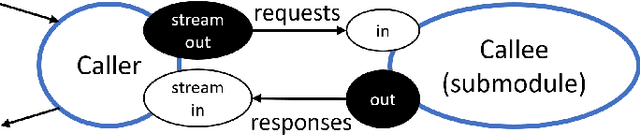

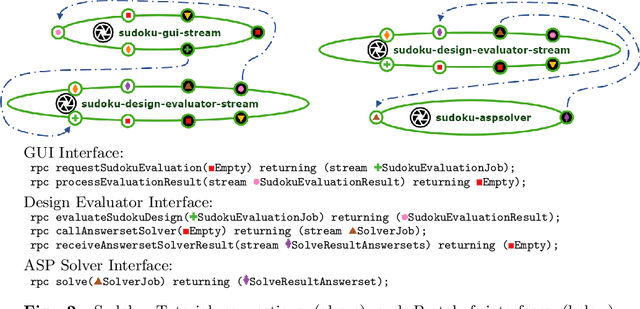
Progress in several areas of computer science has been enabled by comfortable and efficient means of experimentation, clear interfaces, and interchangable components, for example using OpenCV for computer vision or ROS for robotics. We describe an extension of the Acumos system towards enabling the above features for general AI applications. Originally, Acumos was created for telecommunication purposes, mainly for creating linear pipelines of machine learning components. Our extensions include support for more generic components with gRPC/Protobuf interfaces, automatic orchestration of graphically assembled solutions including control loops, sub-component topologies, and event-based communication,and provisions for assembling solutions which contain user interfaces and shared storage areas. We provide examples of deployable solutions and their interfaces. The framework is deployed at http://aiexp.ai4europe.eu/ and its source code is managed as an open source Eclipse project.
Exploiting Partial Knowledge in Declarative Domain-Specific Heuristics for ASP
Sep 18, 2019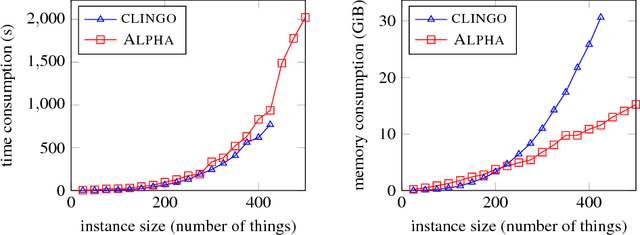
Domain-specific heuristics are an important technique for solving combinatorial problems efficiently. We propose a novel semantics for declarative specifications of domain-specific heuristics in Answer Set Programming (ASP). Decision procedures that are based on a partial solution are a frequent ingredient of existing domain-specific heuristics, e.g., for placing an item that has not been placed yet in bin packing. Therefore, in our novel semantics negation as failure and aggregates in heuristic conditions are evaluated on a partial solver state. State-of-the-art solvers do not allow such a declarative specification. Our implementation in the lazy-grounding ASP system Alpha supports heuristic directives under this semantics. By that, we also provide the first implementation for incorporating declaratively specified domain-specific heuristics in a lazy-grounding setting. Experiments confirm that the combination of ASP solving with lazy grounding and our novel heuristics can be a vital ingredient for solving industrial-size problems.
* In Proceedings ICLP 2019, arXiv:1909.07646
Abstraction for Zooming-In to Unsolvability Reasons of Grid-Cell Problems
Sep 11, 2019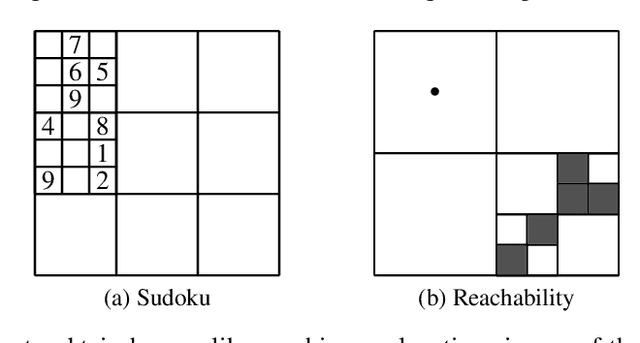

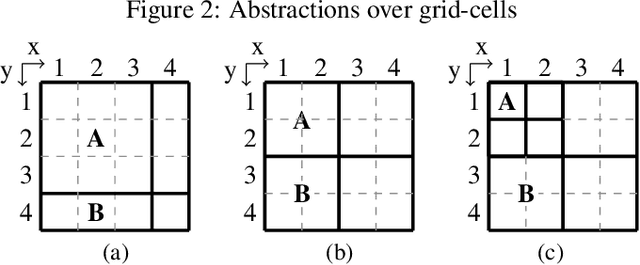
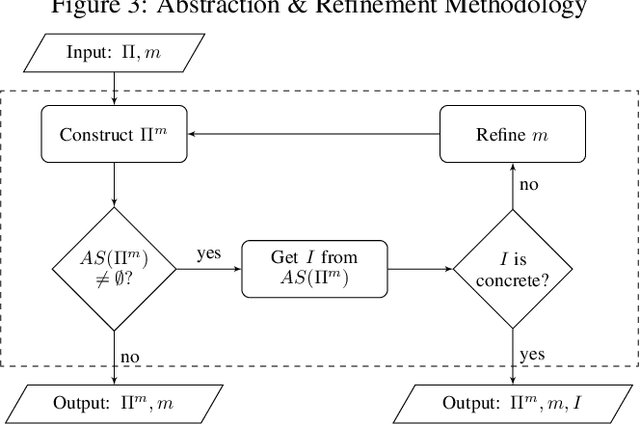
Humans are capable of abstracting away irrelevant details when studying problems. This is especially noticeable for problems over grid-cells, as humans are able to disregard certain parts of the grid and focus on the key elements important for the problem. Recently, the notion of abstraction has been introduced for Answer Set Programming (ASP), a knowledge representation and reasoning paradigm widely used in problem solving, with the potential to understand the key elements of a program that play a role in finding a solution. The present paper takes this further and empowers abstraction to deal with structural aspects, and in particular with hierarchical abstraction over the domain. We focus on obtaining the reasons for unsolvability of problems on grids, and show the possibility to automatically achieve human-like abstractions that distinguish only the relevant part of the grid. A user study on abstract explanations confirms the similarity of the focus points in machine vs. human explanations and reaffirms the challenge of employing abstraction to obtain machine explanations.
Partial Compilation of ASP Programs
Jul 24, 2019
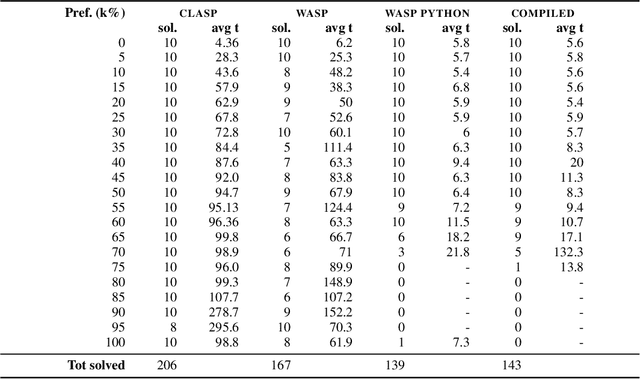
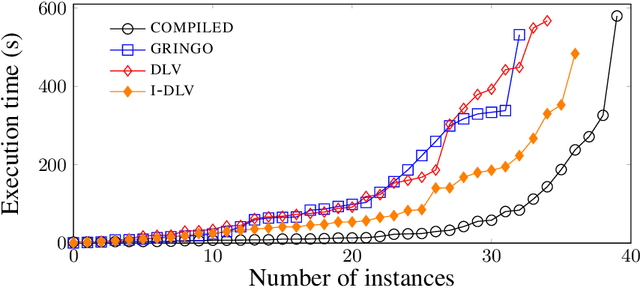

Answer Set Programming (ASP) is a well-known declarative formalism in logic programming. Efficient implementations made it possible to apply ASP in many scenarios, ranging from deductive databases applications to the solution of hard combinatorial problems. State-of-the-art ASP systems are based on the traditional ground\&solve approach and are general-purpose implementations, i.e., they are essentially built once for any kind of input program. In this paper, we propose an extended architecture for ASP systems, in which parts of the input program are compiled into an ad-hoc evaluation algorithm (i.e., we obtain a specific binary for a given program), and might not be subject to the grounding step. To this end, we identify a condition that allows the compilation of a sub-program, and present the related partial compilation technique. Importantly, we have implemented the new approach on top of a well-known ASP solver and conducted an experimental analysis on publicly-available benchmarks. Results show that our compilation-based approach improves on the state of the art in various scenarios, including cases in which the input program is stratified or the grounding blow-up makes the evaluation unpractical with traditional ASP systems.
Marmara Turkish Coreference Corpus and Coreference Resolution Baseline
Jul 31, 2018


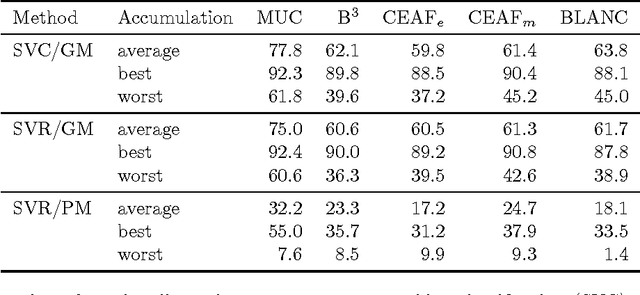
We describe the Marmara Turkish Coreference Corpus, which is an annotation of the whole METU-Sabanci Turkish Treebank with mentions and coreference chains. Collecting eight or more independent annotations for each document allowed for fully automatic adjudication. We provide a baseline system for Turkish mention detection and coreference resolution and evaluate it on the corpus.
Best-Effort Inductive Logic Programming via Fine-grained Cost-based Hypothesis Generation
Feb 23, 2018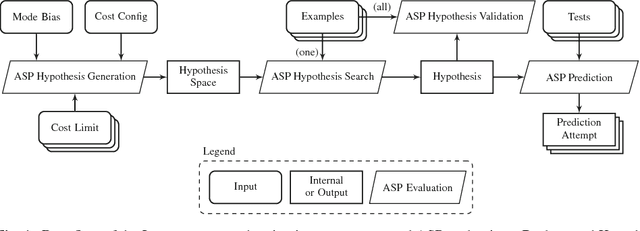
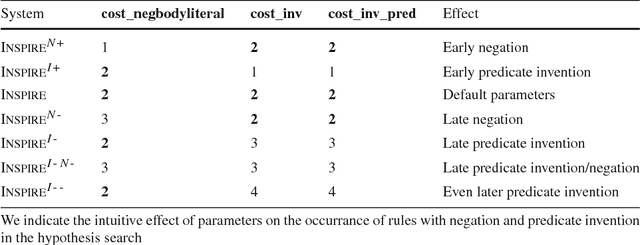

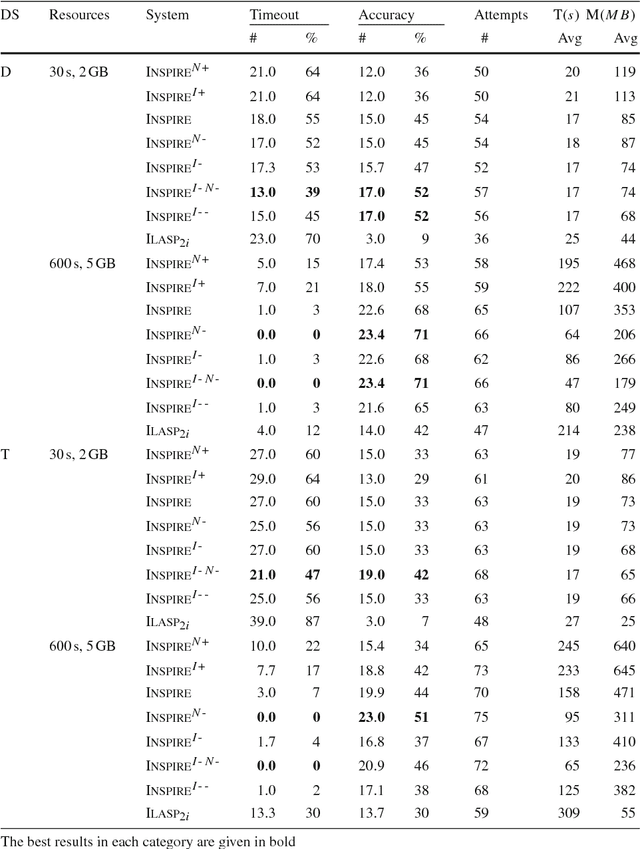
We describe the Inspire system which participated in the first competition on Inductive Logic Programming (ILP). Inspire is based on Answer Set Programming (ASP). The distinguishing feature of Inspire is an ASP encoding for hypothesis space generation: given a set of facts representing the mode bias, and a set of cost configuration parameters, each answer set of this encoding represents a single rule that is considered for finding a hypothesis that entails the given examples. Compared with state-of-the-art methods that use the length of the rule body as a metric for rule complexity, our approach permits a much more fine-grained specification of the shape of hypothesis candidate rules. The Inspire system iteratively increases the rule cost limit and thereby increases the search space until it finds a suitable hypothesis. The system searches for a hypothesis that entails a single example at a time, utilizing an ASP encoding derived from the encoding used in XHAIL. We perform experiments with the development and test set of the ILP competition. For comparison we also adapted the ILASP system to process competition instances. Experimental results show that the cost parameters for the hypothesis search space are an important factor for finding hypotheses to competition instances within tight resource bounds.
Technical Report: Adjudication of Coreference Annotations via Answer Set Optimization
Jan 31, 2018



We describe the first automatic approach for merging coreference annotations obtained from multiple annotators into a single gold standard. This merging is subject to certain linguistic hard constraints and optimization criteria that prefer solutions with minimal divergence from annotators. The representation involves an equivalence relation over a large number of elements. We use Answer Set Programming to describe two representations of the problem and four objective functions suitable for different datasets. We provide two structurally different real-world benchmark datasets based on the METU-Sabanci Turkish Treebank and we report our experiences in using the Gringo, Clasp, and Wasp tools for computing optimal adjudication results on these datasets.
Modeling Variations of First-Order Horn Abduction in Answer Set Programming
Jan 31, 2018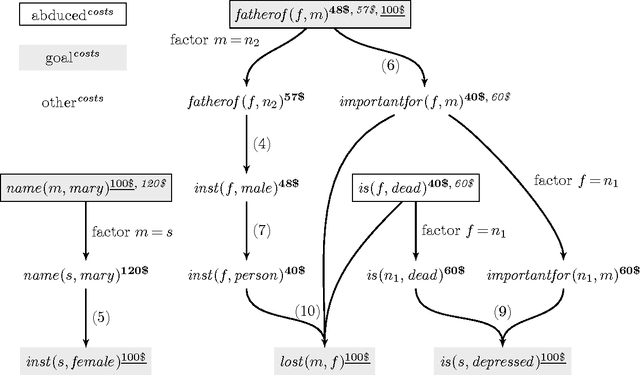
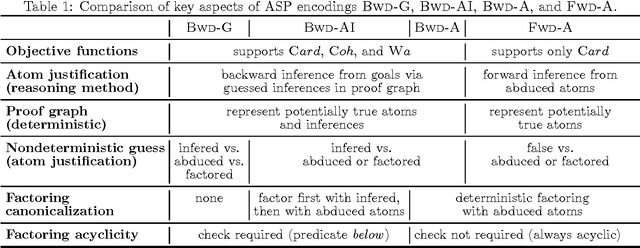
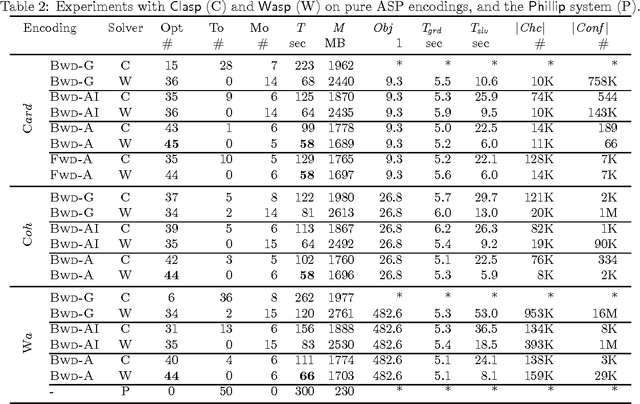

We study abduction in First Order Horn logic theories where all atoms can be abduced and we are looking for preferred solutions with respect to three objective functions: cardinality minimality, coherence, and weighted abduction. We represent this reasoning problem in Answer Set Programming (ASP), in order to obtain a flexible framework for experimenting with global constraints and objective functions, and to test the boundaries of what is possible with ASP. Realizing this problem in ASP is challenging as it requires value invention and equivalence between certain constants, because the Unique Names Assumption does not hold in general. To permit reasoning in cyclic theories, we formally describe fine-grained variations of limiting Skolemization. We identify term equivalence as a main instantiation bottleneck, and improve the efficiency of our approach with on-demand constraints that were used to eliminate the same bottleneck in state-of-the-art solvers. We evaluate our approach experimentally on the ACCEL benchmark for plan recognition in Natural Language Understanding. Our encodings are publicly available, modular, and our approach is more efficient than state-of-the-art solvers on the ACCEL benchmark.
* Technical Report
Constraints, Lazy Constraints, or Propagators in ASP Solving: An Empirical Analysis
Jul 13, 2017



Answer Set Programming (ASP) is a well-established declarative paradigm. One of the successes of ASP is the availability of efficient systems. State-of-the-art systems are based on the ground+solve approach. In some applications this approach is infeasible because the grounding of one or few constraints is expensive. In this paper, we systematically compare alternative strategies to avoid the instantiation of problematic constraints, that are based on custom extensions of the solver. Results on real and synthetic benchmarks highlight some strengths and weaknesses of the different strategies. (Under consideration for acceptance in TPLP, ICLP 2017 Special Issue.)
* Paper presented at the 33nd International Conference on Logic Programming (ICLP 2017), Melbourne, Australia, August 28 to September 1, 2017. 16 pages
Improving Scalability of Inductive Logic Programming via Pruning and Best-Effort Optimisation
Jun 16, 2017

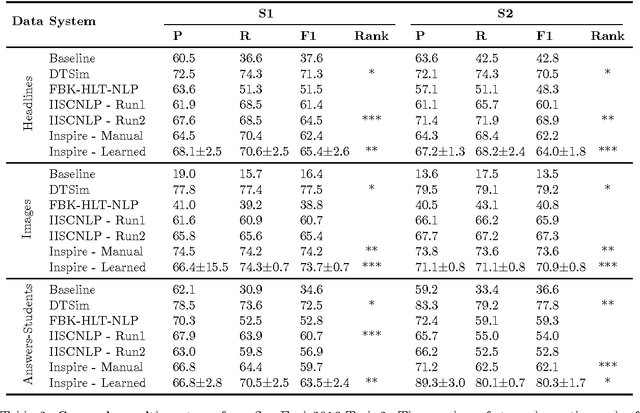
Inductive Logic Programming (ILP) combines rule-based and statistical artificial intelligence methods, by learning a hypothesis comprising a set of rules given background knowledge and constraints for the search space. We focus on extending the XHAIL algorithm for ILP which is based on Answer Set Programming and we evaluate our extensions using the Natural Language Processing application of sentence chunking. With respect to processing natural language, ILP can cater for the constant change in how we use language on a daily basis. At the same time, ILP does not require huge amounts of training examples such as other statistical methods and produces interpretable results, that means a set of rules, which can be analysed and tweaked if necessary. As contributions we extend XHAIL with (i) a pruning mechanism within the hypothesis generalisation algorithm which enables learning from larger datasets, (ii) a better usage of modern solver technology using recently developed optimisation methods, and (iii) a time budget that permits the usage of suboptimal results. We evaluate these improvements on the task of sentence chunking using three datasets from a recent SemEval competition. Results show that our improvements allow for learning on bigger datasets with results that are of similar quality to state-of-the-art systems on the same task. Moreover, we compare the hypotheses obtained on datasets to gain insights on the structure of each dataset.
* 24 pages, preprint of article accepted at Expert Systems With Applications