 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring VQ-VAE with Prosody Parameters for Speaker Anonymization
Sep 24, 2024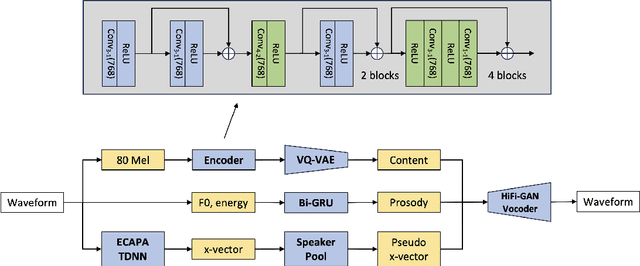

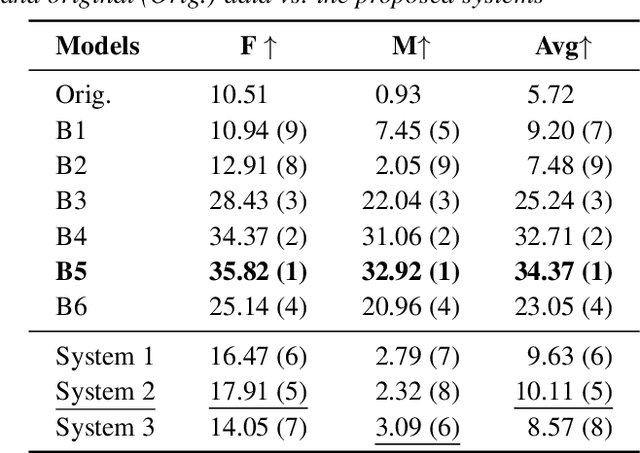
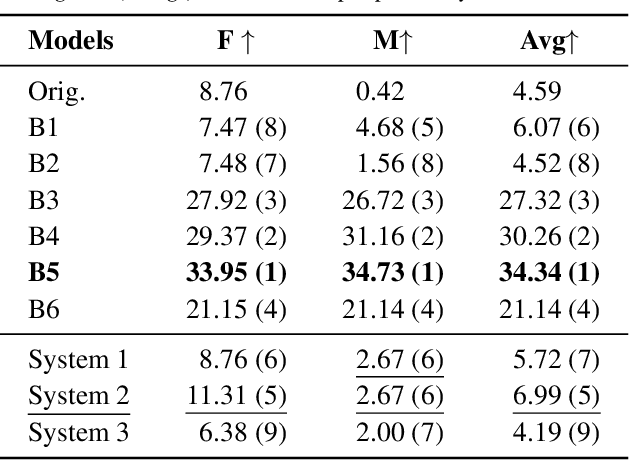
Human speech conveys prosody, linguistic content, and speaker identity. This article investigates a novel speaker anonymization approach using an end-to-end network based on a Vector-Quantized Variational Auto-Encoder (VQ-VAE) to deal with these speech components. This approach is designed to disentangle these components to specifically target and modify the speaker identity while preserving the linguistic and emotionalcontent. To do so, three separate branches compute embeddings for content, prosody, and speaker identity respectively. During synthesis, taking these embeddings, the decoder of the proposed architecture is conditioned on both speaker and prosody information, allowing for capturing more nuanced emotional states and precise adjustments to speaker identification. Findings indicate that this method outperforms most baseline techniques in preserving emotional information. However, it exhibits more limited performance on other voice privacy tasks, emphasizing the need for further improvements.
Preliminary Study on SSCF-derived Polar Coordinate for ASR
Nov 30, 2022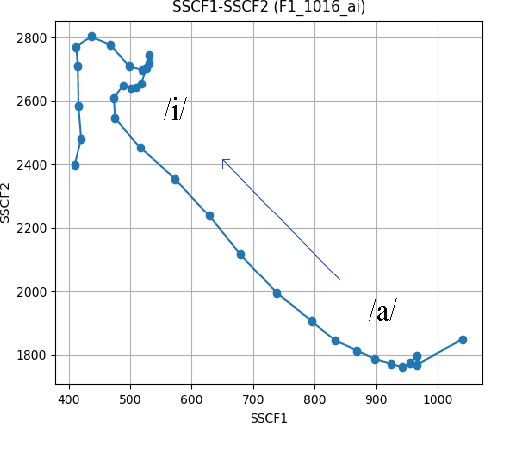

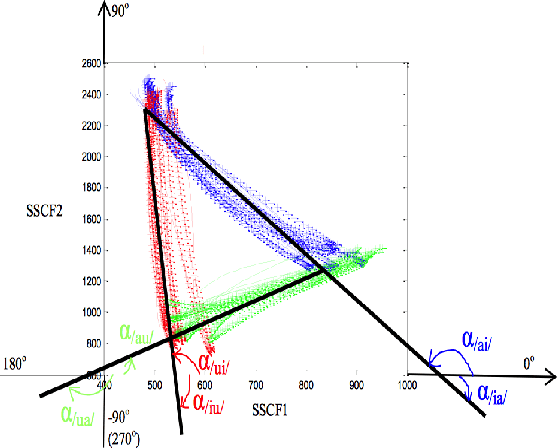

The transition angles are defined to describe the vowel-to-vowel transitions in the acoustic space of the Spectral Subband Centroids, and the findings show that they are similar among speakers and speaking rates. In this paper, we propose to investigate the usage of polar coordinates in favor of angles to describe a speech signal by characterizing its acoustic trajectory and using them in Automatic Speech Recognition. According to the experimental results evaluated on the BRAF100 dataset, the polar coordinates achieved significantly higher accuracy than the angles in the mixed and cross-gender speech recognitions, demonstrating that these representations are superior at defining the acoustic trajectory of the speech signal. Furthermore, the accuracy was significantly improved when they were utilized with their first and second-order derivatives ($\Delta$, $\Delta$$\Delta$), especially in cross-female recognition. However, the results showed they were not much more gender-independent than the conventional Mel-frequency Cepstral Coefficients (MFCCs).