 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve and Optimize by Evolving Code
May 29, 2026Combinatorial and optimization problems are fundamental to many industrial AI applications. Solving large-scale real-world instances of such problems typically requires careful problem formalization, specialized solvers, and expert-designed heuristics. Thus, experts need to specify not only what solutions are, but also how they are derived. By introducing the tool CHECKMATE, we show that algorithm generation via code evolution represents a paradigm shift by eliminating the need to formulate the how. CHECKMATE solely relies on the what. Specifically, a formal specification ensures solutions' correctness and enables systematic performance evaluation of the generated programs, while a natural language description guides the evolutionary process. The effectiveness of our method is demonstrated on selected problems from two industrial domains: configuration and scheduling. In all cases, the evolved algorithms consistently outperform state-of-the-art solvers. This underscores the potential of formal methods in guiding code evolution for automatically solving complex real-world problems.
Don't Treat the Symptom, Find the Cause! Efficient Artificial-Intelligence Methods for Debugging
Jun 22, 2023

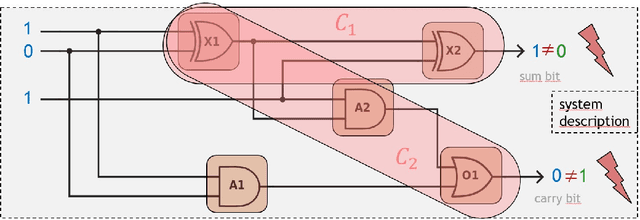

In the modern world, we are permanently using, leveraging, interacting with, and relying upon systems of ever higher sophistication, ranging from our cars, recommender systems in e-commerce, and networks when we go online, to integrated circuits when using our PCs and smartphones, the power grid to ensure our energy supply, security-critical software when accessing our bank accounts, and spreadsheets for financial planning and decision making. The complexity of these systems coupled with our high dependency on them implies both a non-negligible likelihood of system failures, and a high potential that such failures have significant negative effects on our everyday life. For that reason, it is a vital requirement to keep the harm of emerging failures to a minimum, which means minimizing the system downtime as well as the cost of system repair. This is where model-based diagnosis comes into play. Model-based diagnosis is a principled, domain-independent approach that can be generally applied to troubleshoot systems of a wide variety of types, including all the ones mentioned above, and many more. It exploits and orchestrates i.a. techniques for knowledge representation, automated reasoning, heuristic problem solving, intelligent search, optimization, stochastics, statistics, decision making under uncertainty, machine learning, as well as calculus, combinatorics and set theory to detect, localize, and fix faults in abnormally behaving systems. In this thesis, we will give an introduction to the topic of model-based diagnosis, point out the major challenges in the field, and discuss a selection of approaches from our research addressing these issues.
How should I compute my candidates? A taxonomy and classification of diagnosis computation algorithms
Jul 26, 2022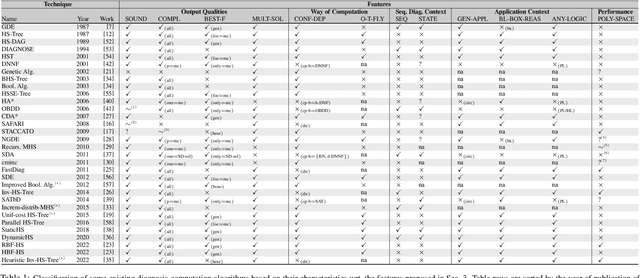
This work proposes a taxonomy for diagnosis computation methods which allows their standardized assessment, classification and comparison. The aim is to (i) give researchers and practitioners an impression of the diverse landscape of available diagnostic techniques, (ii) allow them to easily retrieve the main features as well as pros and cons of the approaches, (iii) enable an easy and clear comparison of the techniques based on their characteristics wrt. a list of important and well-defined properties, and (iv) facilitate the selection of the "right" algorithm to adopt for a particular problem case, e.g., in practical diagnostic settings, for comparison in experimental evaluations, or for reuse, modification, extension, or improvement in the course of research.
DynamicHS: Streamlining Reiter's Hitting-Set Tree for Sequential Diagnosis
Dec 21, 2020
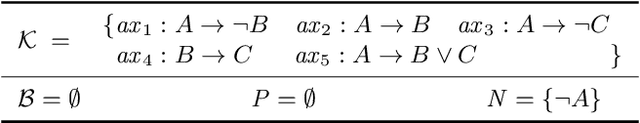


Given a system that does not work as expected, Sequential Diagnosis (SD) aims at suggesting a series of system measurements to isolate the true explanation for the system's misbehavior from a potentially exponential set of possible explanations. To reason about the best next measurement, SD methods usually require a sample of possible fault explanations at each step of the iterative diagnostic process. The computation of this sample can be accomplished by various diagnostic search algorithms. Among those, Reiter's HS-Tree is one of the most popular due its desirable properties and general applicability. Usually, HS-Tree is used in a stateless fashion throughout the SD process to (re)compute a sample of possible fault explanations in each iteration, each time given the latest (updated) system knowledge including all so-far collected measurements. At this, the built search tree is discarded between two iterations, although often large parts of the tree have to be rebuilt in the next iteration, involving redundant operations and calls to costly reasoning services. As a remedy to this, we propose DynamicHS, a variant of HS-Tree that maintains state throughout the diagnostic session and additionally embraces special strategies to minimize the number of expensive reasoner invocations. In this vein, DynamicHS provides an answer to a longstanding question posed by Raymond Reiter in his seminal paper from 1987. Extensive evaluations on real-world diagnosis problems prove the reasonability of the DynamicHS and testify its clear superiority to HS-Tree wrt. computation time. More specifically, DynamicHS outperformed HS-Tree in 96% of the executed sequential diagnosis sessions and, per run, the latter required up to 800% the time of the former. Remarkably, DynamicHS achieves these performance improvements while preserving all desirable properties as well as the general applicability of HS-Tree.
Memory-Limited Model-Based Diagnosis
Oct 08, 2020

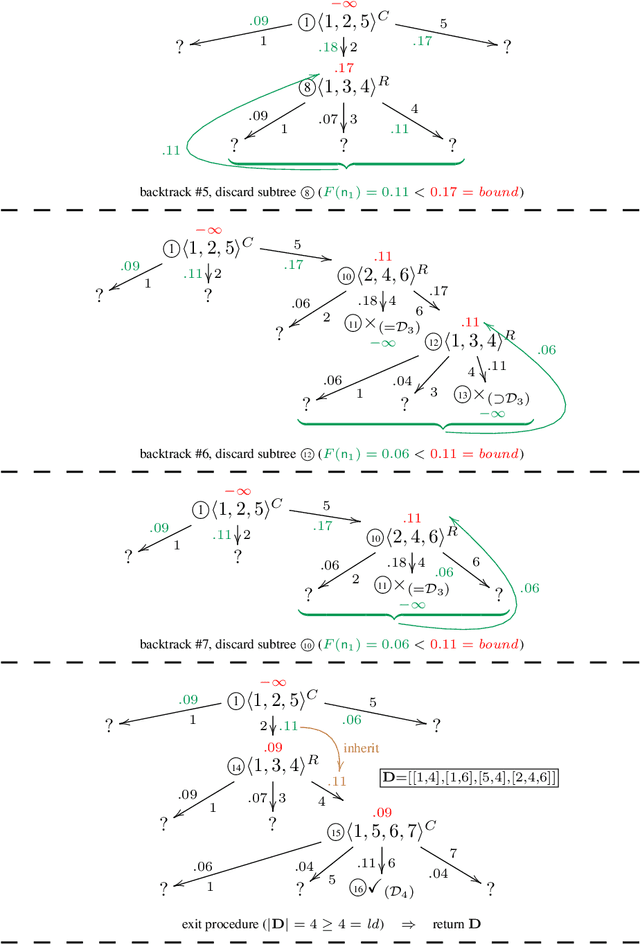
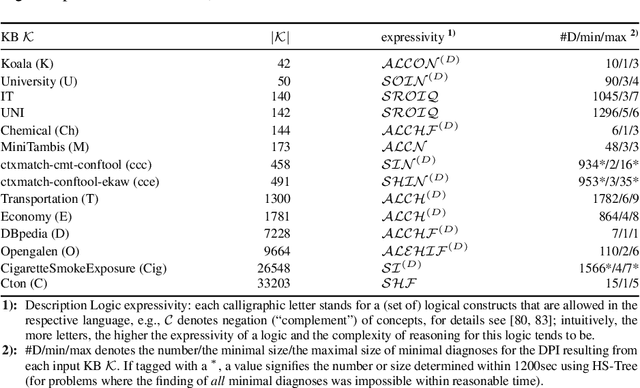
Various model-based diagnosis scenarios require the computation of most preferred fault explanations. Existing algorithms that are sound (i.e., output only actual fault explanations) and complete (i.e., can return all explanations), however, require exponential space to achieve this task. As a remedy, we propose two novel diagnostic search algorithms, called RBF-HS (Recursive Best-First Hitting Set Search) and HBF-HS (Hybrid Best-First Hitting Set Search), which build upon tried and tested techniques from the heuristic search domain. RBF-HS can enumerate an arbitrary predefined finite number of fault explanations in best-first order within linear space bounds, without sacrificing the desirable soundness or completeness properties. The idea of HBF-HS is to find a trade-off between runtime optimization and a restricted space consumption that does not exceed the available memory. In extensive experiments on real-world diagnosis cases we compared our approaches to Reiter's HS-Tree, a state-of-the-art method that gives the same theoretical guarantees and is as general(ly applicable) as the suggested algorithms. For the computation of minimum-cardinality fault explanations, we find that (1) RBF-HS reduces memory requirements substantially in most cases by up to several orders of magnitude, (2) in more than a third of the cases, both memory savings and runtime savings are achieved, and (3) given the runtime overhead is significant, using HBF-HS instead of RBF-HS reduces the runtime to values comparable with HS-Tree while keeping the used memory reasonably bounded. When computing most probable fault explanations, we observe that RBF-HS tends to trade memory savings more or less one-to-one for runtime overheads. Again, HBF-HS proves to be a reasonable remedy to cut down the runtime while complying with practicable memory bounds.
Sound, Complete, Linear-Space, Best-First Diagnosis Search
Sep 25, 2020
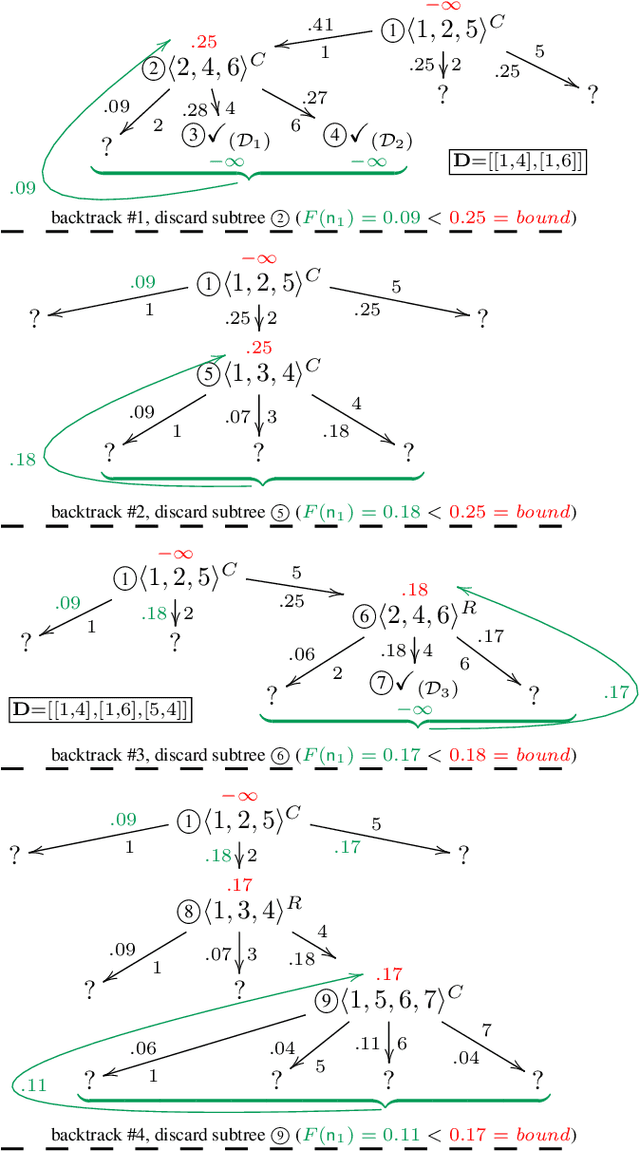
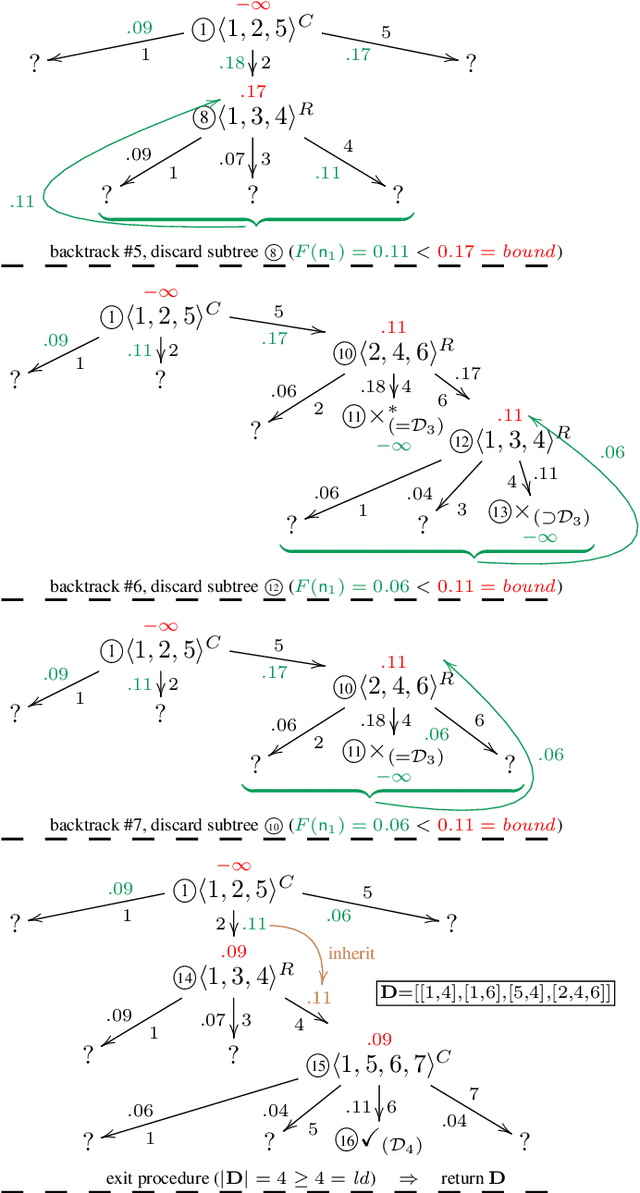
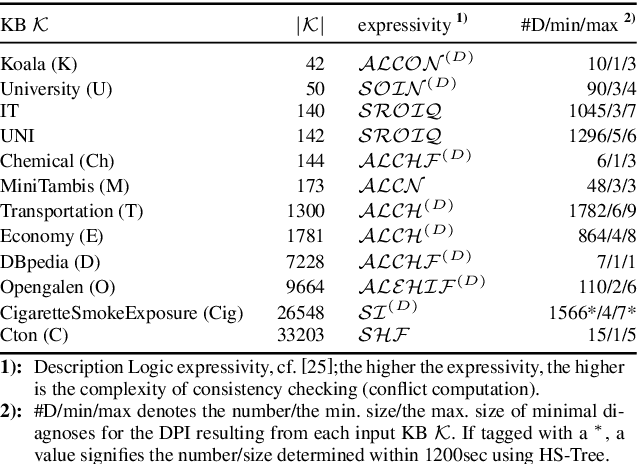
Various model-based diagnosis scenarios require the computation of the most preferred fault explanations. Existing algorithms that are sound (i.e., output only actual fault explanations) and complete (i.e., can return all explanations), however, require exponential space to achieve this task. As a remedy, to enable successful diagnosis on memory-restricted devices and for memory-intensive problem cases, we propose RBF-HS, a diagnostic search method based on Korf's well-known RBFS algorithm. RBF-HS can enumerate an arbitrary fixed number of fault explanations in best-first order within linear space bounds, without sacrificing the desirable soundness or completeness properties. Evaluations using real-world diagnosis cases show that RBF-HS, when used to compute minimum-cardinality fault explanations, in most cases saves substantial space (up to 98 %) while requiring only reasonably more or even less time than Reiter's HS-Tree, a commonly used and as generally applicable sound, complete and best-first diagnosis search.
Do We Really Sample Right In Model-Based Diagnosis?
Sep 25, 2020
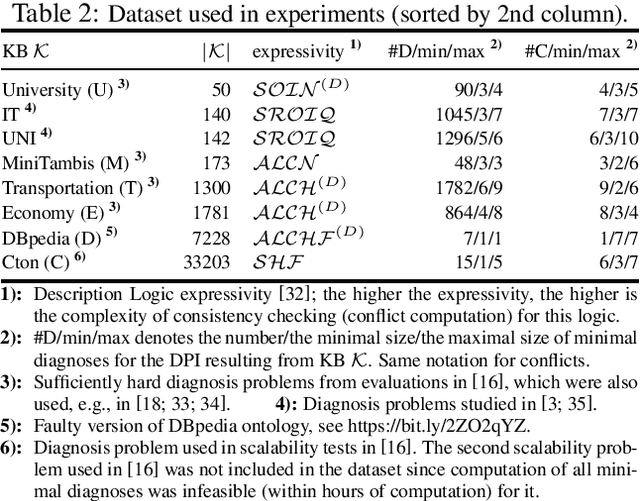
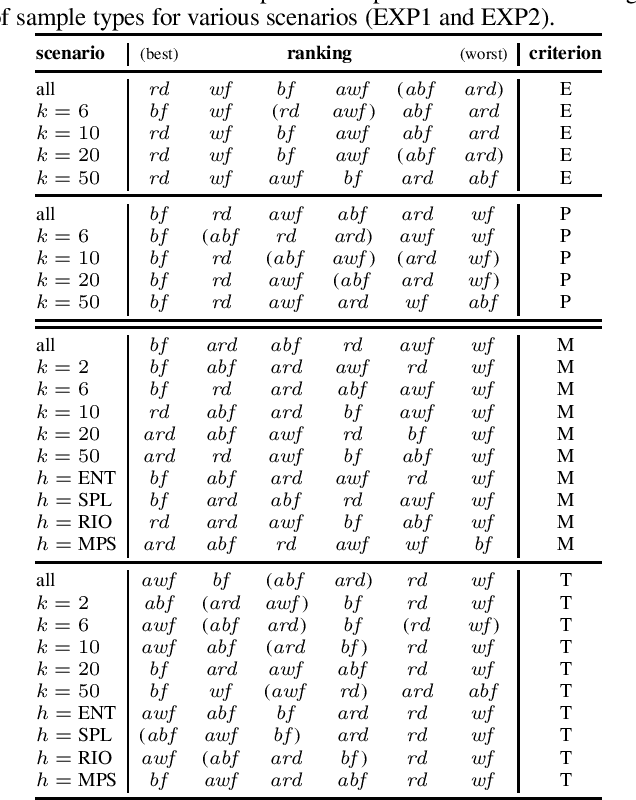

Statistical samples, in order to be representative, have to be drawn from a population in a random and unbiased way. Nevertheless, it is common practice in the field of model-based diagnosis to make estimations from (biased) best-first samples. One example is the computation of a few most probable possible fault explanations for a defective system and the use of these to assess which aspect of the system, if measured, would bring the highest information gain. In this work, we scrutinize whether these statistically not well-founded conventions, that both diagnosis researchers and practitioners have adhered to for decades, are indeed reasonable. To this end, we empirically analyze various sampling methods that generate fault explanations. We study the representativeness of the produced samples in terms of their estimations about fault explanations and how well they guide diagnostic decisions, and we investigate the impact of sample size, the optimal trade-off between sampling efficiency and effectivity, and how approximate sampling techniques compare to exact ones.
The Scheduling Job-Set Optimization Problem: A Model-Based Diagnosis Approach
Sep 23, 2020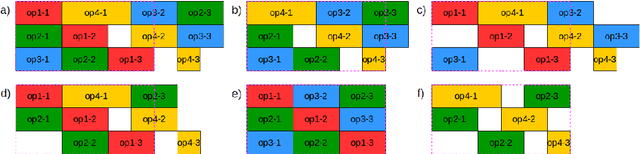
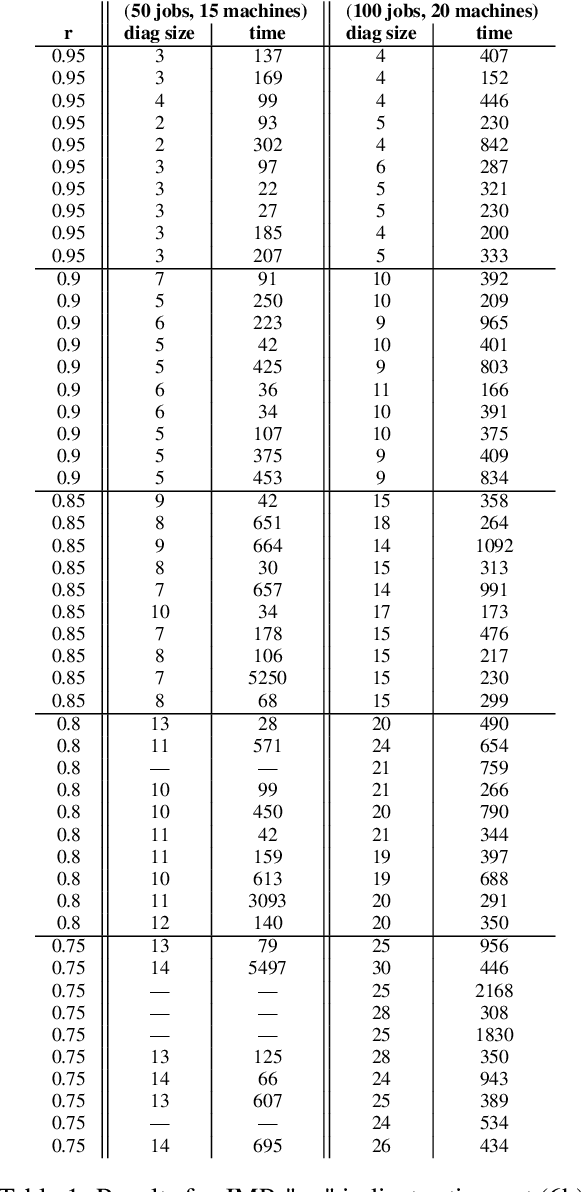
A common issue for companies is that the volume of product orders may at times exceed the production capacity. We formally introduce two novel problems dealing with the question which orders to discard or postpone in order to meet certain (timeliness) goals, and try to approach them by means of model-based diagnosis. In thorough analyses, we identify many similarities of the introduced problems to diagnosis problems, but also reveal crucial idiosyncracies and outline ways to handle or leverage them. Finally, a proof-of-concept evaluation on industrial-scale problem instances from a well-known scheduling benchmark suite demonstrates that one of the two formalized problems can be well attacked by out-of-the-box model-based diagnosis tools.
On Expert Behaviors and Question Types for Efficient Query-Based Ontology Fault Localization
Jan 16, 2020We challenge existing query-based ontology fault localization methods wrt. assumptions they make, criteria they optimize, and interaction means they use. We find that their efficiency depends largely on the behavior of the interacting expert, that performed calculations can be inefficient or imprecise, and that used optimization criteria are often not fully realistic. As a remedy, we suggest a novel (and simpler) interaction approach which overcomes all identified problems and, in comprehensive experiments on faulty real-world ontologies, enables a successful fault localization while requiring fewer expert interactions in 66 % of the cases, and always at least 80 % less expert waiting time, compared to existing methods.
Understanding the QuickXPlain Algorithm: Simple Explanation and Formal Proof
Jan 08, 2020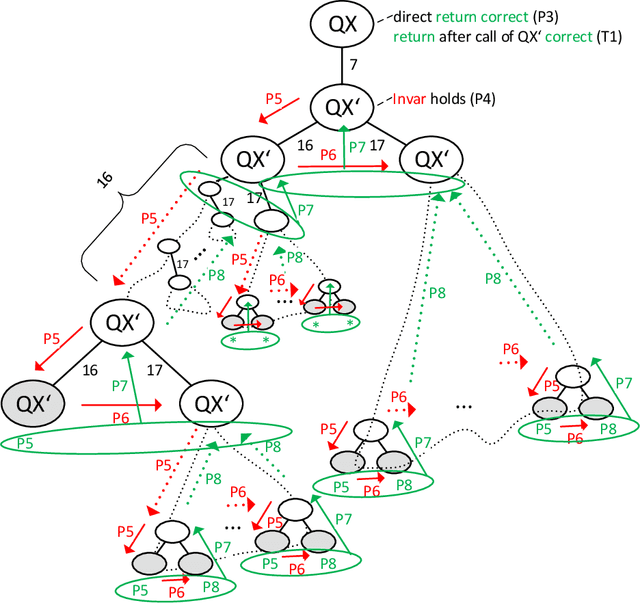
In his seminal paper of 2004, Ulrich Junker proposed the QuickXPlain algorithm, which provides a divide-and-conquer computation strategy to find within a given set an irreducible subset with a particular (monotone) property. Beside its original application in the domain of constraint satisfaction problems, the algorithm has since then found widespread adoption in areas as different as model-based diagnosis, recommender systems, verification, or the Semantic Web. This popularity is due to the frequent occurrence of the problem of finding irreducible subsets on the one hand, and to QuickXPlain's general applicability and favorable computational complexity on the other hand. However, although (we regularly experience) people are having a hard time understanding QuickXPlain and seeing why it works correctly, a proof of correctness of the algorithm has never been published. This is what we account for in this work, by explaining QuickXPlain in a novel tried and tested way and by presenting an intelligible formal proof of it. Apart from showing the correctness of the algorithm and excluding the later detection of errors (proof and trust effect), the added value of the availability of a formal proof is, e.g., (i) that the workings of the algorithm often become completely clear only after studying, verifying and comprehending the proof (didactic effect), (ii) the shown proof methodology can be used as a guidance for proving other recursive algorithms (transfer effect), and (iii) the possibility of providing "gapless" correctness proofs of systems that rely on (results computed by) QuickXPlain, such as numerous model-based debuggers (completeness effect).