 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring VQ-VAE with Prosody Parameters for Speaker Anonymization
Paper and Code
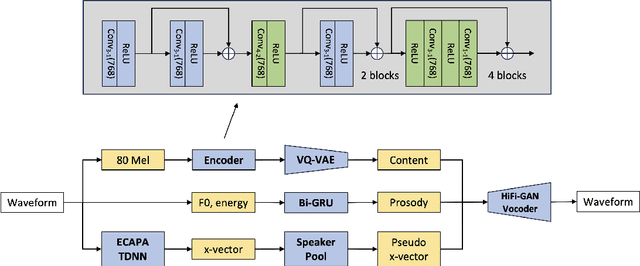

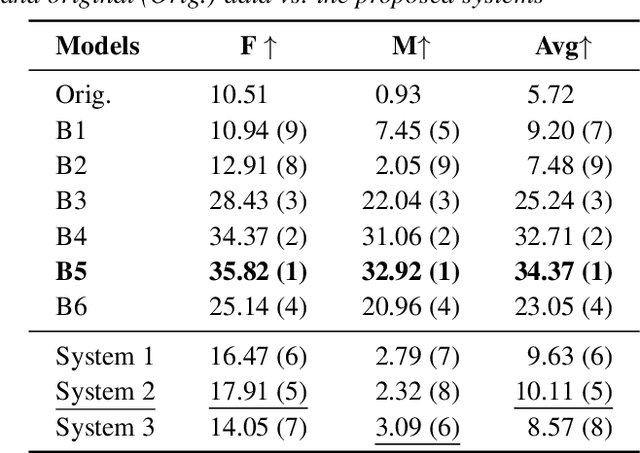
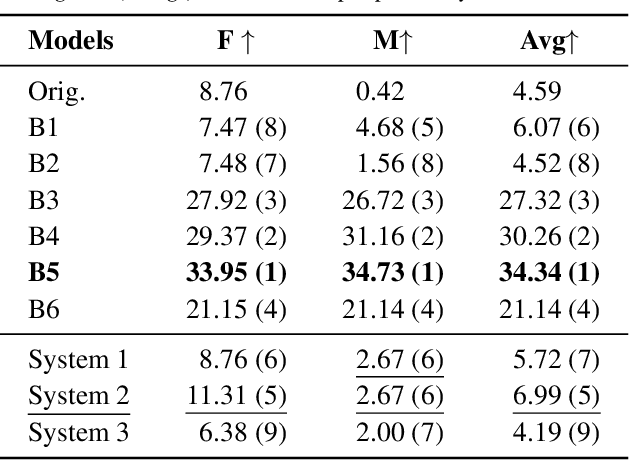
Human speech conveys prosody, linguistic content, and speaker identity. This article investigates a novel speaker anonymization approach using an end-to-end network based on a Vector-Quantized Variational Auto-Encoder (VQ-VAE) to deal with these speech components. This approach is designed to disentangle these components to specifically target and modify the speaker identity while preserving the linguistic and emotionalcontent. To do so, three separate branches compute embeddings for content, prosody, and speaker identity respectively. During synthesis, taking these embeddings, the decoder of the proposed architecture is conditioned on both speaker and prosody information, allowing for capturing more nuanced emotional states and precise adjustments to speaker identification. Findings indicate that this method outperforms most baseline techniques in preserving emotional information. However, it exhibits more limited performance on other voice privacy tasks, emphasizing the need for further improvements.