 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA$^2$T-Net: Category-Agnostic 3D Articulation Transfer from Single Image
Jan 05, 2023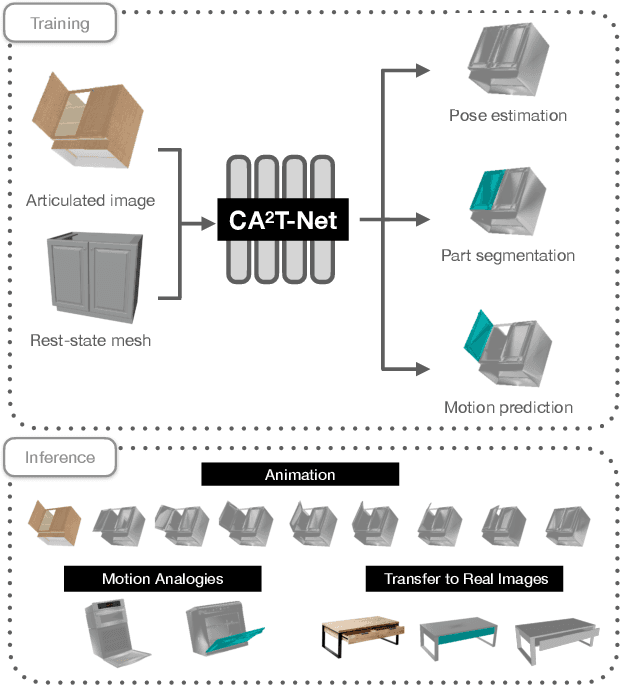
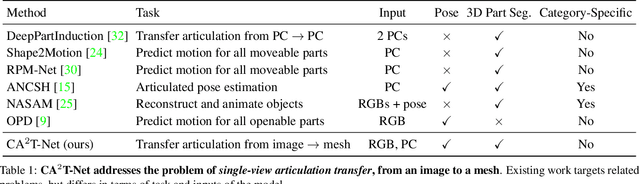
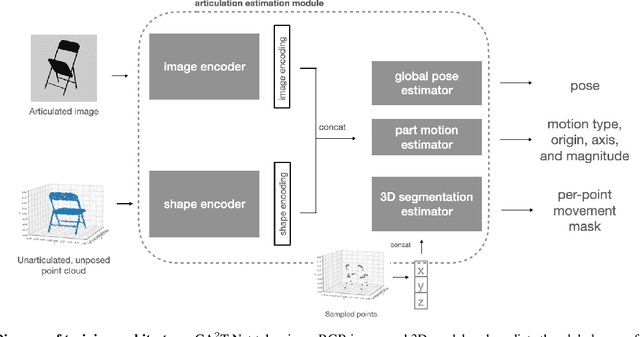
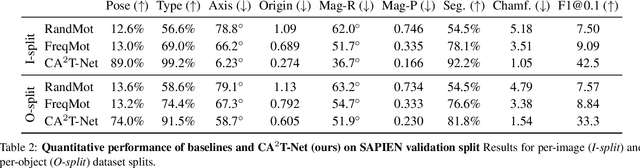
We present a neural network approach to transfer the motion from a single image of an articulated object to a rest-state (i.e., unarticulated) 3D model. Our network learns to predict the object's pose, part segmentation, and corresponding motion parameters to reproduce the articulation shown in the input image. The network is composed of three distinct branches that take a shared joint image-shape embedding and is trained end-to-end. Unlike previous methods, our approach is independent of the topology of the object and can work with objects from arbitrary categories. Our method, trained with only synthetic data, can be used to automatically animate a mesh, infer motion from real images, and transfer articulation to functionally similar but geometrically distinct 3D models at test time.
Rendu basé image avec contraintes sur les gradients
Dec 29, 2018



Multi-view image-based rendering consists in generating a novel view of a scene from a set of source views. In general, this works by first doing a coarse 3D reconstruction of the scene, and then using this reconstruction to establish correspondences between source and target views, followed by blending the warped views to get the final image. Unfortunately, discontinuities in the blending weights, due to scene geometry or camera placement, result in artifacts in the target view. In this paper, we show how to avoid these artifacts by imposing additional constraints on the image gradients of the novel view. We propose a variational framework in which an energy functional is derived and optimized by iteratively solving a linear system. We demonstrate this method on several structured and unstructured multi-view datasets, and show that it numerically outperforms state-of-the-art methods, and eliminates artifacts that result from visibility discontinuities
Symmetry Aware Evaluation of 3D Object Detection and Pose Estimation in Scenes of Many Parts in Bulk
Jun 21, 2018



While 3D object detection and pose estimation has been studied for a long time, its evaluation is not yet completely satisfactory. Indeed, existing datasets typically consist in numerous acquisitions of only a few scenes because of the tediousness of pose annotation, and existing evaluation protocols cannot handle properly objects with symmetries. This work aims at addressing those two points. We first present automatic techniques to produce fully annotated RGBD data of many object instances in arbitrary poses, with which we produce a dataset of thousands of independent scenes of bulk parts composed of both real and synthetic images. We then propose a consistent evaluation methodology suitable for any rigid object, regardless of its symmetries. We illustrate it with two reference object detection and pose estimation methods on different objects, and show that incorporating symmetry considerations into pose estimation methods themselves can lead to significant performance gains. The proposed dataset is available at http://rbregier.github.io/dataset2017.
Defining the Pose of any 3D Rigid Object and an Associated Distance
Nov 29, 2017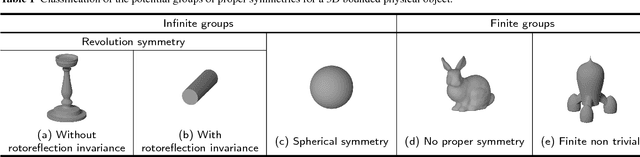
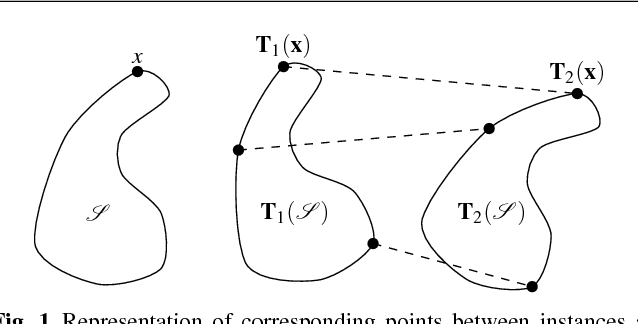

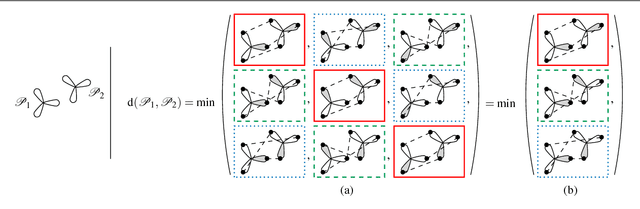
The pose of a rigid object is usually regarded as a rigid transformation, described by a translation and a rotation. However, equating the pose space with the space of rigid transformations is in general abusive, as it does not account for objects with proper symmetries -- which are common among man-made objects.In this article, we define pose as a distinguishable static state of an object, and equate a pose with a set of rigid transformations. Based solely on geometric considerations, we propose a frame-invariant metric on the space of possible poses, valid for any physical rigid object, and requiring no arbitrary tuning. This distance can be evaluated efficiently using a representation of poses within an Euclidean space of at most 12 dimensions depending on the object's symmetries. This makes it possible to efficiently perform neighborhood queries such as radius searches or k-nearest neighbor searches within a large set of poses using off-the-shelf methods. Pose averaging considering this metric can similarly be performed easily, using a projection function from the Euclidean space onto the pose space. The practical value of those theoretical developments is illustrated with an application of pose estimation of instances of a 3D rigid object given an input depth map, via a Mean Shift procedure.
Stereoscopic Cinema
Jun 19, 2015



Stereoscopic cinema has seen a surge of activity in recent years, and for the first time all of the major Hollywood studios released 3-D movies in 2009. This is happening alongside the adoption of 3-D technology for sports broadcasting, and the arrival of 3-D TVs for the home. Two previous attempts to introduce 3-D cinema in the 1950s and the 1980s failed because the contemporary technology was immature and resulted in viewer discomfort. But current technologies -- such as accurately-adjustable 3-D camera rigs with onboard computers to automatically inform a camera operator of inappropriate stereoscopic shots, digital processing for post-shooting rectification of the 3-D imagery, digital projectors for accurate positioning of the two stereo projections on the cinema screen, and polarized silver screens to reduce cross-talk between the viewers left- and right-eyes -- mean that the viewer experience is at a much higher level of quality than in the past. Even so, creation of stereoscopic cinema is an open, active research area, and there are many challenges from acquisition to post-production to automatic adaptation for different-sized display. This chapter describes the current state-of-the-art in stereoscopic cinema, and directions of future work.