 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Group Emotion Recognition In-the-wild Using Privacy-Compliant Features
Paper and Code
Dec 06, 2023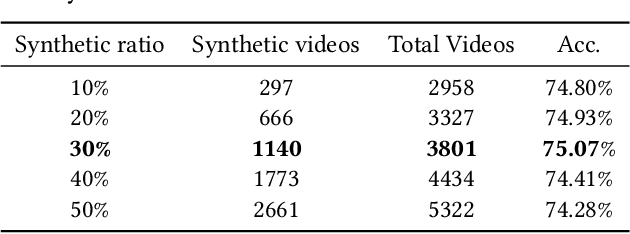
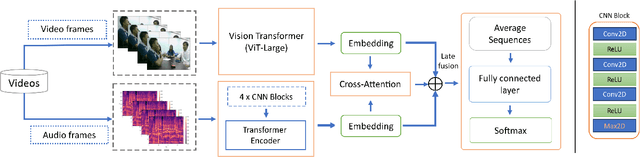
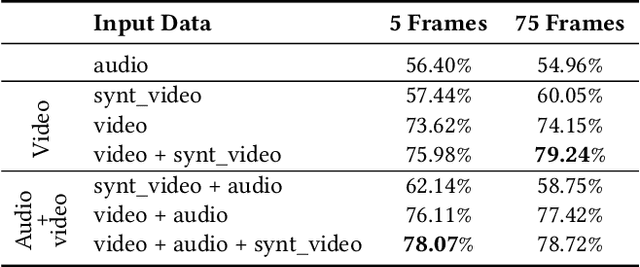

This paper explores privacy-compliant group-level emotion recognition ''in-the-wild'' within the EmotiW Challenge 2023. Group-level emotion recognition can be useful in many fields including social robotics, conversational agents, e-coaching and learning analytics. This research imposes itself using only global features avoiding individual ones, i.e. all features that can be used to identify or track people in videos (facial landmarks, body poses, audio diarization, etc.). The proposed multimodal model is composed of a video and an audio branches with a cross-attention between modalities. The video branch is based on a fine-tuned ViT architecture. The audio branch extracts Mel-spectrograms and feed them through CNN blocks into a transformer encoder. Our training paradigm includes a generated synthetic dataset to increase the sensitivity of our model on facial expression within the image in a data-driven way. The extensive experiments show the significance of our methodology. Our privacy-compliant proposal performs fairly on the EmotiW challenge, with 79.24% and 75.13% of accuracy respectively on validation and test set for the best models. Noticeably, our findings highlight that it is possible to reach this accuracy level with privacy-compliant features using only 5 frames uniformly distributed on the video.