 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOP: Evaluating the Comprehension Process of Large Language Models from a Cognitive View
Jun 05, 2025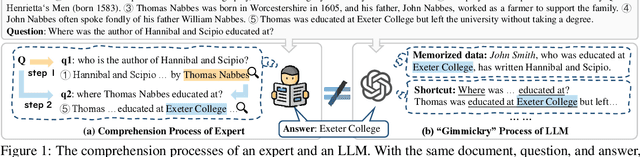

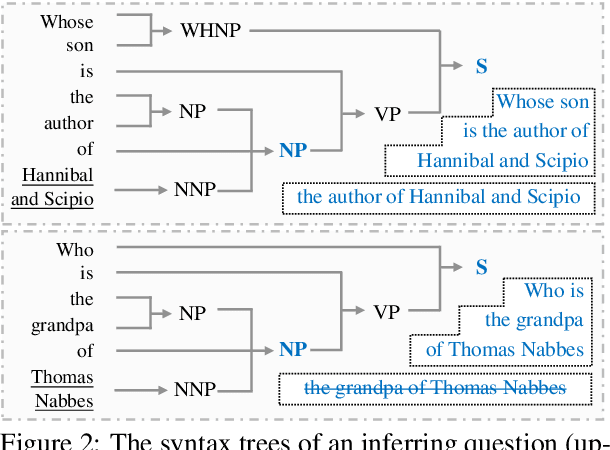

Despite the great potential of large language models(LLMs) in machine comprehension, it is still disturbing to fully count on them in real-world scenarios. This is probably because there is no rational explanation for whether the comprehension process of LLMs is aligned with that of experts. In this paper, we propose SCOP to carefully examine how LLMs perform during the comprehension process from a cognitive view. Specifically, it is equipped with a systematical definition of five requisite skills during the comprehension process, a strict framework to construct testing data for these skills, and a detailed analysis of advanced open-sourced and closed-sourced LLMs using the testing data. With SCOP, we find that it is still challenging for LLMs to perform an expert-level comprehension process. Even so, we notice that LLMs share some similarities with experts, e.g., performing better at comprehending local information than global information. Further analysis reveals that LLMs can be somewhat unreliable -- they might reach correct answers through flawed comprehension processes. Based on SCOP, we suggest that one direction for improving LLMs is to focus more on the comprehension process, ensuring all comprehension skills are thoroughly developed during training.
BAR: A Backward Reasoning based Agent for Complex Minecraft Tasks
May 20, 2025



Large language model (LLM) based agents have shown great potential in following human instructions and automatically completing various tasks. To complete a task, the agent needs to decompose it into easily executed steps by planning. Existing studies mainly conduct the planning by inferring what steps should be executed next starting from the agent's initial state. However, this forward reasoning paradigm doesn't work well for complex tasks. We propose to study this issue in Minecraft, a virtual environment that simulates complex tasks based on real-world scenarios. We believe that the failure of forward reasoning is caused by the big perception gap between the agent's initial state and task goal. To this end, we leverage backward reasoning and make the planning starting from the terminal state, which can directly achieve the task goal in one step. Specifically, we design a BAckward Reasoning based agent (BAR). It is equipped with a recursive goal decomposition module, a state consistency maintaining module and a stage memory module to make robust, consistent, and efficient planning starting from the terminal state. Experimental results demonstrate the superiority of BAR over existing methods and the effectiveness of proposed modules.
Listen to the Patient: Enhancing Medical Dialogue Generation with Patient Hallucination Detection and Mitigation
Oct 08, 2024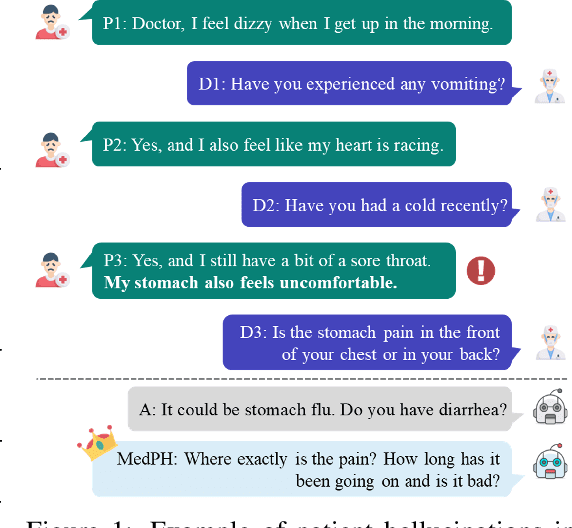
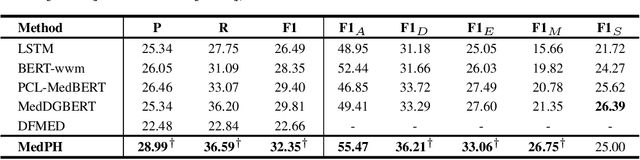
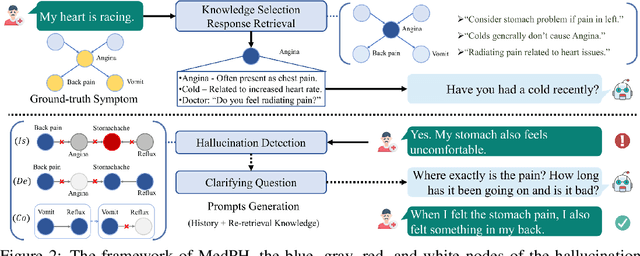
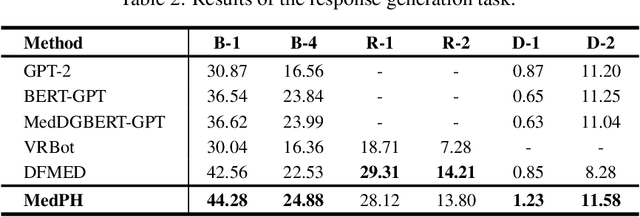
Medical dialogue systems aim to provide medical services through patient-agent conversations. Previous methods typically regard patients as ideal users, focusing mainly on common challenges in dialogue systems, while neglecting the potential biases or misconceptions that might be introduced by real patients, who are typically non-experts. This study investigates the discrepancy between patients' expressions during medical consultations and their actual health conditions, defined as patient hallucination. Such phenomena often arise from patients' lack of knowledge and comprehension, concerns, and anxieties, resulting in the transmission of inaccurate or wrong information during consultations. To address this issue, we propose MedPH, a Medical dialogue generation method for mitigating the problem of Patient Hallucinations designed to detect and cope with hallucinations. MedPH incorporates a detection method that utilizes one-dimensional structural entropy over a temporal dialogue entity graph, and a mitigation strategy based on hallucination-related information to guide patients in expressing their actual conditions. Experimental results indicate the high effectiveness of MedPH when compared to existing approaches in both medical entity prediction and response generation tasks, while also demonstrating its effectiveness in mitigating hallucinations within interactive scenarios.
PAGED: A Benchmark for Procedural Graphs Extraction from Documents
Aug 07, 2024



Automatic extraction of procedural graphs from documents creates a low-cost way for users to easily understand a complex procedure by skimming visual graphs. Despite the progress in recent studies, it remains unanswered: whether the existing studies have well solved this task (Q1) and whether the emerging large language models (LLMs) can bring new opportunities to this task (Q2). To this end, we propose a new benchmark PAGED, equipped with a large high-quality dataset and standard evaluations. It investigates five state-of-the-art baselines, revealing that they fail to extract optimal procedural graphs well because of their heavy reliance on hand-written rules and limited available data. We further involve three advanced LLMs in PAGED and enhance them with a novel self-refine strategy. The results point out the advantages of LLMs in identifying textual elements and their gaps in building logical structures. We hope PAGED can serve as a major landmark for automatic procedural graph extraction and the investigations in PAGED can offer insights into the research on logic reasoning among non-sequential elements.
CARE: A Clue-guided Assistant for CSRs to Read User Manuals
Aug 07, 2024



It is time-saving to build a reading assistant for customer service representations (CSRs) when reading user manuals, especially information-rich ones. Current solutions don't fit the online custom service scenarios well due to the lack of attention to user questions and possible responses. Hence, we propose to develop a time-saving and careful reading assistant for CSRs, named CARE. It can help the CSRs quickly find proper responses from the user manuals via explicit clue chains. Specifically, each of the clue chains is formed by inferring over the user manuals, starting from the question clue aligned with the user question and ending at a possible response. To overcome the shortage of supervised data, we adopt the self-supervised strategy for model learning. The offline experiment shows that CARE is efficient in automatically inferring accurate responses from the user manual. The online experiment further demonstrates the superiority of CARE to reduce CSRs' reading burden and keep high service quality, in particular with >35% decrease in time spent and keeping a >0.75 ICC score.
CLAMBER: A Benchmark of Identifying and Clarifying Ambiguous Information Needs in Large Language Models
May 20, 2024



Large language models (LLMs) are increasingly used to meet user information needs, but their effectiveness in dealing with user queries that contain various types of ambiguity remains unknown, ultimately risking user trust and satisfaction. To this end, we introduce CLAMBER, a benchmark for evaluating LLMs using a well-organized taxonomy. Building upon the taxonomy, we construct ~12K high-quality data to assess the strengths, weaknesses, and potential risks of various off-the-shelf LLMs. Our findings indicate the limited practical utility of current LLMs in identifying and clarifying ambiguous user queries, even enhanced by chain-of-thought (CoT) and few-shot prompting. These techniques may result in overconfidence in LLMs and yield only marginal enhancements in identifying ambiguity. Furthermore, current LLMs fall short in generating high-quality clarifying questions due to a lack of conflict resolution and inaccurate utilization of inherent knowledge. In this paper, CLAMBER presents a guidance and promotes further research on proactive and trustworthy LLMs. Our dataset is available at https://github.com/zt991211/CLAMBER
Strength Lies in Differences! Towards Effective Non-collaborative Dialogues via Tailored Strategy Planning
Mar 11, 2024



We investigate non-collaborative dialogue agents that must engage in tailored strategic planning for diverse users to secure a favorable agreement. This poses challenges for existing dialogue agents due to two main reasons: their inability to integrate user-specific characteristics into their strategic planning and their training paradigm's failure to produce strategic planners that can generalize to diverse users. To address these challenges, we propose TRIP to enhance the capability in tailored strategic planning, incorporating a user-aware strategic planning module and a population-based training paradigm. Through experiments on benchmark non-collaborative dialogue tasks, we demonstrate the effectiveness of TRIP in catering to diverse users.
Well Begun is Half Done: Generator-agnostic Knowledge Pre-Selection for Knowledge-Grounded Dialogue
Oct 20, 2023



Accurate knowledge selection is critical in knowledge-grounded dialogue systems. Towards a closer look at it, we offer a novel perspective to organize existing literature, i.e., knowledge selection coupled with, after, and before generation. We focus on the third under-explored category of study, which can not only select knowledge accurately in advance, but has the advantage to reduce the learning, adjustment, and interpretation burden of subsequent response generation models, especially LLMs. We propose GATE, a generator-agnostic knowledge selection method, to prepare knowledge for subsequent response generation models by selecting context-related knowledge among different knowledge structures and variable knowledge requirements. Experimental results demonstrate the superiority of GATE, and indicate that knowledge selection before generation is a lightweight yet effective way to facilitate LLMs (e.g., ChatGPT) to generate more informative responses.
DiVa: An Iterative Framework to Harvest More Diverse and Valid Labels from User Comments for Music
Aug 09, 2023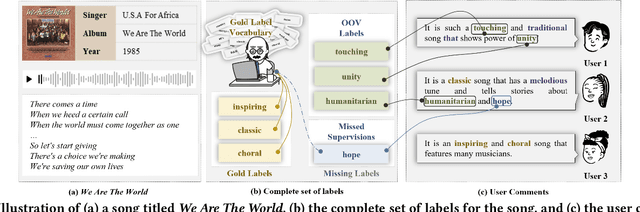

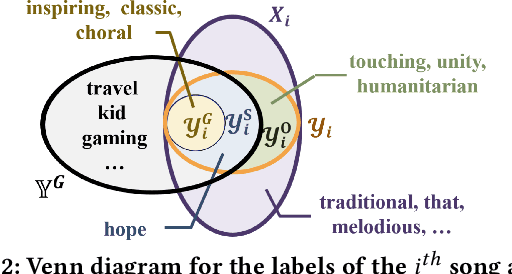
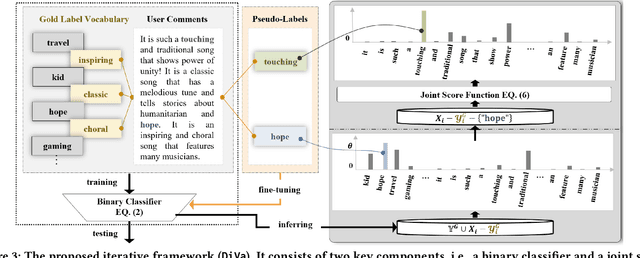
Towards sufficient music searching, it is vital to form a complete set of labels for each song. However, current solutions fail to resolve it as they cannot produce diverse enough mappings to make up for the information missed by the gold labels. Based on the observation that such missing information may already be presented in user comments, we propose to study the automated music labeling in an essential but under-explored setting, where the model is required to harvest more diverse and valid labels from the users' comments given limited gold labels. To this end, we design an iterative framework (DiVa) to harvest more $\underline{\text{Di}}$verse and $\underline{\text{Va}}$lid labels from user comments for music. The framework makes a classifier able to form complete sets of labels for songs via pseudo-labels inferred from pre-trained classifiers and a novel joint score function. The experiment on a densely annotated testing set reveals the superiority of the Diva over state-of-the-art solutions in producing more diverse labels missed by the gold labels. We hope our work can inspire future research on automated music labeling.
Knowing-how & Knowing-that: A New Task for Machine Reading Comprehension of User Manuals
Jun 07, 2023



The machine reading comprehension (MRC) of user manuals has huge potential in customer service. However,current methods have trouble answering complex questions. Therefore, we introduce the Knowing-how & Knowing-that task that requires the model to answer factoid-style, procedure-style, and inconsistent questions about user manuals. We resolve this task by jointly representing the steps and facts in a graph (TARA), which supports a unified inference of various questions. Towards a systematical benchmarking study, we design a heuristic method to automatically parse user manuals into TARAs and build an annotated dataset to test the model's ability in answering real-world questions. Empirical results demonstrate that representing user manuals as TARAs is a desired solution for the MRC of user manuals. An in-depth investigation of TARA further sheds light on the issues and broader impacts of future representations of user manuals. We hope our work can move the MRC of user manuals to a more complex and realistic stage.