 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Active Learning Heuristics for Sequential Diagnosis
Jul 09, 2018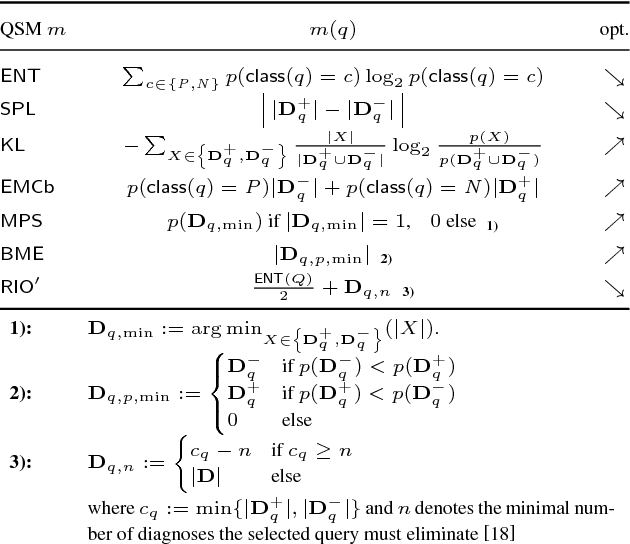
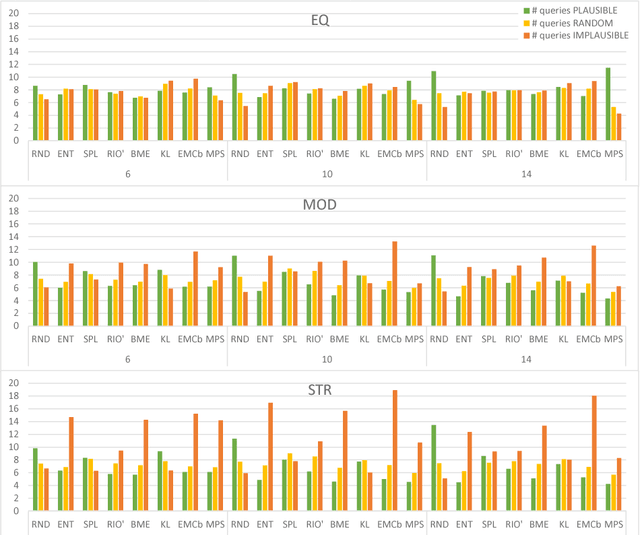


Given a malfunctioning system, sequential diagnosis aims at identifying the root cause of the failure in terms of abnormally behaving system components. As initial system observations usually do not suffice to deterministically pin down just one explanation of the system's misbehavior, additional system measurements can help to differentiate between possible explanations. The goal is to restrict the space of explanations until there is only one (highly probable) explanation left. To achieve this with a minimal-cost set of measurements, various (active learning) heuristics for selecting the best next measurement have been proposed. We report preliminary results of extensive ongoing experiments with a set of selection heuristics on real-world diagnosis cases. In particular, we try to answer questions such as "Is some heuristic always superior to all others?", "On which factors does the (relative) performance of the particular heuristics depend?" or "Under which circumstances should I use which heuristic?"
A Generally Applicable, Highly Scalable Measurement Computation and Optimization Approach to Sequential Model-Based Diagnosis
Nov 15, 2017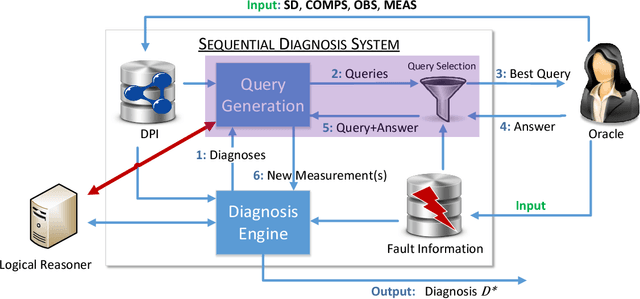



Model-Based Diagnosis deals with the identification of the real cause of a system's malfunction based on a formal system model and observations of the system behavior. When a malfunction is detected, there is usually not enough information available to pinpoint the real cause and one needs to discriminate between multiple fault hypotheses (called diagnoses). To this end, Sequential Diagnosis approaches ask an oracle for additional system measurements. This work presents strategies for (optimal) measurement selection in model-based sequential diagnosis. In particular, assuming a set of leading diagnoses being given, we show how queries (sets of measurements) can be computed and optimized along two dimensions: expected number of queries and cost per query. By means of a suitable decoupling of two optimizations and a clever search space reduction the computations are done without any inference engine calls. For the full search space, we give a method requiring only a polynomial number of inferences and show how query properties can be guaranteed which existing methods do not provide. Evaluation results using real-world problems indicate that the new method computes (virtually) optimal queries instantly independently of the size and complexity of the considered diagnosis problems and outperforms equally general methods not exploiting the proposed theory by orders of magnitude.
Inexpensive Cost-Optimized Measurement Proposal for Sequential Model-Based Diagnosis
May 28, 2017
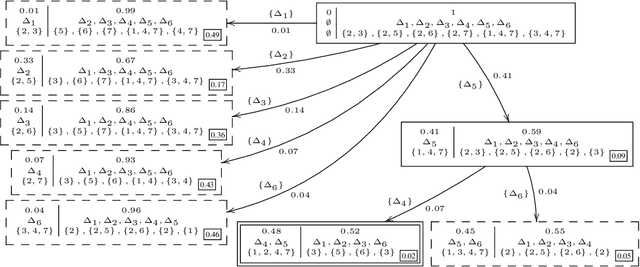
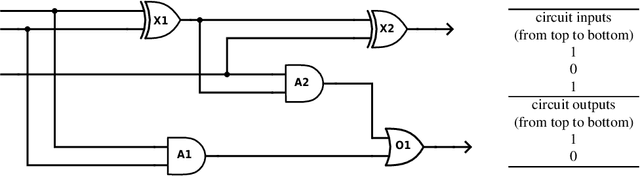

In this work we present strategies for (optimal) measurement selection in model-based sequential diagnosis. In particular, assuming a set of leading diagnoses being given, we show how queries (sets of measurements) can be computed and optimized along two dimensions: expected number of queries and cost per query. By means of a suitable decoupling of two optimizations and a clever search space reduction the computations are done without any inference engine calls. For the full search space, we give a method requiring only a polynomial number of inferences and guaranteeing query properties existing methods cannot provide. Evaluation results using real-world problems indicate that the new method computes (virtually) optimal queries instantly independently of the size and complexity of the considered diagnosis problems.
Scalable Computation of Optimized Queries for Sequential Diagnosis
Dec 16, 2016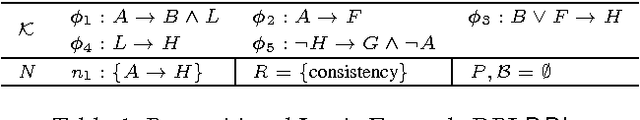
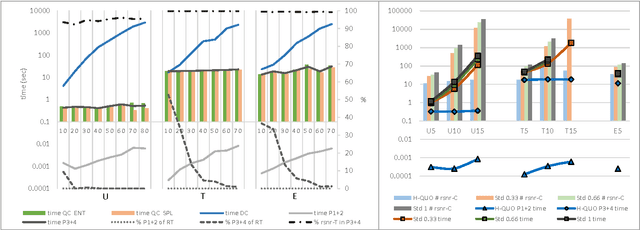
In many model-based diagnosis applications it is impossible to provide such a set of observations and/or measurements that allow to identify the real cause of a fault. Therefore, diagnosis systems often return many possible candidates, leaving the burden of selecting the correct diagnosis to a user. Sequential diagnosis techniques solve this problem by automatically generating a sequence of queries to some oracle. The answers to these queries provide additional information necessary to gradually restrict the search space by removing diagnosis candidates inconsistent with the answers. During query computation, existing sequential diagnosis methods often require the generation of many unnecessary query candidates and strongly rely on expensive logical reasoners. We tackle this issue by devising efficient heuristic query search methods. The proposed methods enable for the first time a completely reasoner-free query generation while at the same time guaranteeing optimality conditions, e.g. minimal cardinality or best understandability, of the returned query that existing methods cannot realize. Hence, the performance of this approach is independent of the (complexity of the) diagnosed system. Experiments conducted using real-world problems show that the new approach is highly scalable and outperforms existing methods by orders of magnitude.