 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve and Optimize by Evolving Code
May 29, 2026Combinatorial and optimization problems are fundamental to many industrial AI applications. Solving large-scale real-world instances of such problems typically requires careful problem formalization, specialized solvers, and expert-designed heuristics. Thus, experts need to specify not only what solutions are, but also how they are derived. By introducing the tool CHECKMATE, we show that algorithm generation via code evolution represents a paradigm shift by eliminating the need to formulate the how. CHECKMATE solely relies on the what. Specifically, a formal specification ensures solutions' correctness and enables systematic performance evaluation of the generated programs, while a natural language description guides the evolutionary process. The effectiveness of our method is demonstrated on selected problems from two industrial domains: configuration and scheduling. In all cases, the evolved algorithms consistently outperform state-of-the-art solvers. This underscores the potential of formal methods in guiding code evolution for automatically solving complex real-world problems.
Investigating the Grounding Bottleneck for a Large-Scale Configuration Problem: Existing Tools and Constraint-Aware Guessing
Jan 07, 2026Answer set programming (ASP) aims to realize the AI vision: The user specifies the problem, and the computer solves it. Indeed, ASP has made this vision true in many application domains. However, will current ASP solving techniques scale up for large configuration problems? As a benchmark for such problems, we investigated the configuration of electronic systems, which may comprise more than 30,000 components. We show the potential and limits of current ASP technology, focusing on methods that address the so-called grounding bottleneck, i.e., the sharp increase of memory demands in the size of the problem instances. To push the limits, we investigated the incremental solving approach, which proved effective in practice. However, even in the incremental approach, memory demands impose significant limits. Based on an analysis of grounding, we developed the method constraint-aware guessing, which significantly reduced the memory need.
* In Proceedings ICLP 2025, arXiv:2601.00047
Specifying and Exploiting Non-Monotonic Domain-Specific Declarative Heuristics in Answer Set Programming
Sep 19, 2022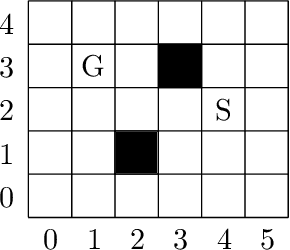
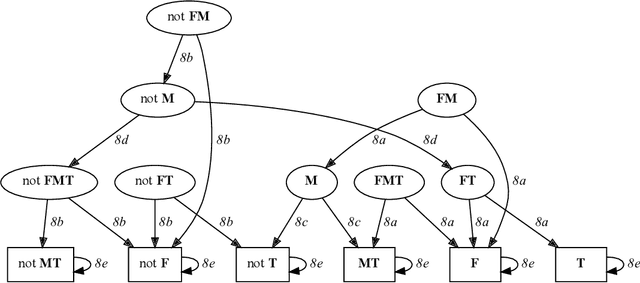
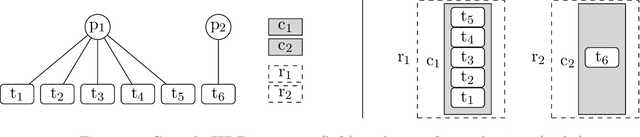
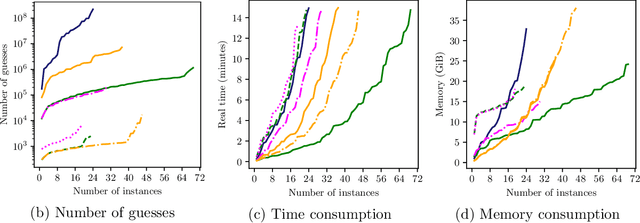
Domain-specific heuristics are an essential technique for solving combinatorial problems efficiently. Current approaches to integrate domain-specific heuristics with Answer Set Programming (ASP) are unsatisfactory when dealing with heuristics that are specified non-monotonically on the basis of partial assignments. Such heuristics frequently occur in practice, for example, when picking an item that has not yet been placed in bin packing. Therefore, we present novel syntax and semantics for declarative specifications of domain-specific heuristics in ASP. Our approach supports heuristic statements that depend on the partial assignment maintained during solving, which has not been possible before. We provide an implementation in ALPHA that makes ALPHA the first lazy-grounding ASP system to support declaratively specified domain-specific heuristics. Two practical example domains are used to demonstrate the benefits of our proposal. Additionally, we use our approach to implement informed} search with A*, which is tackled within ASP for the first time. A* is applied to two further search problems. The experiments confirm that combining lazy-grounding ASP solving and our novel heuristics can be vital for solving industrial-size problems.
Proceedings 36th International Conference on Logic Programming (Technical Communications)
Sep 19, 2020Since the first conference held in Marseille in 1982, ICLP has been the premier international event for presenting research in logic programming. Contributions are solicited in all areas of logic programming and related areas, including but not restricted to: - Foundations: Semantics, Formalisms, Answer-Set Programming, Non-monotonic Reasoning, Knowledge Representation. - Declarative Programming: Inference engines, Analysis, Type and mode inference, Partial evaluation, Abstract interpretation, Transformation, Validation, Verification, Debugging, Profiling, Testing, Logic-based domain-specific languages, constraint handling rules. - Related Paradigms and Synergies: Inductive and Co-inductive Logic Programming, Constraint Logic Programming, Interaction with SAT, SMT and CSP solvers, Logic programming techniques for type inference and theorem proving, Argumentation, Probabilistic Logic Programming, Relations to object-oriented and Functional programming, Description logics, Neural-Symbolic Machine Learning, Hybrid Deep Learning and Symbolic Reasoning. - Implementation: Concurrency and distribution, Objects, Coordination, Mobility, Virtual machines, Compilation, Higher Order, Type systems, Modules, Constraint handling rules, Meta-programming, Foreign interfaces, User interfaces. - Applications: Databases, Big Data, Data Integration and Federation, Software Engineering, Natural Language Processing, Web and Semantic Web, Agents, Artificial Intelligence, Bioinformatics, Education, Computational life sciences, Education, Cybersecurity, and Robotics.
Advancing Lazy-Grounding ASP Solving Techniques -- Restarts, Phase Saving, Heuristics, and More
Aug 08, 2020Answer-Set Programming (ASP) is a powerful and expressive knowledge representation paradigm with a significant number of applications in logic-based AI. The traditional ground-and-solve approach, however, requires ASP programs to be grounded upfront and thus suffers from the so-called grounding bottleneck (i.e., ASP programs easily exhaust all available memory and thus become unsolvable). As a remedy, lazy-grounding ASP solvers have been developed, but many state-of-the-art techniques for grounded ASP solving have not been available to them yet. In this work we present, for the first time, adaptions to the lazy-grounding setting for many important techniques, like restarts, phase saving, domain-independent heuristics, and learned-clause deletion. Furthermore, we investigate their effects and in general observe a large improvement in solving capabilities and also uncover negative effects in certain cases, indicating the need for portfolio solving as known from other solvers. Under consideration for acceptance in TPLP.
Conflict Generalisation in ASP: Learning Correct and Effective Non-Ground Constraints
Aug 07, 2020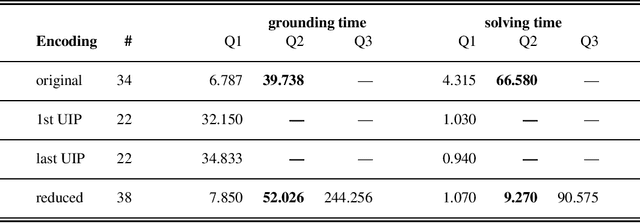
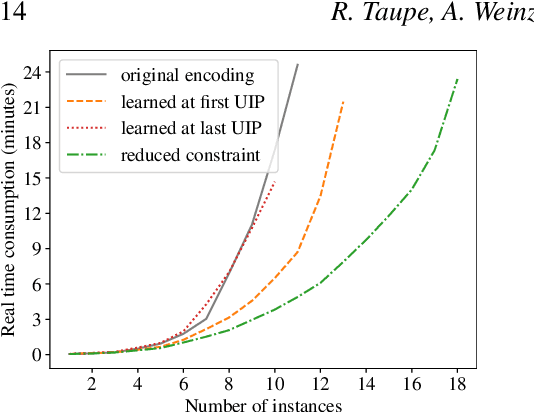
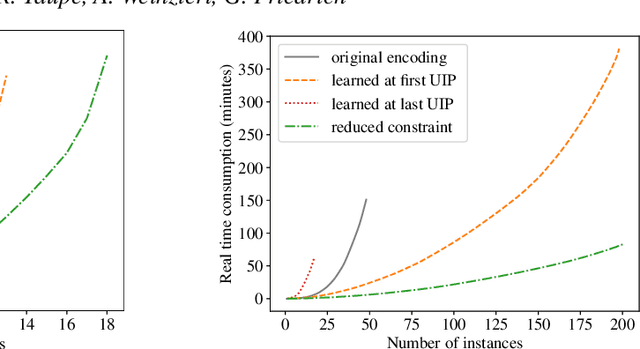
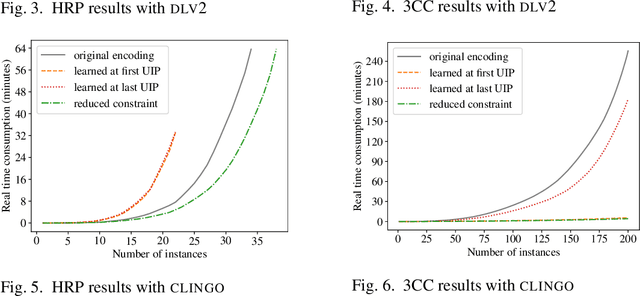
Generalising and re-using knowledge learned while solving one problem instance has been neglected by state-of-the-art answer set solvers. We suggest a new approach that generalises learned nogoods for re-use to speed-up the solving of future problem instances. Our solution combines well-known ASP solving techniques with deductive logic-based machine learning. Solving performance can be improved by adding learned non-ground constraints to the original program. We demonstrate the effects of our method by means of realistic examples, showing that our approach requires low computational cost to learn constraints that yield significant performance benefits in our test cases. These benefits can be seen with ground-and-solve systems as well as lazy-grounding systems. However, ground-and-solve systems suffer from additional grounding overheads, induced by the additional constraints in some cases. By means of conflict minimization, non-minimal learned constraints can be reduced. This can result in significant reductions of grounding and solving efforts, as our experiments show. (Under consideration for acceptance in TPLP.)
Exploiting Partial Knowledge in Declarative Domain-Specific Heuristics for ASP
Sep 18, 2019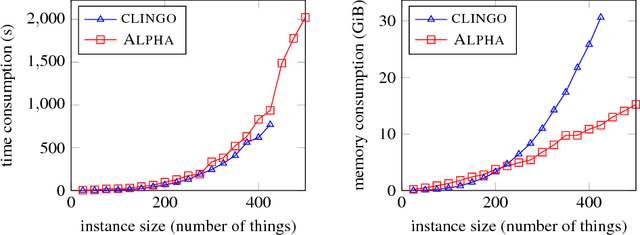
Domain-specific heuristics are an important technique for solving combinatorial problems efficiently. We propose a novel semantics for declarative specifications of domain-specific heuristics in Answer Set Programming (ASP). Decision procedures that are based on a partial solution are a frequent ingredient of existing domain-specific heuristics, e.g., for placing an item that has not been placed yet in bin packing. Therefore, in our novel semantics negation as failure and aggregates in heuristic conditions are evaluated on a partial solver state. State-of-the-art solvers do not allow such a declarative specification. Our implementation in the lazy-grounding ASP system Alpha supports heuristic directives under this semantics. By that, we also provide the first implementation for incorporating declaratively specified domain-specific heuristics in a lazy-grounding setting. Experiments confirm that the combination of ASP solving with lazy grounding and our novel heuristics can be a vital ingredient for solving industrial-size problems.
* In Proceedings ICLP 2019, arXiv:1909.07646
Degrees of Laziness in Grounding: Effects of Lazy-Grounding Strategies on ASP Solving
Mar 29, 2019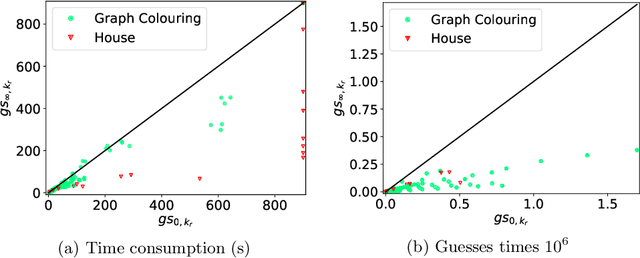
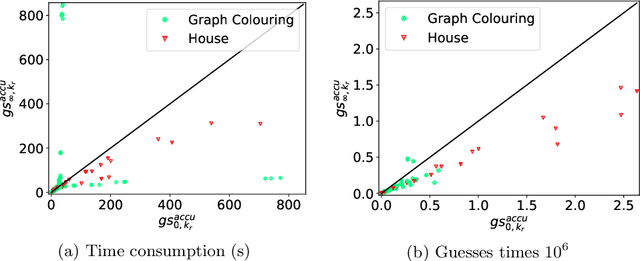
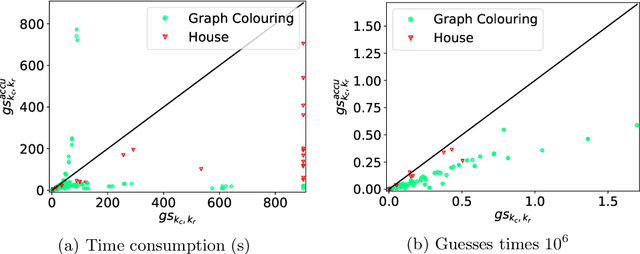
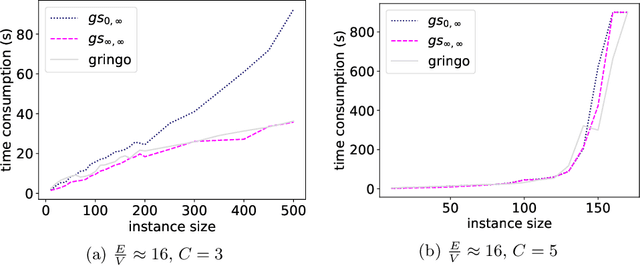
The traditional ground-and-solve approach to Answer Set Programming (ASP) suffers from the grounding bottleneck, which makes large-scale problem instances unsolvable. Lazy grounding is an alternative approach that interleaves grounding with solving and thus uses space more efficiently. The limited view on the search space in lazy grounding poses unique challenges, however, and can have adverse effects on solving performance. In this paper we present a novel characterization of degrees of laziness in grounding for ASP, i.e. of compromises between lazily grounding as little as possible and the traditional full grounding upfront. We investigate how these degrees of laziness compare to each other formally as well as, by means of an experimental analysis using a number of benchmarks, in terms of their effects on solving performance. Our contributions are the introduction of a range of novel lazy grounding strategies, a formal account on their relationships and their correctness, and an investigation of their effects on solving performance. Experiments show that our approach performs significantly better than state-of-the-art lazy grounding in many cases.
Interactive ontology debugging: two query strategies for efficient fault localization
Apr 27, 2014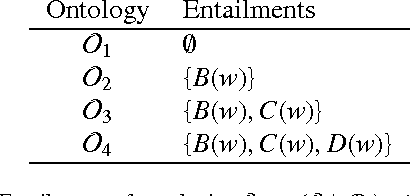
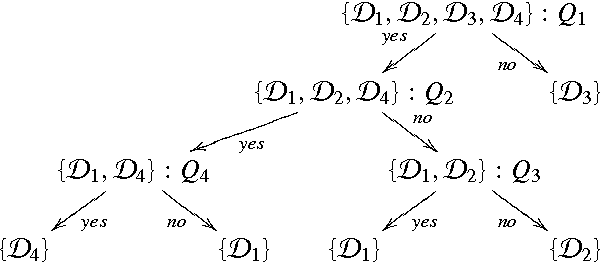
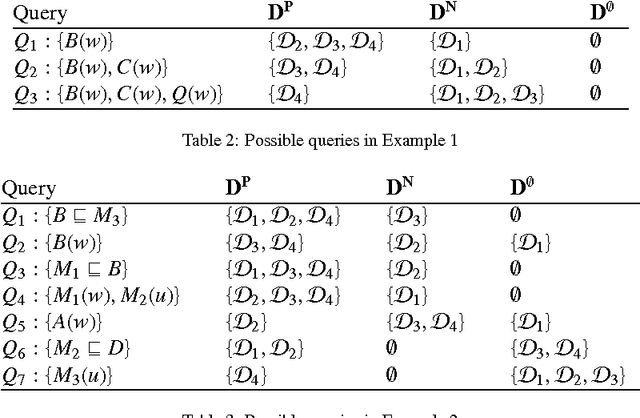
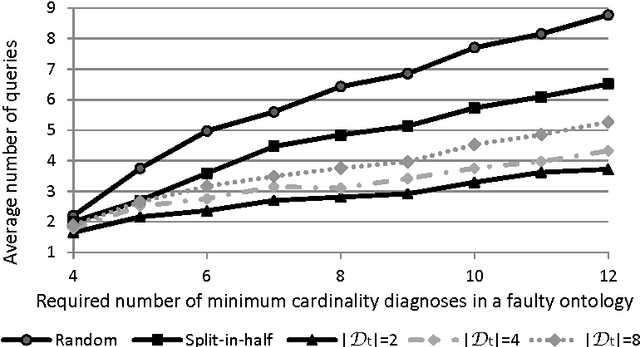
Effective debugging of ontologies is an important prerequisite for their broad application, especially in areas that rely on everyday users to create and maintain knowledge bases, such as the Semantic Web. In such systems ontologies capture formalized vocabularies of terms shared by its users. However in many cases users have different local views of the domain, i.e. of the context in which a given term is used. Inappropriate usage of terms together with natural complications when formulating and understanding logical descriptions may result in faulty ontologies. Recent ontology debugging approaches use diagnosis methods to identify causes of the faults. In most debugging scenarios these methods return many alternative diagnoses, thus placing the burden of fault localization on the user. This paper demonstrates how the target diagnosis can be identified by performing a sequence of observations, that is, by querying an oracle about entailments of the target ontology. To identify the best query we propose two query selection strategies: a simple "split-in-half" strategy and an entropy-based strategy. The latter allows knowledge about typical user errors to be exploited to minimize the number of queries. Our evaluation showed that the entropy-based method significantly reduces the number of required queries compared to the "split-in-half" approach. We experimented with different probability distributions of user errors and different qualities of the a-priori probabilities. Our measurements demonstrated the superiority of entropy-based query selection even in cases where all fault probabilities are equal, i.e. where no information about typical user errors is available.
* Published in Web Semantics: Science, Services and Agents on the World Wide Web. arXiv admin note: substantial text overlap with arXiv:1004.5339
The Partner Units Configuration Problem: Completing the Picture
Oct 17, 2013



The partner units problem (PUP) is an acknowledged hard benchmark problem for the Logic Programming community with various industrial application fields like surveillance, electrical engineering, computer networks or railway safety systems. However, computational complexity remained widely unclear so far. In this paper we provide all missing complexity results making the PUP better exploitable for benchmark testing. Furthermore, we present QuickPup, a heuristic search algorithm for PUP instances which outperforms all state-of-the-art solving approaches and which is already in use in real world industrial configuration environments.