 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Path Structural Encoding for Graph Transformers
Feb 13, 2025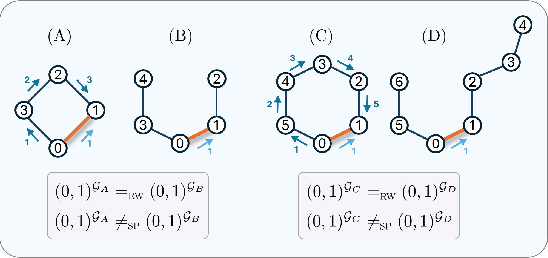
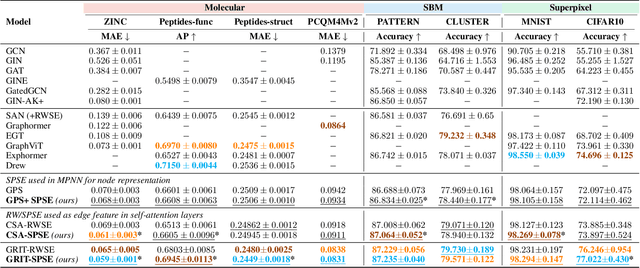
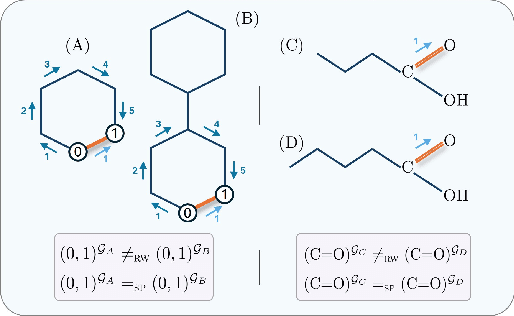
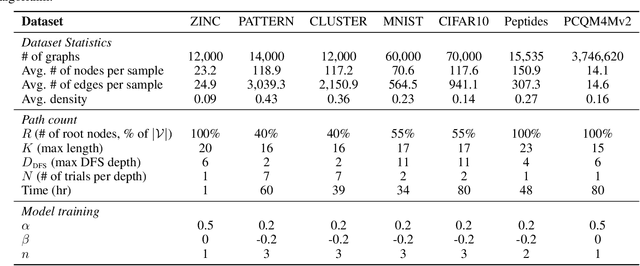
Graph transformers extend global self-attention to graph-structured data, achieving notable success in graph learning. Recently, random walk structural encoding (RWSE) has been found to further enhance their predictive power by encoding both structural and positional information into the edge representation. However, RWSE cannot always distinguish between edges that belong to different local graph patterns, which reduces its ability to capture the full structural complexity of graphs. This work introduces Simple Path Structural Encoding (SPSE), a novel method that utilizes simple path counts for edge encoding. We show theoretically and experimentally that SPSE overcomes the limitations of RWSE, providing a richer representation of graph structures, particularly for capturing local cyclic patterns. To make SPSE computationally tractable, we propose an efficient approximate algorithm for simple path counting. SPSE demonstrates significant performance improvements over RWSE on various benchmarks, including molecular and long-range graph datasets, achieving statistically significant gains in discriminative tasks. These results pose SPSE as a powerful edge encoding alternative for enhancing the expressivity of graph transformers.
NBM: an Open Dataset for the Acoustic Monitoring of Nocturnal Migratory Birds in Europe
Dec 04, 2024The persisting threats on migratory bird populations highlights the urgent need for effective monitoring techniques that could assist in their conservation. Among these, passive acoustic monitoring is an essential tool, particularly for nocturnal migratory species that are difficult to track otherwise. This work presents the Nocturnal Bird Migration (NBM) dataset, a collection of 13,359 annotated vocalizations from 117 species of the Western Palearctic. The dataset includes precise time and frequency annotations, gathered by dozens of bird enthusiasts across France, enabling novel downstream acoustic analysis. In particular, we demonstrate that a two-stage object detection model, tailored for the processing of audio data, can be trained on our dataset to retrieve localized bounding box coordinates around each signal of interest in a spectrogram. This object detection approach, which is largely overlooked in the bird sound recognition literature, allows important applications by potentially differentiating individual birds within audio windows. Further, we show that the accuracy of our recognition model on the 45 main species of the dataset competes with state-of-the-art systems trained on much larger datasets. This highlights the interest of fostering similar open-science initiatives to acquire costly but valuable fine-grained annotations of audio files. All data and code are made openly available.
A Comprehensive Multi-scale Approach for Speech and Dynamics Synchrony in Talking Head Generation
Jul 04, 2023



Animating still face images with deep generative models using a speech input signal is an active research topic and has seen important recent progress. However, much of the effort has been put into lip syncing and rendering quality while the generation of natural head motion, let alone the audio-visual correlation between head motion and speech, has often been neglected. In this work, we propose a multi-scale audio-visual synchrony loss and a multi-scale autoregressive GAN to better handle short and long-term correlation between speech and the dynamics of the head and lips. In particular, we train a stack of syncer models on multimodal input pyramids and use these models as guidance in a multi-scale generator network to produce audio-aligned motion unfolding over diverse time scales. Our generator operates in the facial landmark domain, which is a standard low-dimensional head representation. The experiments show significant improvements over the state of the art in head motion dynamics quality and in multi-scale audio-visual synchrony both in the landmark domain and in the image domain.
Autoregressive GAN for Semantic Unconditional Head Motion Generation
Nov 02, 2022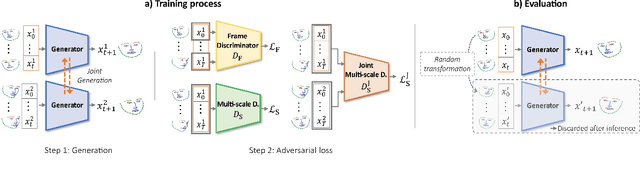



We address the task of unconditional head motion generation to animate still human faces in a low-dimensional semantic space.Deviating from talking head generation conditioned on audio that seldom puts emphasis on realistic head motions, we devise a GAN-based architecture that allows obtaining rich head motion sequences while avoiding known caveats associated with GANs.Namely, the autoregressive generation of incremental outputs ensures smooth trajectories, while a multi-scale discriminator on input pairs drives generation toward better handling of high and low frequency signals and less mode collapse.We demonstrate experimentally the relevance of the proposed architecture and compare with models that showed state-of-the-art performances on similar tasks.
SocialInteractionGAN: Multi-person Interaction Sequence Generation
Mar 10, 2021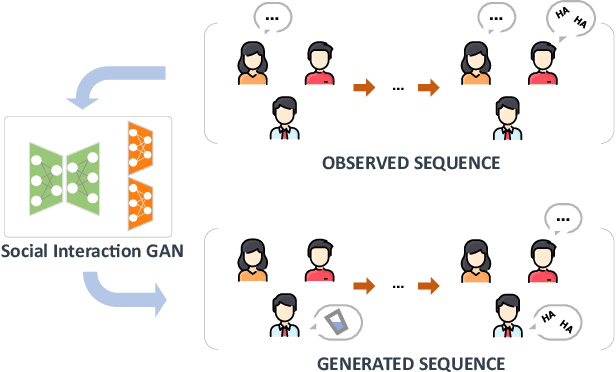
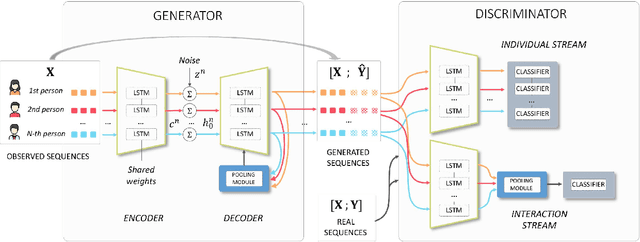
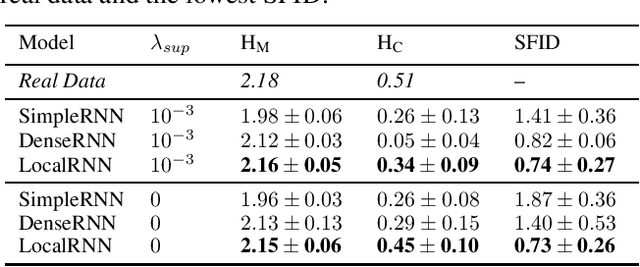
Prediction of human actions in social interactions has important applications in the design of social robots or artificial avatars. In this paper, we model human interaction generation as a discrete multi-sequence generation problem and present SocialInteractionGAN, a novel adversarial architecture for conditional interaction generation. Our model builds on a recurrent encoder-decoder generator network and a dual-stream discriminator. This architecture allows the discriminator to jointly assess the realism of interactions and that of individual action sequences. Within each stream a recurrent network operating on short subsequences endows the output signal with local assessments, better guiding the forthcoming generation. Crucially, contextual information on interacting participants is shared among agents and reinjected in both the generation and the discriminator evaluation processes. We show that the proposed SocialInteractionGAN succeeds in producing high realism action sequences of interacting people, comparing favorably to a diversity of recurrent and convolutional discriminator baselines. Evaluations are conducted using modified Inception Score and Fr{\'e}chet Inception Distance metrics, that we specifically design for discrete sequential generated data. The distribution of generated sequences is shown to approach closely that of real data. In particular our model properly learns the dynamics of interaction sequences, while exploiting the full range of actions.