 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Computation of Optimized Queries for Sequential Diagnosis
Dec 16, 2016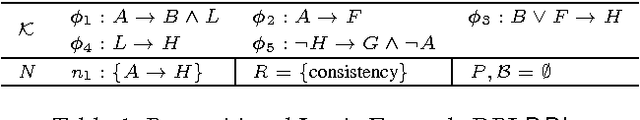
In many model-based diagnosis applications it is impossible to provide such a set of observations and/or measurements that allow to identify the real cause of a fault. Therefore, diagnosis systems often return many possible candidates, leaving the burden of selecting the correct diagnosis to a user. Sequential diagnosis techniques solve this problem by automatically generating a sequence of queries to some oracle. The answers to these queries provide additional information necessary to gradually restrict the search space by removing diagnosis candidates inconsistent with the answers. During query computation, existing sequential diagnosis methods often require the generation of many unnecessary query candidates and strongly rely on expensive logical reasoners. We tackle this issue by devising efficient heuristic query search methods. The proposed methods enable for the first time a completely reasoner-free query generation while at the same time guaranteeing optimality conditions, e.g. minimal cardinality or best understandability, of the returned query that existing methods cannot realize. Hence, the performance of this approach is independent of the (complexity of the) diagnosed system. Experiments conducted using real-world problems show that the new approach is highly scalable and outperforms existing methods by orders of magnitude.
Combining Answer Set Programming and Domain Heuristics for Solving Hard Industrial Problems (Application Paper)
Aug 02, 2016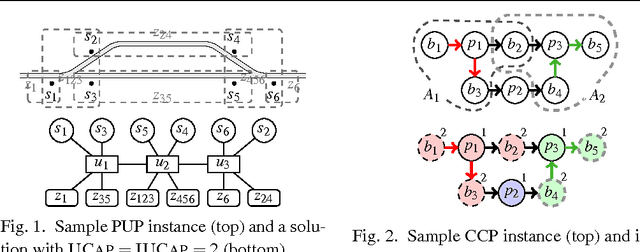
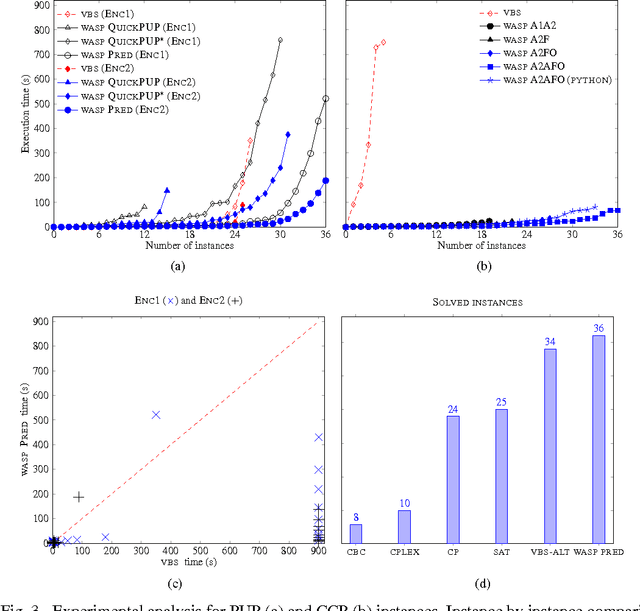
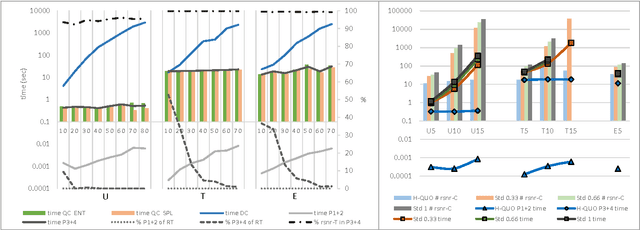
Answer Set Programming (ASP) is a popular logic programming paradigm that has been applied for solving a variety of complex problems. Among the most challenging real-world applications of ASP are two industrial problems defined by Siemens: the Partner Units Problem (PUP) and the Combined Configuration Problem (CCP). The hardest instances of PUP and CCP are out of reach for state-of-the-art ASP solvers. Experiments show that the performance of ASP solvers could be significantly improved by embedding domain-specific heuristics, but a proper effective integration of such criteria in off-the-shelf ASP implementations is not obvious. In this paper the combination of ASP and domain-specific heuristics is studied with the goal of effectively solving real-world problem instances of PUP and CCP. As a byproduct of this activity, the ASP solver WASP was extended with an interface that eases embedding new external heuristics in the solver. The evaluation shows that our domain-heuristic-driven ASP solver finds solutions for all the real-world instances of PUP and CCP ever provided by Siemens. This paper is under consideration for acceptance in TPLP.
OOASP: Connecting Object-oriented and Logic Programming
Aug 12, 2015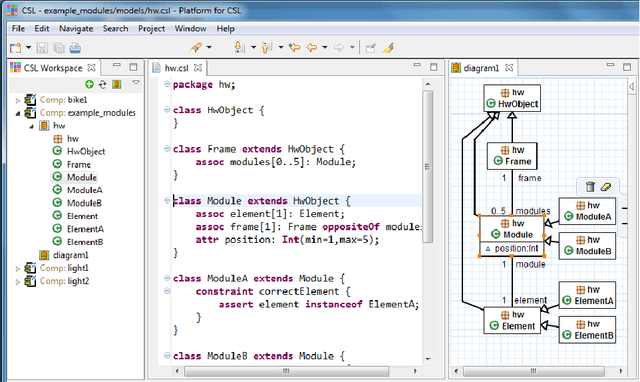

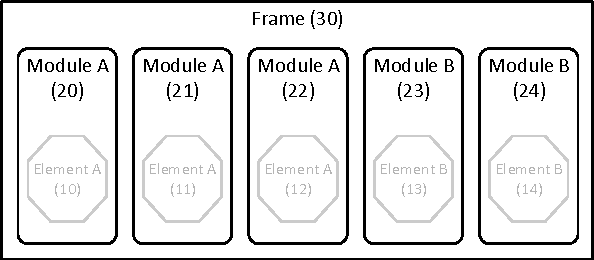
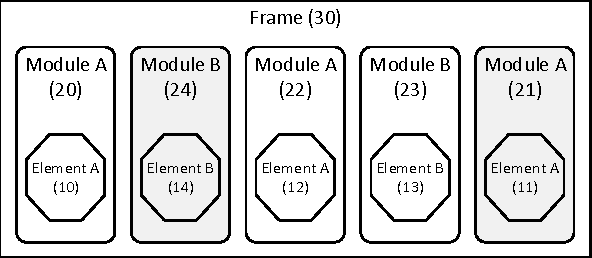
Most of contemporary software systems are implemented using an object-oriented approach. Modeling phases -- during which software engineers analyze requirements to the future system using some modeling language -- are an important part of the development process, since modeling errors are often hard to recognize and correct. In this paper we present a framework which allows the integration of Answer Set Programming into the object-oriented software development process. OOASP supports reasoning about object-oriented software models and their instantiations. Preliminary results of the OOASP application in CSL Studio, which is a Siemens internal modeling environment for product configurators, show that it can be used as a lightweight approach to verify, create and transform instantiations of object models at runtime and to support the software development process during design and testing.
Interactive Debugging of ASP Programs
Oct 28, 2014
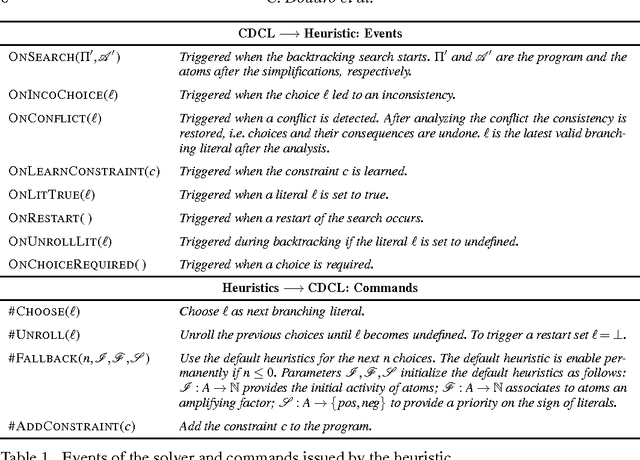
Broad application of answer set programming (ASP) for declarative problem solving requires the development of tools supporting the coding process. Program debugging is one of the crucial activities within this process. Recently suggested ASP debugging approaches allow efficient computation of possible explanations of a fault. However, even for a small program a debugger might return a large number of possible explanations and selection of the correct one must be done manually. In this paper we present an interactive query-based ASP debugging method which extends previous approaches and finds a preferred explanation by means of observations. The system queries a programmer whether a set of ground atoms must be true in all (cautiously) or some (bravely) answer sets of the program. Since some queries can be more informative than the others, we discuss query selection strategies which, given user's preferences for an explanation, can find the best query. That is, the query an answer of which reduces the overall number of queries required for the identification of a preferred explanation.
Interactive ontology debugging: two query strategies for efficient fault localization
Apr 27, 2014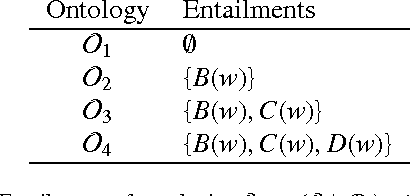
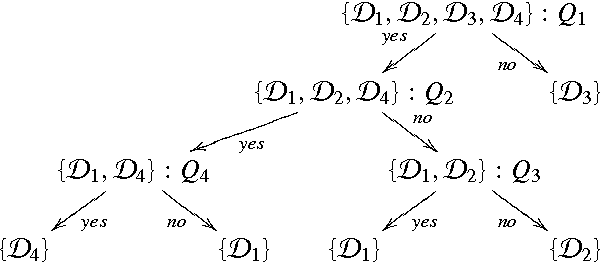
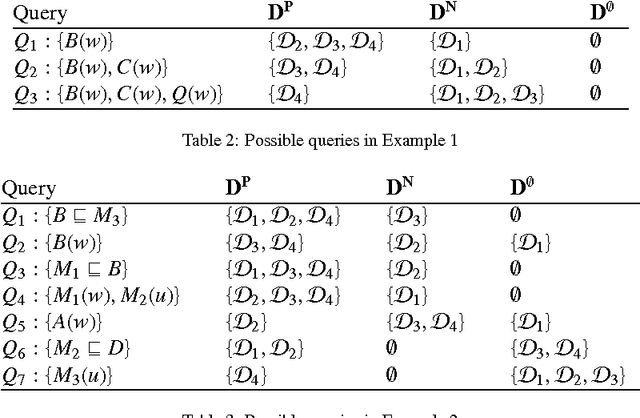
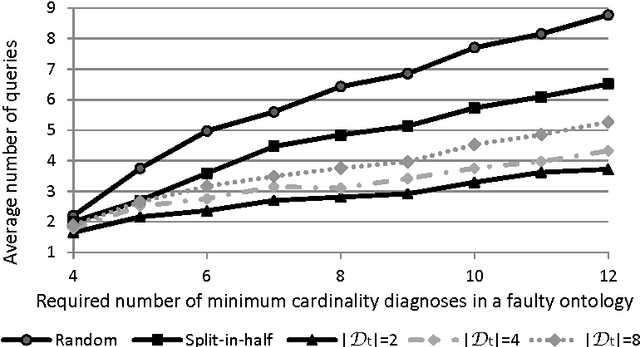
Effective debugging of ontologies is an important prerequisite for their broad application, especially in areas that rely on everyday users to create and maintain knowledge bases, such as the Semantic Web. In such systems ontologies capture formalized vocabularies of terms shared by its users. However in many cases users have different local views of the domain, i.e. of the context in which a given term is used. Inappropriate usage of terms together with natural complications when formulating and understanding logical descriptions may result in faulty ontologies. Recent ontology debugging approaches use diagnosis methods to identify causes of the faults. In most debugging scenarios these methods return many alternative diagnoses, thus placing the burden of fault localization on the user. This paper demonstrates how the target diagnosis can be identified by performing a sequence of observations, that is, by querying an oracle about entailments of the target ontology. To identify the best query we propose two query selection strategies: a simple "split-in-half" strategy and an entropy-based strategy. The latter allows knowledge about typical user errors to be exploited to minimize the number of queries. Our evaluation showed that the entropy-based method significantly reduces the number of required queries compared to the "split-in-half" approach. We experimented with different probability distributions of user errors and different qualities of the a-priori probabilities. Our measurements demonstrated the superiority of entropy-based query selection even in cases where all fault probabilities are equal, i.e. where no information about typical user errors is available.
* Published in Web Semantics: Science, Services and Agents on the World Wide Web. arXiv admin note: substantial text overlap with arXiv:1004.5339
RIO: Minimizing User Interaction in Debugging of Knowledge Bases
Mar 06, 2013
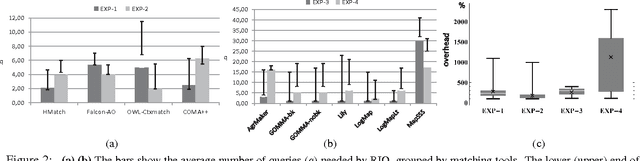
The best currently known interactive debugging systems rely upon some meta-information in terms of fault probabilities in order to improve their efficiency. However, misleading meta information might result in a dramatic decrease of the performance and its assessment is only possible a-posteriori. Consequently, as long as the actual fault is unknown, there is always some risk of suboptimal interactions. In this work we present a reinforcement learning strategy that continuously adapts its behavior depending on the performance achieved and minimizes the risk of using low-quality meta information. Therefore, this method is suitable for application scenarios where reliable prior fault estimates are difficult to obtain. Using diverse real-world knowledge bases, we show that the proposed interactive query strategy is scalable, features decent reaction time, and outperforms both entropy-based and no-risk strategies on average w.r.t. required amount of user interaction.
RIO: Minimizing User Interaction in Ontology Debugging
Sep 17, 2012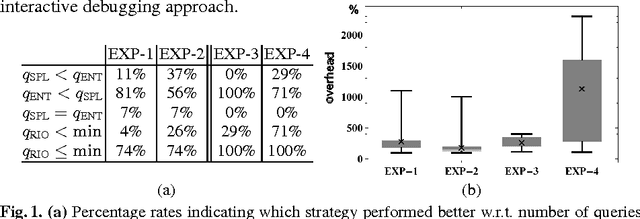
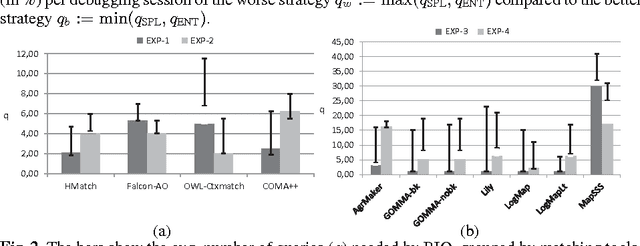
Efficient ontology debugging is a cornerstone for many activities in the context of the Semantic Web, especially when automatic tools produce (parts of) ontologies such as in the field of ontology matching. The best currently known interactive debugging systems rely upon some meta information in terms of fault probabilities, which can speed up the debugging procedure in the good case, but can also have negative impact on the performance in the bad case. The problem is that assessment of the meta information is only possible a-posteriori. Consequently, as long as the actual fault is unknown, there is always some risk of suboptimal interactive diagnoses discrimination. As an alternative, one might prefer to rely on a tool which pursues a no-risk strategy. In this case, however, possibly well-chosen meta information cannot be exploited, resulting again in inefficient debugging actions. In this work we present a reinforcement learning strategy that continuously adapts its behavior depending on the performance achieved and minimizes the risk of using low-quality meta information. Therefore, this method is suitable for application scenarios where reliable a-priori fault estimates are difficult to obtain. Using problematic ontologies in the field of ontology matching, we show that the proposed risk-aware query strategy outperforms both active learning approaches and no-risk strategies on average in terms of required amount of user interaction.
Direct computation of diagnoses for ontology debugging
Sep 05, 2012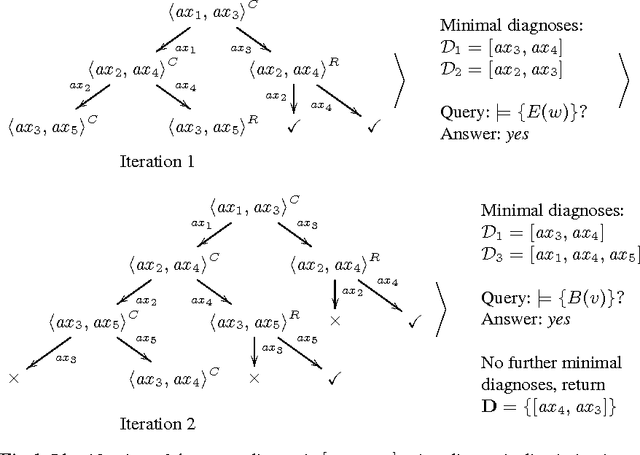
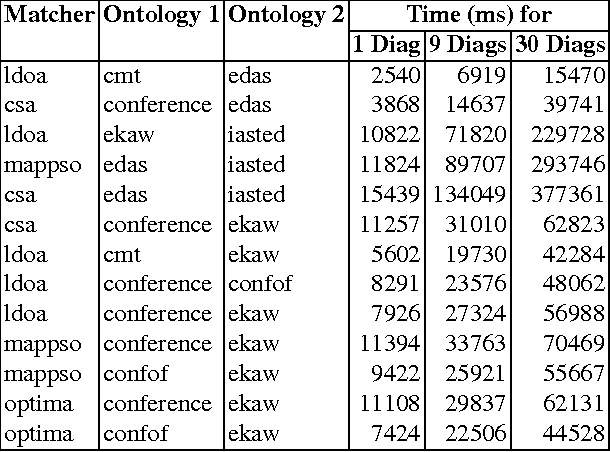


Modern ontology debugging methods allow efficient identification and localization of faulty axioms defined by a user while developing an ontology. The ontology development process in this case is characterized by rather frequent and regular calls to a reasoner resulting in an early user awareness of modeling errors. In such a scenario an ontology usually includes only a small number of conflict sets, i.e. sets of axioms preserving the faults. This property allows efficient use of standard model-based diagnosis techniques based on the application of hitting set algorithms to a number of given conflict sets. However, in many use cases such as ontology alignment the ontologies might include many more conflict sets than in usual ontology development settings, thus making precomputation of conflict sets and consequently ontology diagnosis infeasible. In this paper we suggest a debugging approach based on a direct computation of diagnoses that omits calculation of conflict sets. Embedded in an ontology debugger, the proposed algorithm is able to identify diagnoses for an ontology which includes a large number of faults and for which application of standard diagnosis methods fails. The evaluation results show that the approach is practicable and is able to identify a fault in adequate time.
Query strategy for sequential ontology debugging
Jul 21, 2011Debugging of ontologies is an important prerequisite for their wide-spread application, especially in areas that rely upon everyday users to create and maintain knowledge bases, as in the case of the Semantic Web. Recent approaches use diagnosis methods to identify causes of inconsistent or incoherent ontologies. However, in most debugging scenarios these methods return many alternative diagnoses, thus placing the burden of fault localization on the user. This paper demonstrates how the target diagnosis can be identified by performing a sequence of observations, that is, by querying an oracle about entailments of the target ontology. We exploit a-priori probabilities of typical user errors to formulate information-theoretic concepts for query selection. Our evaluation showed that the proposed method significantly reduces the number of required queries compared to myopic strategies. We experimented with different probability distributions of user errors and different qualities of the a-priori probabilities. Our measurements showed the advantageousness of information-theoretic approach to query selection even in cases where only a rough estimate of the priors is available.