 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Query-Based Ontology Debuggers Really Helping Knowledge Engineers?
Apr 02, 2019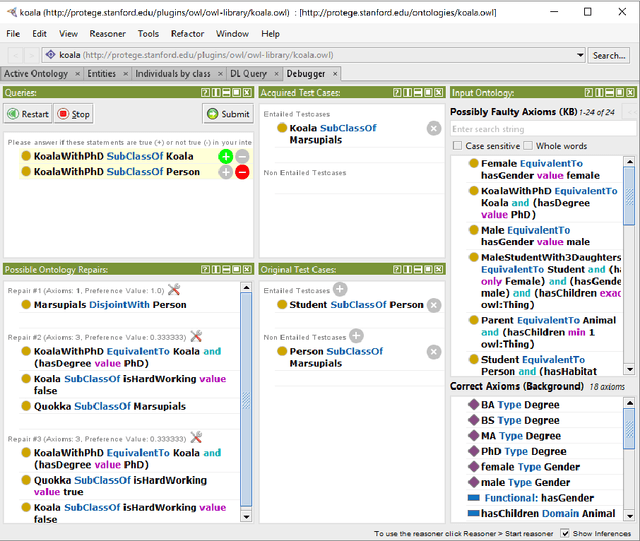


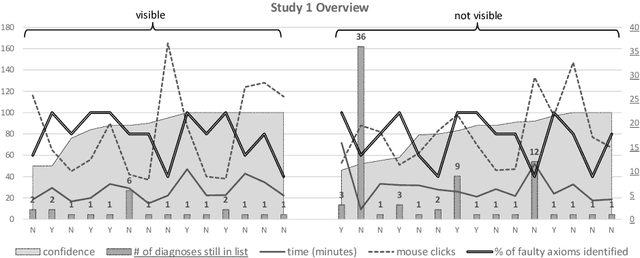
Real-world semantic or knowledge-based systems, e.g., in the biomedical domain, can become large and complex. Tool support for the localization and repair of faults within knowledge bases of such systems can therefore be essential for their practical success. Correspondingly, a number of knowledge base debugging approaches, in particular for ontology-based systems, were proposed throughout recent years. Query-based debugging is a comparably recent interactive approach that localizes the true cause of an observed problem by asking knowledge engineers a series of questions. Concrete implementations of this approach exist, such as the OntoDebug plug-in for the ontology editor Prot\'eg\'e. To validate that a newly proposed method is favorable over an existing one, researchers often rely on simulation-based comparisons. Such an evaluation approach however has certain limitations and often cannot fully inform us about a method's true usefulness. We therefore conducted different user studies to assess the practical value of query-based ontology debugging. One main insight from the studies is that the considered interactive approach is indeed more efficient than an alternative algorithmic debugging based on test cases. We also observed that users frequently made errors in the process, which highlights the importance of a careful design of the queries that users need to answer.
Interactive ontology debugging: two query strategies for efficient fault localization
Apr 27, 2014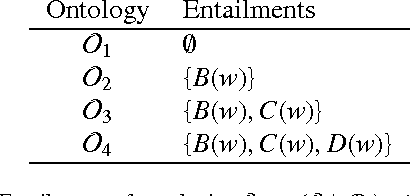
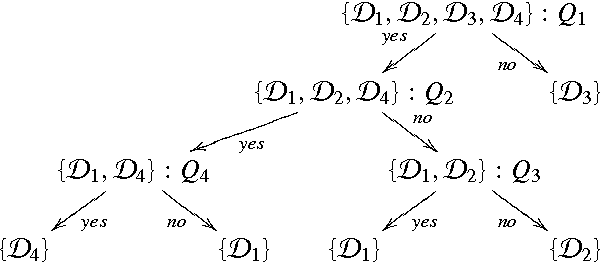
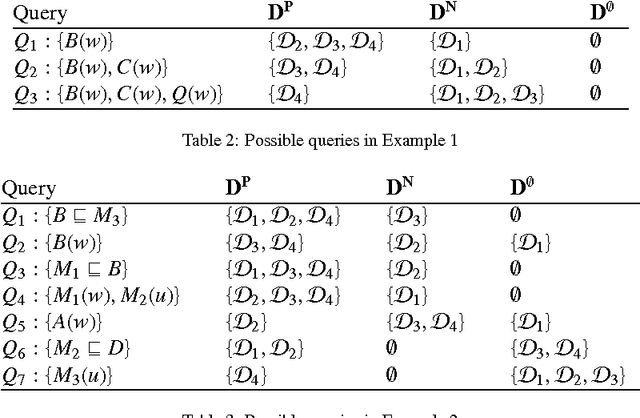
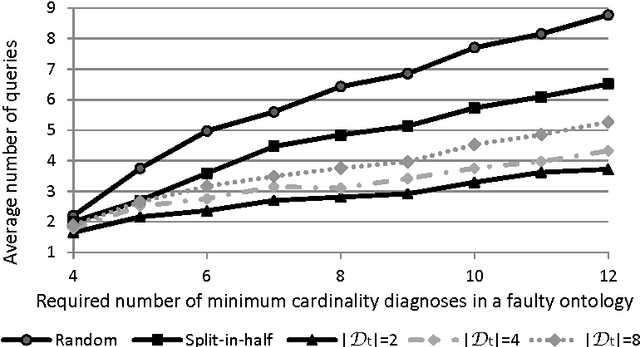
Effective debugging of ontologies is an important prerequisite for their broad application, especially in areas that rely on everyday users to create and maintain knowledge bases, such as the Semantic Web. In such systems ontologies capture formalized vocabularies of terms shared by its users. However in many cases users have different local views of the domain, i.e. of the context in which a given term is used. Inappropriate usage of terms together with natural complications when formulating and understanding logical descriptions may result in faulty ontologies. Recent ontology debugging approaches use diagnosis methods to identify causes of the faults. In most debugging scenarios these methods return many alternative diagnoses, thus placing the burden of fault localization on the user. This paper demonstrates how the target diagnosis can be identified by performing a sequence of observations, that is, by querying an oracle about entailments of the target ontology. To identify the best query we propose two query selection strategies: a simple "split-in-half" strategy and an entropy-based strategy. The latter allows knowledge about typical user errors to be exploited to minimize the number of queries. Our evaluation showed that the entropy-based method significantly reduces the number of required queries compared to the "split-in-half" approach. We experimented with different probability distributions of user errors and different qualities of the a-priori probabilities. Our measurements demonstrated the superiority of entropy-based query selection even in cases where all fault probabilities are equal, i.e. where no information about typical user errors is available.
* Published in Web Semantics: Science, Services and Agents on the World Wide Web. arXiv admin note: substantial text overlap with arXiv:1004.5339
RIO: Minimizing User Interaction in Debugging of Knowledge Bases
Mar 06, 2013
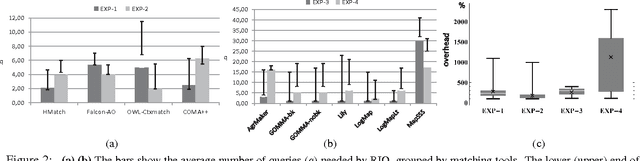
The best currently known interactive debugging systems rely upon some meta-information in terms of fault probabilities in order to improve their efficiency. However, misleading meta information might result in a dramatic decrease of the performance and its assessment is only possible a-posteriori. Consequently, as long as the actual fault is unknown, there is always some risk of suboptimal interactions. In this work we present a reinforcement learning strategy that continuously adapts its behavior depending on the performance achieved and minimizes the risk of using low-quality meta information. Therefore, this method is suitable for application scenarios where reliable prior fault estimates are difficult to obtain. Using diverse real-world knowledge bases, we show that the proposed interactive query strategy is scalable, features decent reaction time, and outperforms both entropy-based and no-risk strategies on average w.r.t. required amount of user interaction.
RIO: Minimizing User Interaction in Ontology Debugging
Sep 17, 2012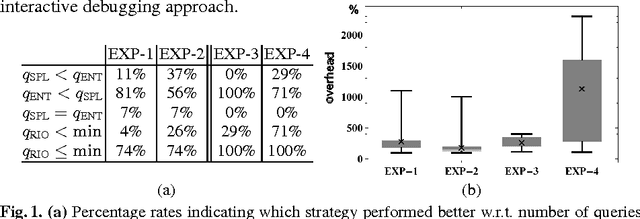
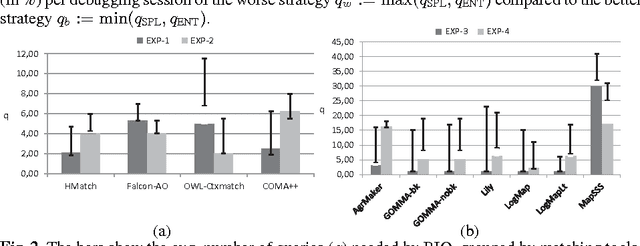
Efficient ontology debugging is a cornerstone for many activities in the context of the Semantic Web, especially when automatic tools produce (parts of) ontologies such as in the field of ontology matching. The best currently known interactive debugging systems rely upon some meta information in terms of fault probabilities, which can speed up the debugging procedure in the good case, but can also have negative impact on the performance in the bad case. The problem is that assessment of the meta information is only possible a-posteriori. Consequently, as long as the actual fault is unknown, there is always some risk of suboptimal interactive diagnoses discrimination. As an alternative, one might prefer to rely on a tool which pursues a no-risk strategy. In this case, however, possibly well-chosen meta information cannot be exploited, resulting again in inefficient debugging actions. In this work we present a reinforcement learning strategy that continuously adapts its behavior depending on the performance achieved and minimizes the risk of using low-quality meta information. Therefore, this method is suitable for application scenarios where reliable a-priori fault estimates are difficult to obtain. Using problematic ontologies in the field of ontology matching, we show that the proposed risk-aware query strategy outperforms both active learning approaches and no-risk strategies on average in terms of required amount of user interaction.
Direct computation of diagnoses for ontology debugging
Sep 05, 2012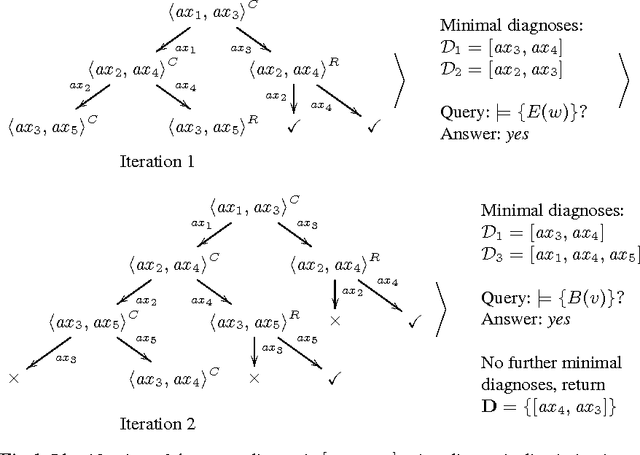
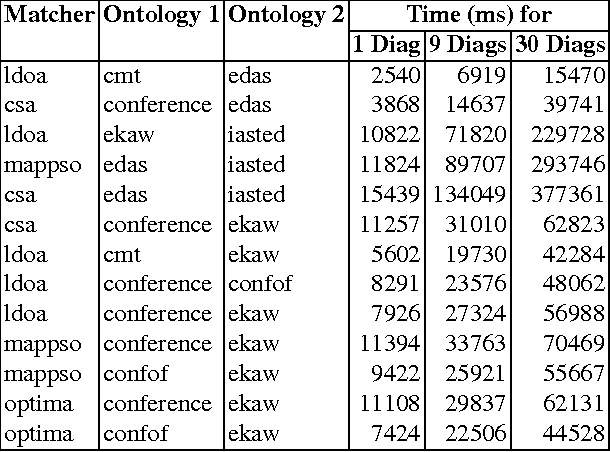


Modern ontology debugging methods allow efficient identification and localization of faulty axioms defined by a user while developing an ontology. The ontology development process in this case is characterized by rather frequent and regular calls to a reasoner resulting in an early user awareness of modeling errors. In such a scenario an ontology usually includes only a small number of conflict sets, i.e. sets of axioms preserving the faults. This property allows efficient use of standard model-based diagnosis techniques based on the application of hitting set algorithms to a number of given conflict sets. However, in many use cases such as ontology alignment the ontologies might include many more conflict sets than in usual ontology development settings, thus making precomputation of conflict sets and consequently ontology diagnosis infeasible. In this paper we suggest a debugging approach based on a direct computation of diagnoses that omits calculation of conflict sets. Embedded in an ontology debugger, the proposed algorithm is able to identify diagnoses for an ontology which includes a large number of faults and for which application of standard diagnosis methods fails. The evaluation results show that the approach is practicable and is able to identify a fault in adequate time.
Query strategy for sequential ontology debugging
Jul 21, 2011Debugging of ontologies is an important prerequisite for their wide-spread application, especially in areas that rely upon everyday users to create and maintain knowledge bases, as in the case of the Semantic Web. Recent approaches use diagnosis methods to identify causes of inconsistent or incoherent ontologies. However, in most debugging scenarios these methods return many alternative diagnoses, thus placing the burden of fault localization on the user. This paper demonstrates how the target diagnosis can be identified by performing a sequence of observations, that is, by querying an oracle about entailments of the target ontology. We exploit a-priori probabilities of typical user errors to formulate information-theoretic concepts for query selection. Our evaluation showed that the proposed method significantly reduces the number of required queries compared to myopic strategies. We experimented with different probability distributions of user errors and different qualities of the a-priori probabilities. Our measurements showed the advantageousness of information-theoretic approach to query selection even in cases where only a rough estimate of the priors is available.